
- 1EVE-NG强大的网络模拟器和实验平台_网络eve模拟器
- 2python引入视频_django 实现简单的插入视频
- 3transformer概述和swin-transformer详解_swintransformer和transformer
- 4AI十大流行算法_主流ai算法
- 5Kafka的ISR概念及Leader和follower数据同步机制_kafka中leader和follower
- 6基于Milvus向量数据库实现检索增强生成(RAG)_milvus rag
- 7【区间动态规划】1771. 由子序列构造的最长回文串的长度
- 8面试官问我MySQL和MariaDB的联系和区别,这我能不知道?_mysql mariadb 使用哪个
- 9Java程序员跳槽之旅,离开京东,12面面试回顾和一点经验分享_程序员一面二面的区别
- 10Java八股文(2024届)持续更新中..._java 八股文
基于决策树的鸢尾花Iris分类试验_决策树鸢尾花分类实验报告
赞
踩
基于决策树的鸢尾花Iris分类
by liunanchi,lichuanxiang
一、决策树简介
决策树(Decision Tree)是一种流行的机器学习算法,用于建立预测模型以及从数据中提取规则。它是一种基于树形结构的模型,其中每个内部节点表示在输入数据的特征空间中进行的一个特征测试,每个分支代表测试结果的一个可能值,而每个叶节点代表一个目标值或类别。决策树的目标是根据输入特征对目标变量进行分类或回归。
决策树的构建过程包括以下步骤:
特征选择:选择最佳的特征用于在当前节点分割数据集。通常使用的特征选择方法包括信息增益、基尼系数或方差减少等。
节点分割:根据选定的特征对数据集进行分割,生成子节点。分割后的子集应该在目标变量上更加纯净,即同一类别或目标值的数据应该尽可能地聚集在一起。
递归:对每个子节点重复以上步骤,直到达到停止条件。停止条件可以是达到最大深度、节点中的样本数量低于某个阈值、或者节点中的数据属于同一类别。
剪枝:对生成的决策树进行剪枝操作,防止过拟合并提高模型的泛化能力。
为了更了解决策树的工作方式,尝试利用决策树的方式对鸢尾花卉Iris数据集进行简单的分类。
二、鸢尾花Iris数据集
鸢尾花卉Iris数据集共包含150个样本,每个样本包含4个特征值(花瓣花萼的长度以及宽度)并根据四种特征值的不同分为三类(山鸢尾、变色鸢尾、维吉尼亚鸢尾)。
三、数据处理及模型训练
1.数据读取
// Read data
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
- 1
- 2
- 3
- 4
- 5
2.划分数据集
// split data
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
- 1
- 2
- 3
3.模型训练
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(x_train, y_train)
- 1
- 2
- 3
4.保存模型
import pickle
with open('decision_tree_model.pkl', 'wb') as f:
pickle.dump(clf, f)
- 1
- 2
- 3
四、模型测试
1.读取模型并进行测试
with open('decision_tree_model.pkl', 'rb') as f:
loaded_model = pickle.load(f)
prediction = loaded_model.predict(x_test)
print("Prediction:", prediction)
- 1
- 2
- 3
- 4
2.测试结果
Prediction: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2 1 1 2 0 2 0 0]
- 1
- 2
3.模型评估
# ------------ 准确率 ------------ #
acc = clf.score(x_test, y_test)
print("Accuracy: ", acc)
# ------------ 精确率、召回率、F1值 ------------ #
report = classification_report(y_test, y_pred)
print(report)
- 1
- 2
- 3
- 4
- 5
- 6
输出结果为:
Accuracy: 0.9777777777777777
- 1
precision recall f1-score support
0 1.00 1.00 1.00 16
1 1.00 0.94 0.97 18
2 0.92 1.00 0.96 11
accuracy 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从结果中可以看到:
准确率为0.97777,表示45条 (30%) 测试数据中,有44条预测正确。
在预测山鸢尾类别 (target = 0) 的16个样本时,精确率、召回率、F1值均为1;
在预测变色鸢尾类别 (target = 1) 的18个样本时,精确率为1、召回率为0.94、F1值为0.97;
在预测维吉尼亚鸢尾类别 (target = 2) 的11个样本时,精确率为0.92、召回率为1、F1值为0.96;
综合3个类别的宏平均 (macro avg) 也即算术平均,得到整体精确率0.97、召回率0.98、F1值0.98;
综合3个类别的加权平均 (weighted avg) ,得到整体精确率、召回率、F1值均为0.98;
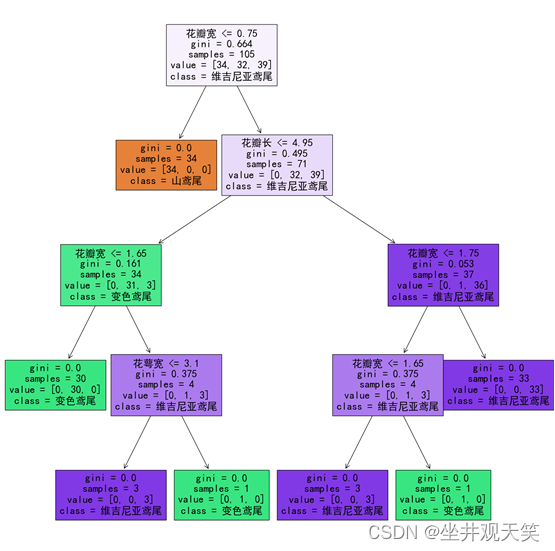
决策树可视化:
五、总结
实验中发现决策树在机器学习中具有以下优点:
易于理解和解释:决策树生成的规则易于解释,可以帮助人们理解数据之间的关系和模型的决策过程。
适用于各种数据类型:决策树可以处理数值型和类别型的数据,而无需额外的数据预处理。
可以处理大规模数据集:决策树的训练过程相对高效,可以处理大规模数据集。
鲁棒性:决策树对数据中的异常值和缺失值具有一定的鲁棒性。
然而,决策树也存在一些缺点,包括:
容易过拟合:决策树倾向于生成复杂的模型,容易过拟合训练数据。
不稳定性:数据的小变化可能导致生成不同的决策树。
难以处理连续型特征:决策树在处理连续型特征时需要进行离散化处理,可能导致信息损失。

