
- 1浅谈uniapp_uniapp destroyed
- 2前端之样式列表_前端列表样式
- 3mysql的两种存储引擎_Mysql的两种存储引擎以及区别
- 4教你体验目前最火AI - 在craft AI assistant使用AI助手
- 5第三方录像机添加宇视摄像机配置指导_vsd摄像机加入宇视录像机
- 6Nacos 注册中心 这次终于搞懂了!_nacos注册中心
- 7创建多节点 k8s 集群
- 8MacOS 配置VSCode C/C++ 开发和环境_c++ macos
- 9宝兰德应用服务器软件与华为云GaussDB完成兼容互认证_宝兰德bca认证
- 10读取并修改yml文件中mybatis中数据库连接设置_mybatis读取yml文件
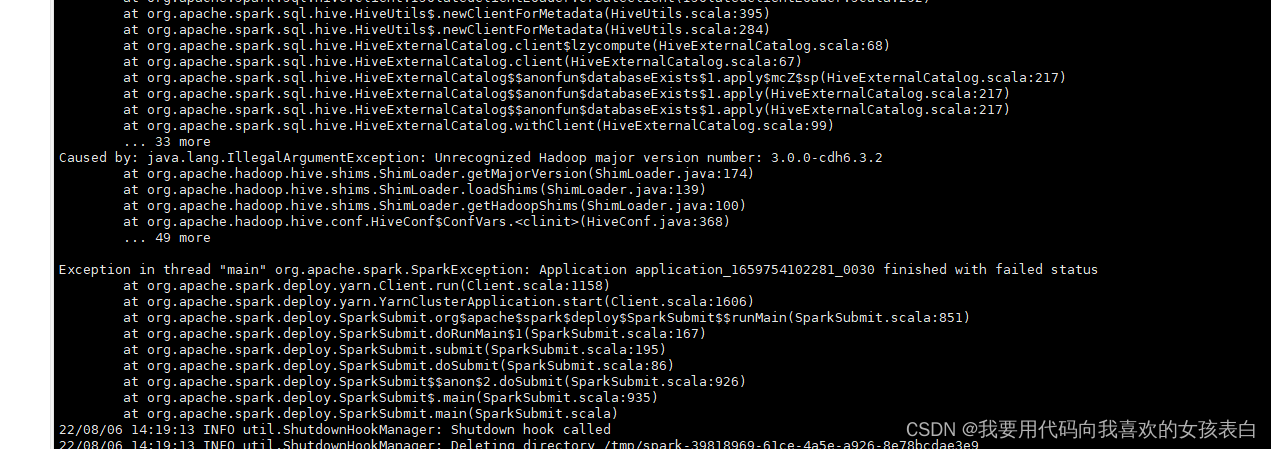
spark 集群启动出现 Unrecognized Hadoop major version number: 3.0.0-cdh6.3.2
赞
踩
我是cdh集群,如果你不是cdh6.3以上,你可以走了
这是我的pom,我现在在本地往hive写数据,没问题,但是,如果打成jar包,放到服务器上,执行就有问题
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
- <maven.compiler.source>1.8</maven.compiler.source>
- <maven.compiler.target>1.8</maven.compiler.target>
-
- <scala.version>2.11.12</scala.version>
- <spark.version>2.4.0</spark.version>
- <java.version>1.8</java.version>
-
- </properties>
- <groupId>org.example</groupId>
- <artifactId>DataPrepare</artifactId>
- <version>1.0-SNAPSHOT</version>
- <dependencies>
- <!--scala-->
- <dependency>
- <groupId>org.scala-lang</groupId>
- <artifactId>scala-library</artifactId>
- <version>${scala.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.11</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_2.11</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.11</artifactId>
- <version>${spark.version}</version>
- </dependency>
-
- </dependencies>
-
- <build>
- <finalName>WordCount</finalName>
- <plugins>
- <plugin>
- <groupId>net.alchim31.maven</groupId>
- <artifactId>scala-maven-plugin</artifactId>
- <version>3.2.2</version>
- <executions>
- <execution>
- <goals>
- <goal>compile</goal>
- <goal>testCompile</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-assembly-plugin</artifactId>
- <version>3.0.0</version>
- <configuration>
- <archive>
- <manifest>
- <mainClass>WordCount</mainClass>
- </manifest>
- </archive>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
-
- </project>

后来了解到,只有在用代码集成hive-jdbc,spark-core,spark-sql,spark-hive等依赖的时候,就会报出这么一个问题。
spark-hive.jar包和spark2.4有冲突,这个是一个社区问题,不是你的问题。
本地,idea运行时,需要有这个spark-hive,但是你上传到集群交给,yarn去执行每台机器的spark就必须把他注释掉。
解决方案:丢到集群的时候,注释掉,在进行打包
- <!--<dependency>-->
- <!--<groupId>org.apache.spark</groupId>-->
- <!--<artifactId>spark-hive_2.11</artifactId>-->
- <!--<version>${spark.version}</version>-->
- <!--</dependency>
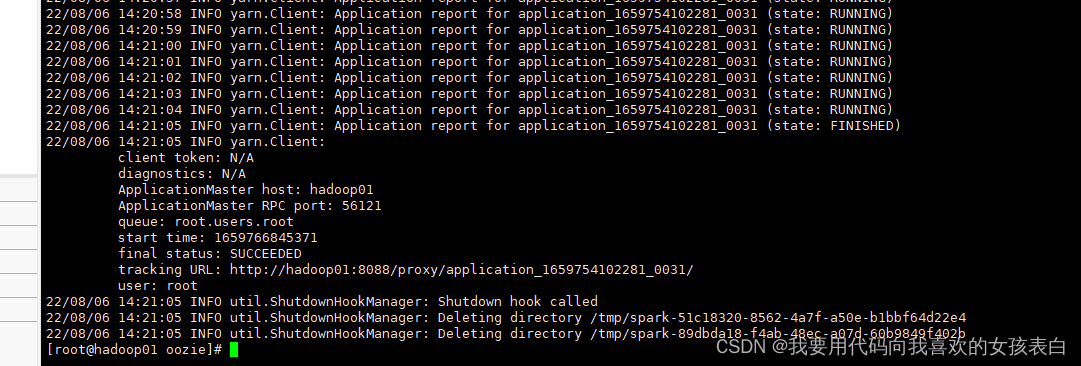
成功
参考:
这篇文章非常清楚,从原理上说明了这个问题
Spark运行CDH6.3.2碰到的由于hive驱动引起的问题解决方法
原文:
一、概述
spark使用hive中有比较多的坑,尤其是版本问题引起的jar包冲突,比较好的方式是使用与CDH匹配的hive和hadoop版本,这样可以减少很多的jar冲突问题,但是在IDEA调试过程中还是难免会碰到jar包冲突问题。
二、CDH6.3.2中碰到问题解决方法
1、java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
这个问题,基本发生在远程启动spark客户端,并且访问spark集群,然后再连接hive造成的。因为,无论升级到spark的什么版本,用hive的什么版本,在集群环境下直接启动spark-sql或者spark-shell访问hive都不会发生这个问题。只有在用代码集成hive-jdbc,spark-core,spark-sql,spark-hive等依赖的时候,就会报出这么一个问题。
导致这个问题的原因如下:用代码启动spark,并且连接spark standalone 或者yarn模式spark-client方式的时候,本地机器会成为driver,diver负责向hive通信。代码在通信的过程中,需要依赖hive相关的jar包。在连接hive之前,spark会进行一下连接相关参数的检查,检查的参数来自于hive的jar包,其中就有这么一个:HIVE_STATS_JDBC_TIMEOUT。然而,spark集群下面依赖的hive的jar包还是1.2.1版本的,所以集群模式连接hive没有问题。然后hive升级到了2之后的版本,hive去掉了这个参数(大家可以现在去spark的github上面看看最新的代码,里面已经做了相关修改,但是命名还是:hardcode。),然后spark-sql里面的代码依然是要调用hive的这个参数的,然后就报错了。
这个问题在jira上说加上 spark.sql.hive.metastore.jars spark.sql.hive.metastore.version这两个参数(当然这两个参数还是要加的),然后这两个参数并不能解决这个问题,因为在用到这两个jar包之前,spark就已经对连接hive参数进行了检测。
所以最终解决办法是:在spark 2.4.4的代码中,删除掉HIVE_STATS_JDBC_TIMEOUT以及另外一个参数,然后重新编译spark-hive的jar包。再 将此jar包替换现有的spark-hive的jar包。
如果你不想重新编译spark源码包,可以现在本地使用较低版本的hive和hadoop驱动包,调试成功后将spark-hive_2.11的pom中依赖删除,直接使用集群中的jars中的包即可。
2、Unrecognized Hadoop major version number: 3.0.0
这是因为CDH6.3.2版本与你pom中设置hadoop版本不一致,换成3.0.0-cdh6.3.2版本就可以了。

