
热门标签
热门文章
- 1最新鲜最详细的Android SDK下载安装及配置教程_google下载sdk 需要的端口
- 2深入理解Java的接口和抽象类_设计飞的接口ifly,接口包含fly()方法。让鸟类bird和飞机类airplane实现这个接口。
- 3用python文本挖掘分析_文本挖掘和文本分析的九大应用场景
- 4人工智能入门实战:使用BERT模型进行文本分类_bert文本分类实战
- 5fiddler everyWhere 夜神 证书无效_夜神模拟器fiddler抓包 提示证书问题
- 6鸿蒙ArkTS实战开发:Worker_arkts worker使用
- 7Layui介绍(1)
- 8SpringBoot项目中org.junit.jupiter.api.Test报错-溯源分析_import org.junit.jupiter.api.test;
- 9为什么投了很多简历,却总是没有答复呢_招聘不更新了是好事还是恶性
- 10Debezium日常分享系列之:Debezium2.5稳定版本之数据类型映射_debezium jdk版本映射表
当前位置: article > 正文
Matlab:K-means算法_matlab kmeans
作者:weixin_40725706 | 2024-06-14 19:18:59
赞
踩
matlab kmeans
K-means算法是一种常见的聚类算法,它将一组数据划分为K个不同的簇,以最小化每个簇内部数据点与簇中心之间的平方距离的总和为目标实现聚类。
1、基本步骤:
1.选择要划分的簇数K;
2.选择K个数据点作为初始的聚类中心;
3.对于每个数据点,计算其与每个聚类中心之间的距离,并将数据点分配给距离最近的聚类中心;
4.更新每个簇的中心点,将其设置为该簇中所有数据点的平均值;
5.重复步骤3和步骤4,直到达到收敛条件(即簇中心不再发生变化或达到最大迭代次数);
6.得到K个簇,每个簇包含一组数据点。
2、算法结构:
- %K-means算法的函数定义,用于执行K-means聚类并返回结果
- function [Idx, Center] = K_means(X, xstart)
-
- len = length(X); %X中的数据点个数
- Idx = zeros(len, 1); %每个数据点的Id
-
- C1 = xstart(1,:); %第1类的中心位置
- C2 = xstart(2,:); %第2类的中心位置
- C3 = xstart(3,:); %第3类的中心位置
-
- for i_for = 1:100
- %为避免循环运行时间过长,通常设置一个循环次数
- %或相邻两次聚类中心位置调整幅度小于某阈值则停止
-
- %更新数据点属于哪个类
- for i = 1:len
- x_temp = X(i,:); %提取出单个数据点
- d1 = norm(x_temp - C1); %与第1个类的距离
- d2 = norm(x_temp - C2); %与第2个类的距离
- d3 = norm(x_temp - C3); %与第3个类的距离
- d = [d1;d2;d3];
- [~, id] = min(d); %离哪个类最近则属于那个类
- Idx(i) = id;
- end
-
- %更新类的中心位置
- L1 = X(Idx == 1,:); %属于第1类的数据点
- L2 = X(Idx == 2,:); %属于第2类的数据点
- L3 = X(Idx == 3,:); %属于第3类的数据点
- C1 = mean(L1); %更新第1类的中心位置
- C2 = mean(L2); %更新第2类的中心位置
- C3 = mean(L3); %更新第3类的中心位置
- end
-
- Center = [C1; C2; C3]; %类的中心位置
注:
(1)函数的输入参数为X和xstart,其中:
【1】X是一个包含数据点的矩阵,每一行代表一个数据点的特征向量;
【2】xstart是一个初始化的聚类中心矩阵,每一行代表一个初始的聚类中心。
(2)函数的输出结果为Idx和Center,其中:
【1】Idx是一个向量,表示每个数据点所属的聚类簇编号;
【2】Center是一个矩阵,表示最终得到的聚类中心。
3、
例:
1.
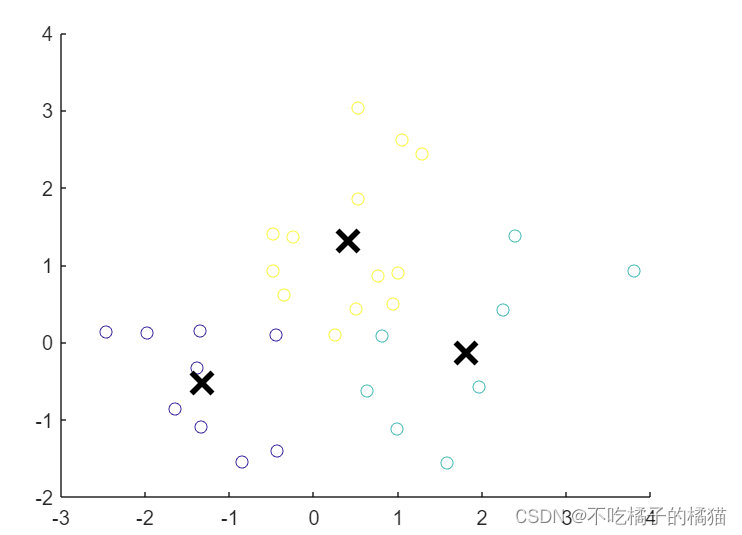
- data = [randn(10,2)+1; randn(10,2)-1; randn(10,2)];%生成数据点
- [idx, C] = kmeans(data, 3);%用K-means算法将data数据集聚类成3个簇
- scatter(data(:,1), data(:,2), [], idx);%用散点图可视化数据集
- hold on;
- plot(C(:,1), C(:,2), 'kx', 'MarkerSize', 15, 'LineWidth', 3);
- %将聚类中心绘制在散点图上
2.
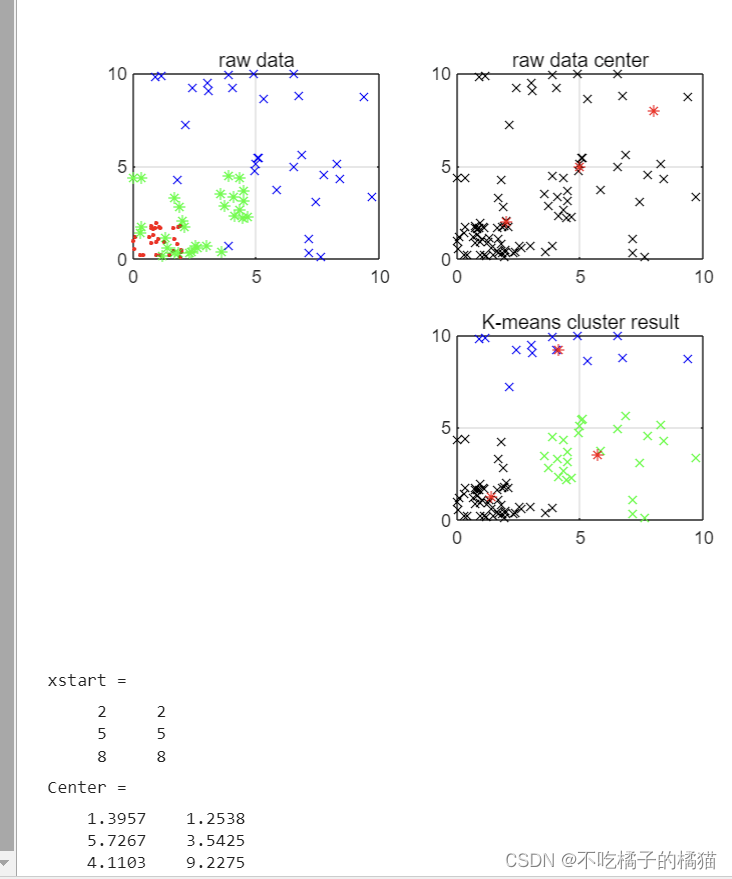
- %随机生成三组数据
- a = rand(30,2) * 2;
- b = rand(30,2) * 5;
- c = rand(30,2) * 10;
- figure(1);
- subplot(2,2,1);
- plot(a(:,1), a(:,2), 'r.'); hold on
- plot(b(:,1), b(:,2), 'g*');
- plot(c(:,1), c(:,2), 'bx'); hold off
- grid on;
- title('raw data');
-
- %K-means
- X = [a; b; c]; %需要聚类的数据点
- xstart = [2 2; 5 5; 8 8]; %初始聚类中心
- subplot(2,2,2);
- plot(X(:,1), X(:,2), 'kx'); hold on
- plot(xstart(:,1), xstart(:,2), 'r*'); hold off
- grid on;
- title('raw data center');
-
- [Idx, Center] = K_means(X, xstart);
- subplot(2,2,4);
- plot(X(Idx==1,1), X(Idx==1,2), 'kx'); hold on
- plot(X(Idx==2,1), X(Idx==2,2), 'gx');
- plot(X(Idx==3,1), X(Idx==3,2), 'bx');
- plot(Center(:,1), Center(:,2), 'r*'); hold off
- grid on;
- title('K-means cluster result');
-
- disp('xstart = ');
- disp(xstart);
- disp('Center = ');
- disp(Center);
上接
Matlab:BP神经网络算法,二叉决策树![]() https://blog.csdn.net/weixin_73011353/article/details/135275547
https://blog.csdn.net/weixin_73011353/article/details/135275547
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/719303
推荐阅读

相关标签

