
- 1(附源码)ssm基于Html+css的音乐网站的设计与实现 毕业设计181627_html音乐网站框架设计
- 2vrchat模型房_vrchat人物模型 1.0 官方版
- 3盘点百度、阿里、腾讯、华为自动驾驶战略
- 4python 全栈开发,Day75(Django与Ajax,文件上传,ajax发送json数据,基于Ajax的文件上传,SweetAlert插件)...
- 5Android5.0之NavigationView的使用
- 6全球首个AI女主播上岗了!太惊艳了!
- 7魔兽世界私服架设教程——如何搭建魔兽世界私服
- 8蓝桥杯备考冲刺必刷题(Python) | 549 扫雷
- 9Java –将值附加到Object []数组中
- 10torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 31.74 GiB total
Incorporating Knowledge Graph Embeddings into Topic Modeling_vmf分布
赞
踩
2.方法
在这一部分中,我们介绍了KGE-LDA模型、Gibbs抽样推理和参数学习方法。
我们通过扩展两个经典的实体主题模型将实体嵌入到主题建模中,这两个模型分别是CI-LDA和Corr-LDA。 这两个模型可以处理同一主题空间中的词和实体,但它们只考虑在文本中识别的命名实体。 为了在知识图中利用三元组,我们可以直接使用实体嵌入来编码知识图结构,而不是只对实体进行编码。
由于余弦距离通常用于度量实体嵌入之间的相似性,并且一些知识图嵌入位于单位球面上![]() ,我们使用von Mises-Fisher(VMF)分布对它们进行建模。 VMF是定义单位球面上的点上的概率密度的分布。 vmf分布的概率密度函数是
,我们使用von Mises-Fisher(VMF)分布对它们进行建模。 VMF是定义单位球面上的点上的概率密度的分布。 vmf分布的概率密度函数是![]()
其中![]() 在一维球面上,即
在一维球面上,即![]() 。μ是平均值参数
。μ是平均值参数![]() ,(κ>0)k是浓度参数,前者定义平均值的方向,后者决定平均值周围概率质量的分布.。
,(κ>0)k是浓度参数,前者定义平均值的方向,后者决定平均值周围概率质量的分布.。![]() 是阶为ν,变元为a的第一类修正的贝塞尔函数。
是阶为ν,变元为a的第一类修正的贝塞尔函数。![]() 是x与均值μ之间的余弦相似度,κ的作用是方差的倒数。
是x与均值μ之间的余弦相似度,κ的作用是方差的倒数。
(1)表征与生成过程
我们将基于CI-LDA的模型命名为KGE-LDA(A),将基于Corr-LDA的模型命名为KGE-LDA(B)


设D是文档的个数,其中每个文档d有![]() 词,
词,![]() 实体通过现有的实体链接工具链接到现有的知识图,
实体通过现有的实体链接工具链接到现有的知识图,![]() 是d文档中的第n个词,
是d文档中的第n个词,![]() 是d中第m个实体的L维实体嵌入,这是本文通过横截(一维面)得到的。 我们选择Transe是因为它简单有效,并且在编码知识方面达到了最先进的性能。 而且,横截面的实体向量自然具有单位
是d中第m个实体的L维实体嵌入,这是本文通过横截(一维面)得到的。 我们选择Transe是因为它简单有效,并且在编码知识方面达到了最先进的性能。 而且,横截面的实体向量自然具有单位![]() 范数,不需要进行后处理。
范数,不需要进行后处理。 ![]() 分别是
分别是![]() 和
和![]() 的潜在主题分配。 设K是主题的个数,φk是主题
的潜在主题分配。 设K是主题的个数,φk是主题![]() 的V维主题词多项式,其中V是词汇表大小,θd是d的K维文档主题多项式。由于我们的实体是单位球面上的连续向量,我们将每个实体主题表征为具有参数
的V维主题词多项式,其中V是词汇表大小,θd是d的K维文档主题多项式。由于我们的实体是单位球面上的连续向量,我们将每个实体主题表征为具有参数![]() 的vmf分布。 α和β分别是θd和φk上的Dirichlet先验的超参数。 μ0,C0是μk的先前vmf分布的超参数。
的vmf分布。 α和β分别是θd和φk上的Dirichlet先验的超参数。 μ0,C0是μk的先前vmf分布的超参数。 ![]() 是
是![]() 的先前对数正态分布的均值和标准差。
的先前对数正态分布的均值和标准差。
①KGE-LDA(a)


②KGE-LDA(b)

(2)推理与参数学习
我们使用Gibbs抽样来推断潜在主题赋值![]() 和
和![]() 。
。![]() 的Gibbs抽样方程定义为:
的Gibbs抽样方程定义为:
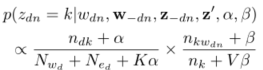
其中k是主题,w−dn是除wdn之外的所有单词,z−dn是除wdn之外的所有单词的主题分配,z' 是所有实体的主题分配,![]() 是主题k被分配给文档d中的词或实体的次数,
是主题k被分配给文档d中的词或实体的次数,![]() 是wdn被分配给主题k的次数,
是wdn被分配给主题k的次数,![]() 是所有词被分配给主题k的总次数。
是所有词被分配给主题k的总次数。
![]() 的Gibbs抽样方程类似中的Gibbs抽样。 我们可以利用vMF分布是共轭来抽样。 这使我们能够完全集成μk并仅通过维护主题赋值变量
的Gibbs抽样方程类似中的Gibbs抽样。 我们可以利用vMF分布是共轭来抽样。 这使我们能够完全集成μk并仅通过维护主题赋值变量![]() 来更新模型。KGE-LDA(a)推断等式:
来更新模型。KGE-LDA(a)推断等式:

其中![]() 是除edm之外的所有实体的主题分配,
是除edm之外的所有实体的主题分配,![]() 是除edm之外的所有实体的嵌入,z是所有单词的主题分配,
是除edm之外的所有实体的嵌入,z是所有单词的主题分配,![]() 是任何实体被分配给主题k的次数。如果我们将L和κk替换为l和κ,则C1(κk)的含义与等式(1)中的C1(κ)相同。 由于κk来自对数正态分布,我们首先从κk样本
是任何实体被分配给主题k的次数。如果我们将L和κk替换为l和κ,则C1(κk)的含义与等式(1)中的C1(κ)相同。 由于κk来自对数正态分布,我们首先从κk样本![]() 中抽取一些κk样本(在我们的实验中
中抽取一些κk样本(在我们的实验中
KGE-LDA(b)如下:
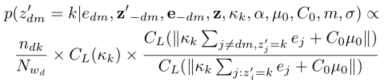
通过吉布斯抽样,我们可以使用公式(2)中的两个因子来估计θd和φk。
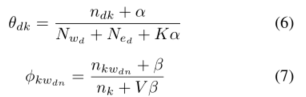
是100个样本,我们也尝试了其他的数字,但没有发现太大的差别),然后使用公式(4)从这些样本中抽取最终的Log k样本。
3.总结
本文提出了一种将主题模型和知识图嵌入相结合的KGE-LDA,特别是LDA模型和TRASE。 该方法利用自动从外部知识图学习到的实体向量编码的知识对文档级词语共现进行建模,可以提取更连贯的主题和更好的主题表示。 在三个数据集上的实验结果表明了该方法的有效性。 我们计划在未来的工作中探索更有效的方法来整合实体嵌入和试验更多的知识图。

