
热门标签
热门文章
- 1如何使用Git提交文件_git 提交文件
- 2Elasticsearch 安装 Elasticsearch-SQL 插件使用 SQL 操作_es安装sql插件
- 3什么是IPD流程
- 4ROS2机器人编程简述humble-第三章-BUMP AND GO BEHAVIOR IN PYTHON .4_ros2机器狗趴下代码
- 5电脑丢失api-ms-win-crt-runtime-l1-1-0.dll的多种修复方法_api-ms-win-crt-runtime-l1-1-0.dll修复
- 6python期末题库和答案,python期末总结怎么写
- 7又一历史时刻:Transformer和Mamba都被超越了!大模型最强架构TTT问世!_大模型全新架构ttt(test-time-training+layers)问世
- 8Qt中各个widget前后位置的设定_qt用代码初始化widget并放到指定位置
- 9[项目管理] 如何使用git客户端管理gitee的私有仓库_gitee 私有仓库
- 10由于SQL Server日志文件过大导致C盘满了的解决方案_sqlserver数据库c盘满了
当前位置: article > 正文
【论文泛读193】LICHEE:使用多粒度标记化改进语言模型预训练_lichee: improving language model pre-training with
作者:Li_阴宅 | 2024-08-06 13:15:07
赞
踩
lichee: improving language model pre-training with multi-grained tokenizatio
贴一下汇总贴:论文阅读记录
论文链接:《LICHEE: Improving Language Model Pre-training with Multi-grained Tokenization》
一、摘要
基于大型语料库的语言模型预训练在构建丰富的上下文表示方面取得了巨大成功,并在各种自然语言理解 (NLU) 任务中取得了显着的性能提升。尽管取得了成功,但目前大多数预训练语言模型,如 BERT,都是基于单粒度标记化训练的,通常使用细粒度字符或子词,这使得它们很难学习粗粒度的精确含义。单词和短语。在本文中,我们提出了一种简单而有效的预训练方法 LICHEE,以有效地合并输入文本的多粒度信息。我们的方法可以应用于各种预训练的语言模型并提高它们的表示能力。
二、结论
本文提出了一种新的语言模型预训练的多语方法LICHEE,它既适用于自回归语言模型,也适用于自编码语言模型。在我们的方法中,细粒度嵌入和粗粒度嵌入被分别学习并集成为多粒度嵌入,然后被传递给语言模型的编码器。实验表明,与现有的多粒度方法相比,LICHEE在中英文下游任务上显著提高了模型性能,并显著提高了推理速度。
三、框架
LICHEE的整体结构:
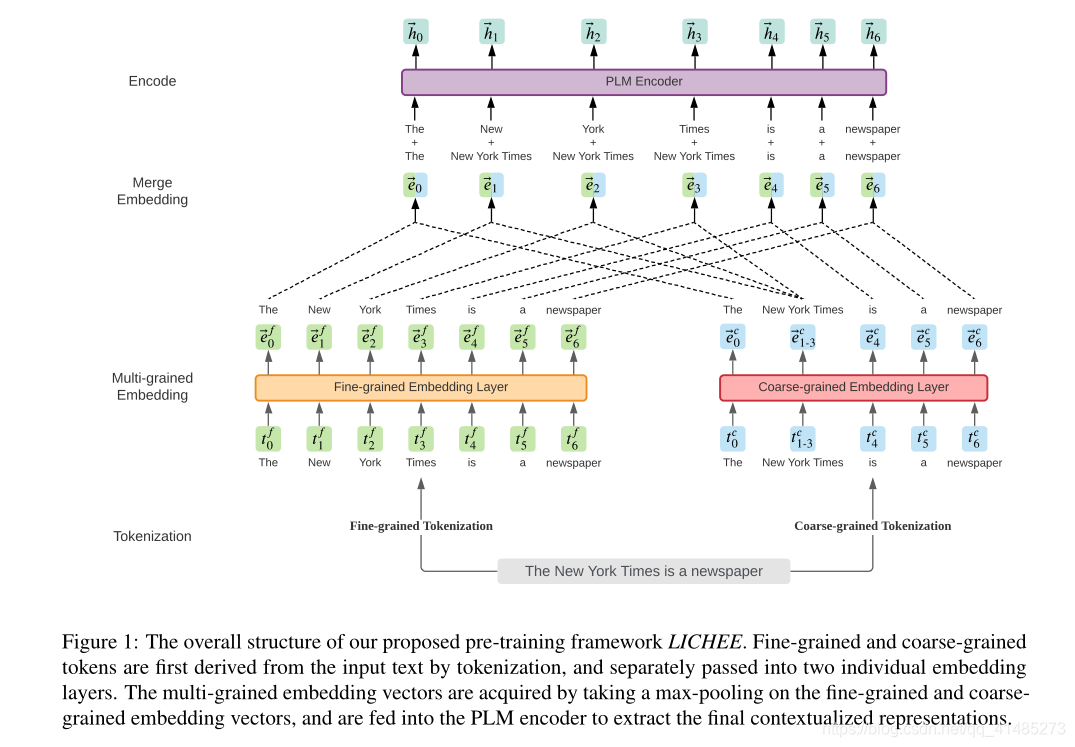
是一个通用的多粒度语言模型预处理框架。
- 自回归
- 自编码任务的预处理方法
- 微调细节
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Li_阴宅/article/detail/937567
推荐阅读
相关标签

