
- 1STM32结合ESP8266初始准备_esp32与单片机连接初始化
- 2sql:mysql:正则的基本使用(REGEXP),regexp_extract 和 regexp_replace 匹配手机号_mysql regexp_extract
- 3android 接收广播意图错误:java.lang.RuntimeException: Error receiving broadcast Intent { act=android.bluetoot
- 4RNNoise:学习噪声抑制
- 5掌握Linux系统休眠功能:sleep命令的使用_linux sleep
- 6数据结构小记【Python/C++版】——散列表篇
- 7Android Studio中报错的问题_android studio error: could not create the java vi
- 8内容观察者(ContentObserver)的使用~_contentresolver.registercontentobserver参数
- 9AI人工智能算法---神经网络_人工智能神经网络
- 10【MindSpore】云云联邦学习+Fasterrcnn目标检测+差分隐私训练保护隐私方案综合实现_联邦学习差分隐私路径规划
AI医药论文阅读笔记-Extracting Drug-drug Interactions with a Dependency-based Graph Convolution Neural Networ_ddiextraction2013 ner
赞
踩
基于依赖图的图卷积神经网络提取药物相互作用
Extracting Drug-drug Interactions with a Dependency-based Graph Convolution Neural Network
2019.11 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
目录
1.摘要
药物相互作用(DDI)在药物警戒等生物医学的各种应用中发挥着关键作用。生物医学出版物中经常报道DDI,使其成为提取DDI的有效来源。尽管神经网络在DDI提取方面取得了竞争优势,但之前的工作依赖依赖路径来去除生物医学出版物句子中的噪声。然而,这种方法可能会忽略关于DDI的关键信息。有效地利用大量依赖信息可以改进DDI提取。在这篇文章中,我们提出了一个模型,该模型结合了图卷积神经网络(GCN)和双向长短记忆(BiLSTM),从句子的整个依赖图中提取DDI交互。我们在该领域的基准语料库中评估了我们的模型,即DDIExtraction 2013语料库。我们的模型获得了最先进的结果(F1的77.0%),这优于之前工作中报告的结果。
结合了图卷积神经网络(GCN)和双向长短记忆(BiLSTM),从句子的整个依赖图中提取DDI交互。
2.INTRODUCTION
生物医学文献中包含了大量关于DDI的最新信息。生物医学文献的快速增长使得手动DDI提取变得不可能。因此,开发从生物医学文献中自动提取DDI的系统对于正在进行的临床研究具有重要意义。
-
机器学习方法:传统的基于特征的方法。
-
基于神经网络的方法优于传统的基于特征的方法[6],[7]。然而,神经网络无法有效地从长而复杂的句子中学习。例如,DDIExtraction 2013语料库中最长的句子包含150多个单词。因此,神经网络很难捕获有用的信息,同时忽略长句子中的噪声。
-
一些研究将最短依赖路径(SDP)[8]、[9]纳入深度神经网络,这可以提高性能,因为SDP能够去除噪声,但在句子中保留有效信息。最近的研究[10]证明了这种方法在DDI提取中的有效性。然而,依赖路径可能会从句子中丢失某些关键信息。
将整个依赖图集成到深度神经网络中:
-
双向长短记忆(BiLSTM)被用于学习每个单词的表示,并将其应用于整个句子。
-
将句子的整个依赖图送入图卷积神经网络(GCN)[11]、[12],以将依赖信息集成到单词表示中。
-
使用最大池层从单词表示中捕获显著信息,并生成句子和两个目标药物实体的表示。
-
这些表示被连接并馈送到多层感知器(MLP)[13]中,用于softmax分类。(DDI提取任务被视为分类任务)
我们提出的模型在DDI提取的基准语料库上进行了评估,即DDIExtraction 2013语料库。实验结果表明,我们的模型取得了最先进的结果。
relate
传统的机器学习方法:其中大多数需要提取各种词汇和句法特征,并将其提供给分类器,如SVM或随机森林[6]、[7]、[15]、[16]。已经提出了另一种基于核的方法[16]-[18],并成功地用于DDI提取。通常,这些基于内核和基于特征的方法高度依赖于内核函数或特征集的精心设计。
深度学习:如CNN(卷积神经网络)和RNN(递归神经网络)[19],[20]。一些研究人员将CNN与用于DDI提取的其他信息相结合,如句法信息[21]、分子信息[22]。RNN比CNN更有效,并与注意力机制[23]、基于特征的分类器[24]或SDP[10]结合用于DDI提取。一些研究人员[25]将两个模型组合在一起以提取DDI。该方法在2013年DDIExtraction语料库中取得了最先进的结果。
尽管已经提出了各种方法,但仍有很大的空间来提高DDI提取的性能。更重要的是,以前的工作只依赖依赖路径的信息来提取DDI,而我们的模型使用了完整的依赖图和原始语句。因此,我们的模型受益于结构信息(依赖性)和序列信息(句子)。
3.方法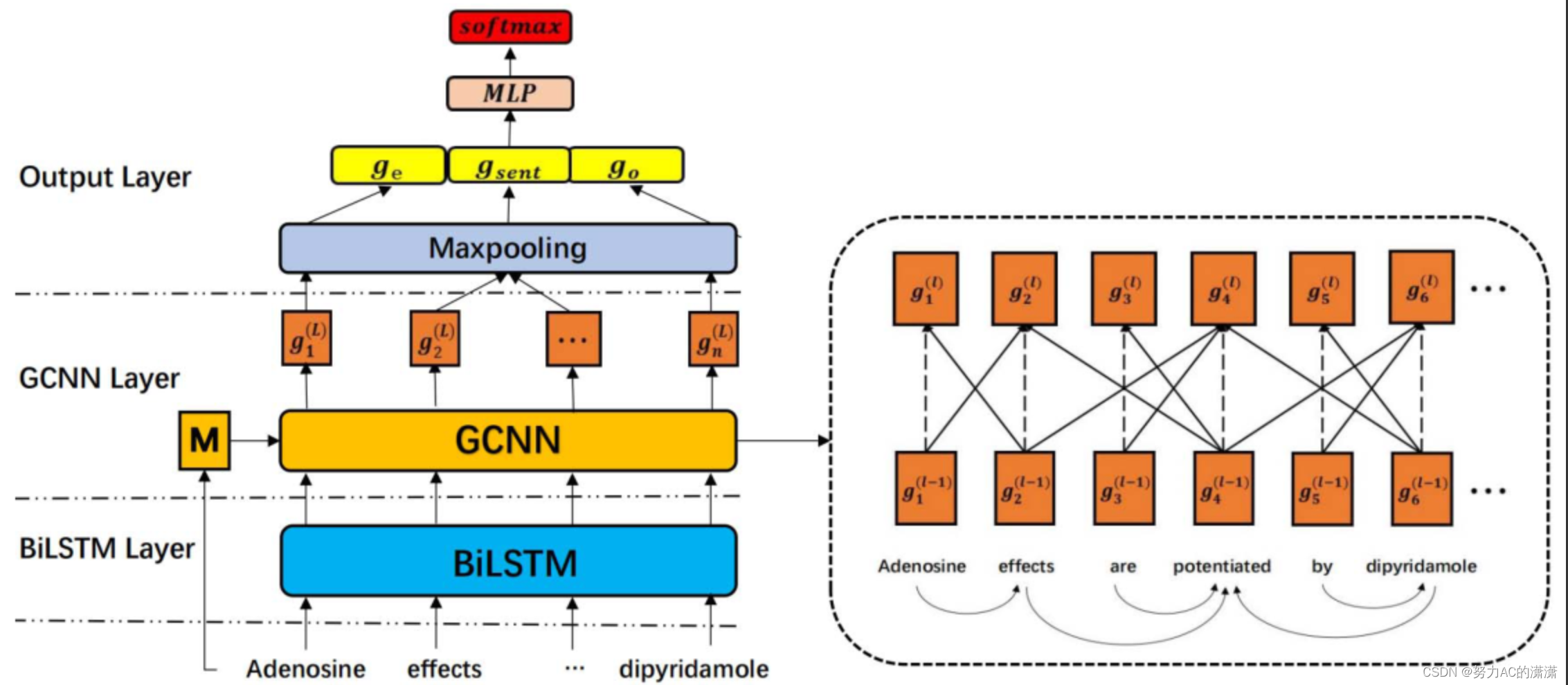
输入句子是“腺苷作用通过双嘧达莫增强”,有两个药物实体“腺苷”和“双嘧达莫”。M表示从依赖图构建的邻接矩阵。右边是GCNN更新单词表示的过程。实心箭头曲线表示依赖关系。实线箭头表示节点通过卷积运算从其相邻节点汇总信息。虚线箭头线表示模型在第l层中构建表示时还考虑了(l− 1)层。
3.1 BiLSTM层
给定一对实体(druge和drugo)和一个句子S={s1,s2,…,sn},我们使用斯坦福CoreNLP工具包获得句子的词性(POS)标签序列P={p1,p2,……,pn}。
对于每个单词si和POS标签pi,我们将它们表示为低维密集向量,即嵌入。用预先训练的单词嵌入[27]和我们的POS标签嵌入随机初始化单词嵌入。我们模型的输入是单词和POS嵌入的连接。
BiLSTM层由两个LSTM组成,它们对输入序列进行正向和反向编码,并输出两个隐藏矢量(→h i和←h i)。然后,它们连接为hi。
【27】S. Moen and T. S. S. Ananiadou, “Distributional semantics resources for biomedical text processing,” Proceedings of LBM, pp. 39–44, 2013
3.2 GCN层
给出一个句子S={s1,s2,…,sn},我们使用斯坦福CoreNLP工具包[26]来获得其依赖图。我们认为它的依赖图是一个无向图,它可以转换成相邻矩阵。如果依赖图中的节点i和j之间存在依赖关系,则相邻矩阵中的元素Mij被赋值为1。然后我们使用GCNN[12]将依赖信息合并到单词表示中。
对于L层GCNN,我们将第一层中的输入表示为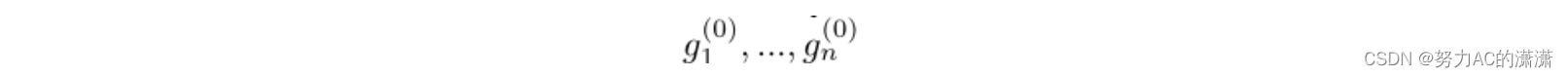
,将最后一层中的输出表示为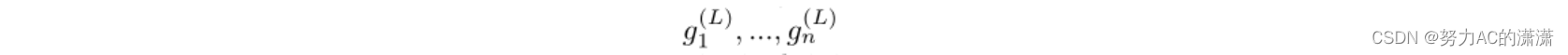
第l层中的卷积运算可以写为: 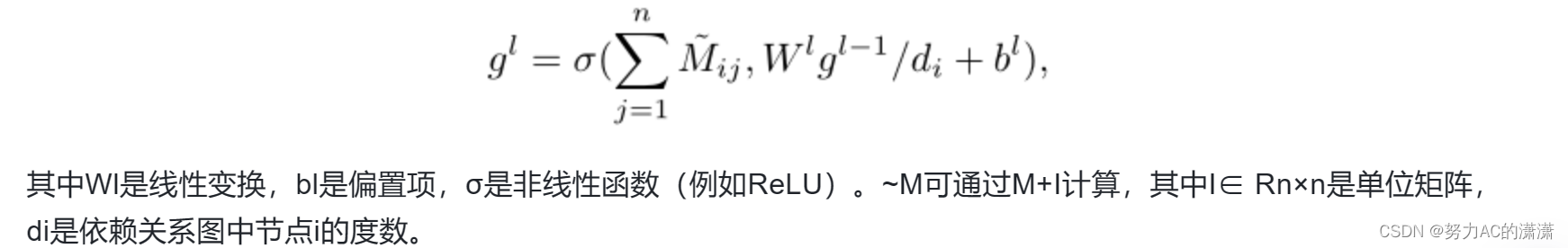

3.3 输出层
我们将DDI提取任务视为分类任务。设S=[s1,…,sn]表示一个句子,其中si是第i个标记。druge和drugo表示由句子中的几个标记组成的两个药物实体,即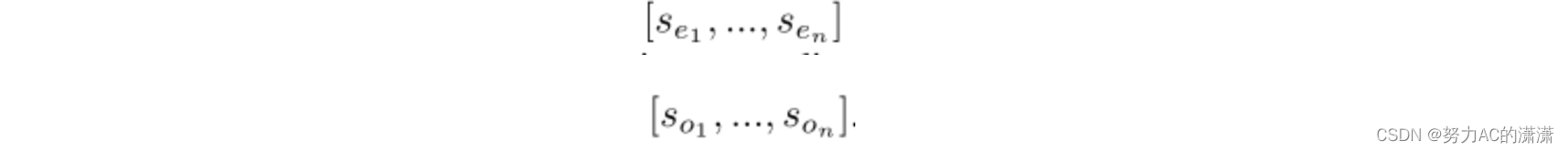
DDI提取的目的是从所有真实的DDI类型(mechanism, advice, effect, int)和假类型“FALSE”预测药物和药物之间的关系类型。
在将L层GCNN应用于输入单词向量之后,我们获得每个单词的表示。句子表示可以使用以下等式获得:f最大池函数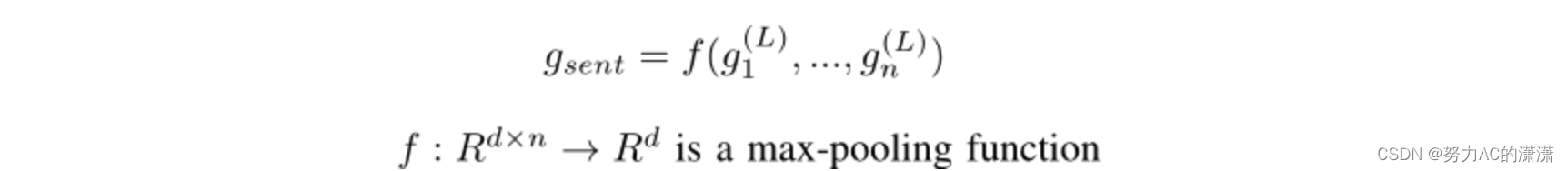
由于我们还观察到实体信息通常对DDI提取至关重要,因此还使用了实体表示ge和go,如下所示: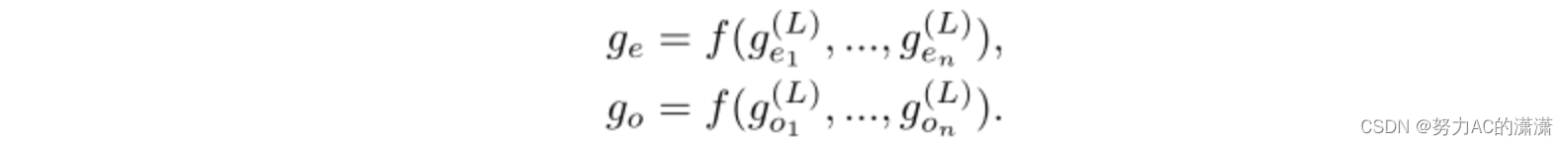
受[28]、[29]的启发,我们通过将句子和实体表示馈送到多层感知器(MLP)中,获得了DDI提取的最终特征: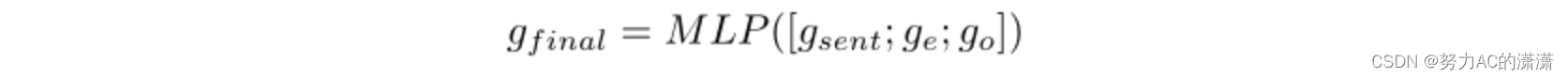
其中“[]”表示连接操作。最后,gfinal被馈送到softmax层以计算所有类的概率分布。在训练过程中,我们使用交叉熵损失函数来优化模型的参数。
4.实验
4.1 Dataset
在DDIExtraction 2013语料库[5]上评估了我们的方法,该语料库是评估DDI提取方法性能的基准数据集。DDIExtraction 2013语料库包含四种DDI类型:Advice、Effect、Mechanism和Int。属于不同DDI类型的示例在DDIExtriction 2013的语料库中非常不平衡。阴性实例(即没有四个上述DDI的药物实体对)的数量明显多于阳性实例。为了缓解类不平衡的问题,我们使用了否定实例过滤策略来过滤尽可能多的否定实例,如前面的工作[7],[19],[20],[30]。
4.2 比较实验
如表所示,我们的模型实现了0.801的精度、0.740的召回率和0.770的F1,比Sun等人提出的当前最先进的方法分别高2.8%、0.3%和1.6%。
为了评估检测不同类型DDI的困难程度,我们还给出了每种DDI类型的性能。在这四种类型中,我们的模型对Advice类型表现最好,对Int类型表现最差。(我们可以看到,训练集只包含188个Int类型的示例,远远少于其他DDI类型的示例。因此,训练数据的大小可能是导致这种差异的一个可能原因。)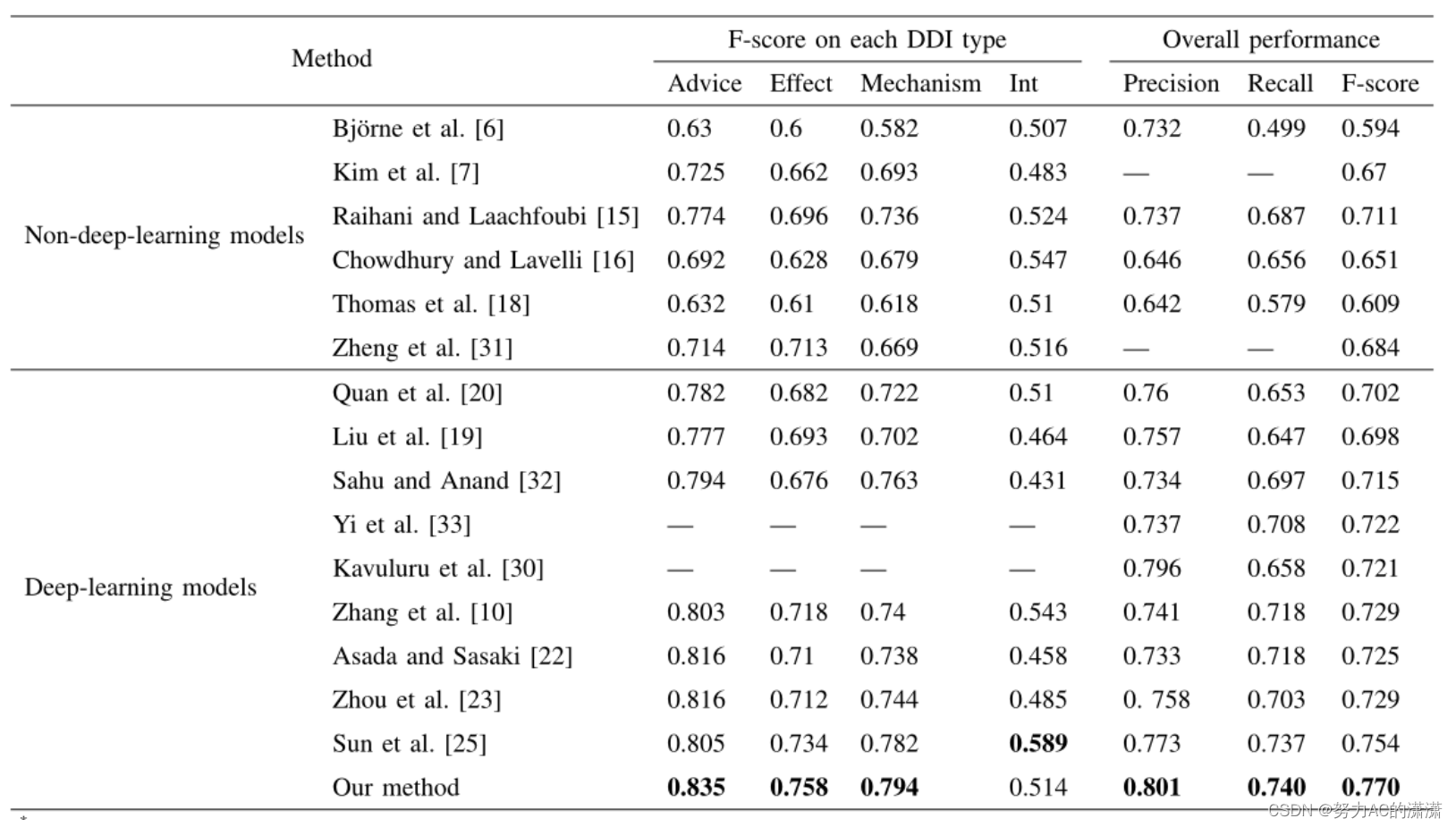
4.3 消融实验
为了了解我们方法中不同部分的影响,我们对预先训练的单词嵌入、POS嵌入和负实例过滤策略。
当仅使用预先训练的单词嵌入时,我们的方法获得了0.745的F分数。当POS嵌入与单词嵌入集成时,性能进一步提高。这些结果表明,单词嵌入是我们模型高性能的主要部分,但POS嵌入作为补充特征也很有价值。
在应用负实例过滤策略过滤出一些不同的负实例后,数据不平衡的问题可以在一定程度上得到缓解,比率分别变为1:4.76和1:3.83。因此,在降低正面和负面示例的比率后,我们模型的总体F分数增加了1.20%。
5 结论
在本文中,我们提出了一个深度学习模型,该模型从原始句子中学习序列信息,并从整个依赖图中学习结构信息句子。实验结果表明,我们的模型在DDI提取方面达到了最先进的性能。我们发现POS嵌入和负实例过滤策略对我们的模型非常有效,可以进一步提高性能。此外,我们的模型在Int类型的DDI中表现不佳。未来,我们打算在更多的数据集上测试我们的模型,以评估其泛化能力

