- 1【完全背包问题——附例题剖析】_全背包例题
- 2【JVM】类加载器_应用程序类加载器
- 3VSCode——Python必下的9种插件的使用感受!_vscodepython插件
- 4IPython 日志秘籍:%logstate 命令全解析
- 5【Golang】slice切片
- 6Python3 + Appium + 安卓模拟器实现APP自动化测试并生成测试报告_python android模拟器
- 7LVGL之GUI GUIder使用教程_lvgl界面编辑器
- 8encoder decoder模型_Pytorch学习记录-卷积Seq2Seq(模型实现)
- 9为什么很多公司都开始放弃 Oracle 而使用 MySQL?(1),2024年最新文末有彩蛋_oracle mysql
- 10electron+vue编辑Office Word?_猿大师办公助手
Python中常用模块(2)---文件的读写_python readlines
赞
踩
3、文件读写
3.1、open函数
3.1.1、open函数的完整语法格式
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)3.1.2、参数说明
| 参数名 | 表示含义 |
| file | 必选,文件路径(相对或绝对路径) |
| mode | 可选,文件打开模式,默认是‘r’;’r’以只读打开文件,’w’只写入;’a’在文件后追加(文件已存在);文件不存在时,创建并写入文件; |
| buffering | 设置缓冲 |
| encoding | 一般使用UTF-8 |
| errors | 报错级别 |
| newline | 区分换行符 |
| closefd | 传入file参数类型 |
3.1.3、文件常见操作
| 方法 | 描述 |
| file.read([size]) | 从文件中读取指定的字节数,如果未给定或为负则读取所有 |
| file.readline([size]) | 读取整行;size表示读取第一行多少字符; |
| file.readlines([sizeint]) | 读取所有行,并返回列表;若给定sizeint>0则只读取第一行字符,且带‘\n’,也以列表格式输出; |
| file.write(str) | 将字符串写入文件,返回的是写入的字符串的长度 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符 |
| file.close() | 关闭文件;关闭文件后无法再进行读写操作; |
示例文件(打开1.txt文件),文件内容:
- 11111111
- 22222222
- 33333333
- 44444444
- 55555555
3.1.4、通过read读取全部内容
1、示例代码
- f = open('demo6/1.txt', 'r', encoding='utf-8')
- data1 = f.read()
- print(data1)
- f.close()
2、执行结果

3.1.5、通过readline读取文件某行内容
1、示例代码(不带参数默认只读第一行数据)
- f = open('demo6/1.txt', 'r', encoding='utf-8')
- data2 = f.readline()
- print(data2)
- f.close()
2、执行结果:

3、示例代码(带参数,例如带参数1,只读第一行的第一个字符;带的参数等于或者超过第一行字符长度,则输出第一行字符)
- f = open('demo6/1.txt', 'r', encoding='utf-8')
- data2 = f.readline(3)
- print(data2)
- f.close()
4、执行结果:
3.1.6、通过readlines读取文件全部内容,返回列表
1、示例代码:(默认不带参数或者参数为0时,读取文件所有内容,以列表输出)
- f = open('demo6/1.txt', 'r', encoding='utf-8')
- data2 = f.readlines()
- print(data2)
- f.close()
2、执行结果:

3、示例代码:(默认不带参数或者参数>0时,读取文件的第一行且携带‘\n’,以列表输出)
- f = open('demo6/1.txt', 'r', encoding='utf-8')
- data2 = f.readlines(2)
- print(data2)
- f.close()
4、执行结果:

3.1.7、通过write写入数据
1、示例代码
- f = open('demo6/3.txt', 'w', encoding='utf-8')
- data = 'aaaaaaaa'
- data2 = f.write(data)
- f.close()
2、执行结果:
如果文件3.txt文件不存在,则创建一个3.txt的文件,并写入内容;
如果文件3.txt文件存在,且里面有内容,则覆盖3.txt文件的原内容,写入内容;
3.1.8、通过writelines将一个列表写入文件中
1、示例代码
- f = open('demo6/3.txt', 'w', encoding='utf-8')
- data = 'aaaaaaaa'
- data2 = f.write(data)
- f.close()
2、执行结果:
如果文件2.txt文件不存在,则创建一个2.txt的文件,并写入内容;
如果文件2.txt文件存在,且里面有内容,则覆盖2.txt文件的原内容,写入内容;
3、如果参数‘w’改成‘a+’则会在原文件追加继续写,不覆盖(注意追加的第一行和原文件的最后一行,如果没换行符则会也在一起)
3.2、JSON文件
3.1.1、JSON文件特点
- JSON是存储和交换文本信息的语法,类似XML;
- JSON比XML更小、更快、更易解析;
- JSON是轻量级的文本数据交换格式;
- JSON独立于语言;
- JSON具有自我描述性,更易理解;
3.1.2、JSON的语法规则
- JSON数据用大括号括起来;
- 数据在key:value 对中,名称和值用冒号隔开,类似python中的字典;
- 名称要用双引号引起来,值要更具数据类型来判断是否需要引起来;例:int数据就不需要,str类型就需要;
- 数据(一组key:value对)由逗号分隔;
3.1.3、JSON值类型
1、数字(整型或浮点) 如{‘age’: null}
2、字符串(在双引号中) 如{‘name’: ‘zsk’}
3、逻辑值(True or False) 如{‘flag’: True}
4、数组(在中括号中) 如{‘S’: [‘name’, ‘site’]}
5、对象(在大括号中) 如{‘N’: {‘num’: 100}}
6、null, 如{‘age’: null}
3.1.4、JSON模块功能
1、dumps
功能:将字典转成字符串
示例代码:
- import json
-
- dict1 = {'name':'zhangsan', 'age':18}
- print(dict1)
- print(type(dict1))
-
- # 转成字符串
- j1 = json.dumps(dict1)
- print(j1)
- print(type(j1))
执行结果
2、dump
功能:将字段转成字符串,并写入JSON文件中
示例代码:
- import json
-
- dict1 = {'name':'zhangsan', 'age':18}
- print(dict1)
- print(type(dict1))
-
- with open('222.txt', 'w') as f:
- j1 = json.dump(dict1, f)
- print(j1)
- print(type(j1))
执行结果:(生成文件222.txt,并把内容写了进来)
3、loads
功能:将字符串转成字典
示例代码({}里的key和value要用双引号引起来(value看值类型添加引号),单引号会报错)
- import json
-
- # {}里的key和value要用双引号引起来(value看值类型添加引号),单引号会报错
- str1 = '{"name":"zhangsan", "age":18}'
- print(str1)
- print(type(str1))
-
- # 将字符串转成字典
- dic = json.loads(str1)
- print(dic)
- print(type(dic))
执行结果
4、load
功能:把文件打开,并把字符串转换成数据类型
示例代码:
- import json
-
-
- with open('1.txt', 'r', encoding='utf-8') as f:
- # f = f.read()
- print(f)
- print(type(f))
- dic1 = json.load(f)
- print(dic1)
- print(type(dic1))
执行结果:

3.1.5、读取字典类型数据文件
1、json文件
- {
- "user1":{"name":"zhangsan1", "age":18},
- "user2":{"name":"zhangsan2", "age":20}
- }
2、示例代码:
- import json
-
- file = '2.json'
-
- with open(file, 'r') as f:
- users = json.load(f)
- print(type(f))
- print(type(users))
- print(users)
-
- for user in users:
- print(user)
- name = users[user]['name']
- age = users[user]['age']
- print(name, age)
3、执行结果:
3.1.6、读取列表类型数据文件
1、示例文件
- [
- {
- "name": "zhangsan1",
- "age": 18
- },
- {
- "name":"zhangsan2",
- "age":20
- }
- ]
2、示例代码:
- import json
-
- file = '2.json'
- with open(file, 'r') as f:
- ss = json.load(f)
- print(ss)
- print(type(ss))
-
-
- for s in ss:
- print(s)
- print(type(s))
- print(s['name'])
- print(s['age'])
3、执行结果:

3.3、YAML文件
3.3.1、YAML文件特点
特点:使用空白字符表示缩进,文件扩展名为“.yaml”;
3.3.2、YAML文件的语法规则
- 大小写敏感;
- 使用缩进表示层级关系;
- 缩进不能使用Tab键,只能用空白键;
- 缩进的空格数不重要,只要相同层级的元素左对齐即可;
- ‘#’表示注释;
3.3.3、YAML文件支持的数据类型
1、YAML对象
对象:键-值对的集合,又称为映射、哈希、字典;
2、YAML数组
数组:一组按次序排列的值,又称为序列、列表;
3、YAML文件--YAMl对象;
示例文件:(冒号前无空格,冒号后有一个空格)
- name: 'zhangsan'
- age: 10
示例代码:
- import yaml
-
- with open('1.yaml', 'r', encoding='UTF-8') as f:
- data = yaml.load(f, Loader=yaml.FullLoader)
- print(data)
- print(type(data))
- print(data['name'])
- print(data['age'])
执行结果:

4、YAML文件--YAMl数组
示例文件:
- - name
- - age
- - std_id
- - pag
示例代码:
- import yaml
-
- with open('2.yaml', 'r', encoding='UTF-8') as f:
- data = yaml.load(f, Loader=yaml.FullLoader)
- print(data)
- print(type(data))
执行结果:

5、YAML文件--复合结构
示例文件:
- school:
- name: zhangsan
- age: 18
- stu_id: 10223
示例代码:
- import yaml
-
- with open('3.yaml', 'r', encoding='UTF-8') as f:
- data = yaml.load(f, Loader=yaml.FullLoader)
- print(data)
- print(type(data))
- print(data['school'])
- print(type(data['school']))
- print(data['school']['name'])
- print(data['school']['age'])
- print(data['school']['stu_id'])
执行结果:

3.4、CSV文件
1、用Excel打开的话,会发现和‘.xls’和‘.xlsx’的文件一样,但是csv文件可以使用记事本打开;
2、示例文件:
- name,age,stu_id
- zhangsan,18,10234
- zhangsan2,19,10235
- zhangsan3,20,10236
3、示例代码:
- import csv
-
- with open('1.csv', 'r', encoding='utf-8') as f:
- data = csv.reader(f)
- print(data)
- for i in data:
- print(i)
4、执行结果:

5、把数据写入CSV文件
6、示例代码
- # -*- coding: gbk -*-
- import csv
-
-
-
- def Writer_CSV(title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value):
- file_name = './result_to_csv.csv'
- with open(file_name, 'a+', newline='') as csvfile:
- writer = csv.writer(csvfile)
- with open(file_name, 'r', newline='') as f:
- reader = csv.reader(f)
- # writer.writerow(['title1', 'title2', 'title3', 'title4', 'title5', 'title6', 'title7', 'title8'])
- # writer.writerow([title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value])
-
- #防止重复写入标题(如果首行为空,则把标题写入首行,在往下按行插入数据;如果首行不为空,则直接按行往下插入数据)
- if not [row for row in reader]:
- writer.writerow(['title1', 'title2', 'title3', 'title4', 'title5', 'title6', 'title7', 'title8'])
- writer.writerow([title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value])
- else:
- writer.writerow([title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value])
-
- f.close()
- csvfile.close()
-
-
- Writer_CSV(1, 2, 3, 4, 5, 6, 7, 8)

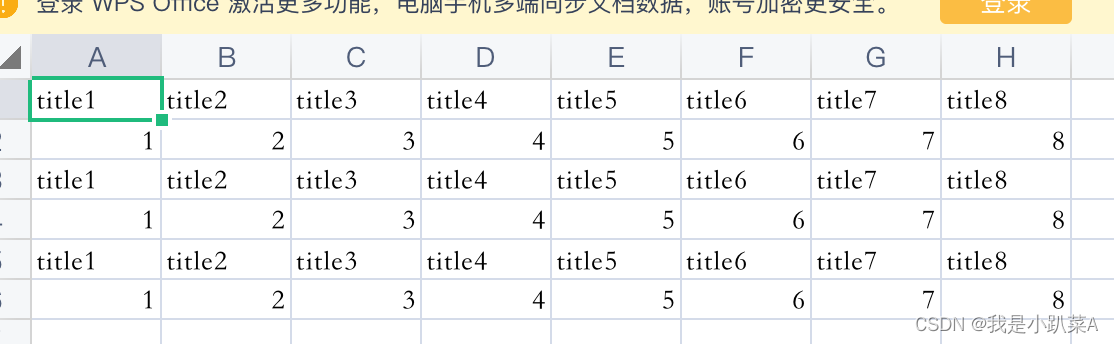
7、运行结果:
在当前目录下生成一个CSV文件:result_to_csv.csv;如果当前目录下已存在,则会在当前文件下追加数据写入;

8、 ”if not [row for row in reader]:“ 的作用:为了防止标题重复写入:
示例代码:
- # -*- coding: gbk -*-
- import csv
-
-
-
- def Writer_CSV(title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value):
- file_name = '/Users/lichuanwei/Project_Pytest/BUNDLE_Project/result_to_csv.csv'
- with open(file_name, 'a+', newline='') as csvfile:
- writer = csv.writer(csvfile)
- with open(file_name, 'r', newline='') as f:
- reader = csv.reader(f)
- writer.writerow(['title1', 'title2', 'title3', 'title4', 'title5', 'title6', 'title7', 'title8'])
- writer.writerow([title1_value, title2_value, title3_value, title4_value, title5_value, title6_value, title7_value, title8_value])
-
-
-
- f.close()
- csvfile.close()
-
-
- Writer_CSV(1, 2, 3, 4, 5, 6, 7, 8)
输出结果:标题重复写入