
- 1蚂蚁金服漆远:人工智能是如何重新定义金融行业的?
- 2FastAPI入门_nest.js fastapi
- 3上海低空经济发展白皮书(2024)
- 4Linux系统安全①iptables防火墙_linux iptables
- 5AI+OCR赋能古彝文数字化—让经典重新跳动_古文字图像分割
- 6Mac安装python 环境& pycharm_mac python环境搭建
- 7200T转炉倾动机构设计【说明书+CAD图纸】_转炉倾动装置 教学资料
- 8k8s中pv创建的两种方式:静态创建pv和动态创建pv---基于nfs创建
- 9链表实现输入两个整数数组,A B,将B与A合并,并且排序_输入两个整数数组,每个数组有5个整数,将二者进行合并,然后按照数值从小到大排序输
- 10wpf menu 菜单 快捷键_wpf menuitem快捷键
用Beeware做一个app_beeware能直接操作数据库吗
赞
踩
分享用Beeware制作一个给儿童学识字的安卓App的经验。
1.从拼多多来的一个认字大王3000字得到启示,每一页为小学1到5年的生字,通过朗读字和2个组词,然后就小孩按页面上的字,达到让小孩认字的目的。我认为可以制作一个App,让孩子直接用,不用购买这类点读机器。当然这里面每页大约有50多个字,让小孩要找很久,这也是要改进的因素。
2.考虑最近在学习python,我研究了几种可以让python编写安卓App的工具,发现kivy很难安装,可能需要翻墙,一直安装不成功,而Beeware虽然功能比较少,但容易安装使用,果断采用Beeware。
3.Beeware和Python的安装过程省略。采集小学生汉字组词拼音也省略,制作数据库也省略:
一、开始的准备工作:
1.创建数据库hz
CREATE TABLE IF NOT EXISTS hz (
id INTEGER PRIMARY KEY AUTOINCREMENT,
hz VARCHAR(4),
py VARCHAR(10),
zc1 VARCHAR(20),
zc2 VARCHAR(20),
zc3 VARCHAR(20),
zc4 VARCHAR(20),
zc5 VARCHAR(20),
kw VARCHAR(60),
nj VARCHAR(20),
cs INTEGER)

后面的sc是后来加上去的,记录wav文件的播放时长。
2.使用pyttsx3生成声音
像识字3000中说:哪个是天,蓝天、天空的天。
- import pyttsx3
- import sqlite3
- import wave
-
- conn = sqlite3.connect('16hz.db')
- c = conn.cursor()
- # 创建TTS引擎对象
- engine = pyttsx3.init()
- engine.setProperty('audio_format', 'wav')
- gid = 1
- while gid <= 1000:
- cursor = c.execute("SELECT id, hz, py, zc1, zc2, zc3, kw from hz where id ="+str(gid))
- row = cursor.fetchone()
- text = "哪个是"
- text = text + row[1] + ','
- text = text + row[3] + ','
- if len(row[4]) > 0:
- text = text + row[4] + ','
- #if len(row[5]) > 0:
- # text = text + row[5] + ','
- text = text + '的' + row[1]
- engine.save_to_file(text, './sy1/'+str(gid)+'.wav')
- engine.runAndWait()
- gid = gid + 1
- gid = 1001
- while gid <= 2000:
- cursor = c.execute("SELECT id, hz, py, zc1, zc2, zc3, kw from hz where id ="+str(gid))
- row = cursor.fetchone()
- text = "哪个是"
- text = text + row[1] + ','
- text = text + row[3] + ','
- if len(row[4]) > 0:
- text = text + row[4] + ','
- #if len(row[5]) > 0:
- # text = text + row[5] + ','
- text = text + '的' + row[1]
- engine.save_to_file(text, './sy2/'+str(gid)+'.wav')
- engine.runAndWait()
- gid = gid + 1
- gid = 2001
- while gid <= 2791:
- cursor = c.execute("SELECT id, hz, py, zc1, zc2, zc3, kw from hz where id ="+str(gid))
- row = cursor.fetchone()
- text = "哪个是"
- text = text + row[1] + ','
- text = text + row[3] + ','
- if len(row[4]) > 0:
- text = text + row[4] + ','
- #if len(row[5]) > 0:
- # text = text + row[5] + ','
- text = text + '的' + row[1]
- engine.save_to_file(text, './sy3/'+str(gid)+'.wav')
- engine.runAndWait()
- gid = gid + 1
- input("please input any key to exit!")
- conn.close()

同样通过pyttsx3生成“你答对了”,“你答错了”的语音,本来在PC上用是不用生成声音再播放出来的,但如果跨平台,像Android是无法使用TTS,或者可以使用,但我不知道怎么办。
二、中间各种尝试,如做成一个命令行的运行模式,用Qpython在手机上运行,等等,这里省略。
三、也是最后的版本
安装beeware,用briefcase new开始做一个app,将上面的数据库、sy声音文件搬到src里面。然后修改app.py文件为(里面有一些注释,帮助大家读懂程序):
- from functools import partial
- import toga
- from toga.style.pack import COLUMN, LEFT, RIGHT, ROW, Pack
- import sqlite3
- import random
- from time import time, sleep
- from pathlib import Path
- import miniaudio
- import datetime
- import threading
- #import shutil
- #导入必要的库,其中这个miniaudio库是可以在Android上运行的,我尝试了很多播放声音的库,只有这个能被Beeware编译到安卓程序上
-
- resources_folder = Path(__file__).joinpath("../resources/").resolve()
- resources_folder1 = Path(__file__).joinpath("../resources/sy1").resolve()
- resources_folder2 = Path(__file__).joinpath("../resources/sy2").resolve()
- resources_folder3 = Path(__file__).joinpath("../resources/sy3").resolve()
- db_filepath = resources_folder.joinpath("16hzqw.db")
- #db_filepath = '/storage/emulated/0/Pictures/16hzqw.db'
- #上面是数据库和音频文件的存放位置
- #oppo版 需要用电脑调试应删除下面5行
- '''
- if Path('/storage/emulated/0/Documents/16hzqw.db').exists():
- db_filepath = '/storage/emulated/0/Documents/16hzqw.db'
- else:
- shutil.copy(db_filepath, "/storage/emulated/0/Documents/16hzqw.db")
- db_filepath = '/storage/emulated/0/Documents/16hzqw.db'
- #使用手机将数据库存放在手机的文档文件夹中,如果不这样做,虽然程序能够运行,但是不能保存每次运行程序的数据,包括写入、更新,不知道为什么。
- 这里还有个说明,如果采用Android7的系统或者一些手机、平板(我的oppo手机不用),需要
- 首先要在AndroidManifest.xml文件的application 标签下 加一条属性 android:requestLegacyExternalStorage=“true”
- 还有读写权限:见https://blog.csdn.net/qq_51108920/article/details/126153395
- 这个xml文件在运行briefcase create android后在生成的learn2read build learn2read android gradle app src main中,在运行briefcase build android前要修改好才生效,learn2read是我的程序名,藏得够深的吧,修改后还要在手机app权限中设置一下,还是比较复杂的。
- '''
-
- global duihz, duipy, duizc1, duizc2, duizc3,duizc4,duizc5, duid, kw, jj
- global stime, etime, ytime, begintime, testcs, cuo_cs, yshen, cid, tjcs
- names = globals()
- cid = 0
- yshen = 0
- testcs = 0
- cuo_cs = 0
- stime = time()
- begintime = time()
- rid = 0
- cuot = 0
- global njt
- njt = '一年级'
- #上面是全局参数和默认值
- def bfsy(hzid,idsc):
- if hzid < 1001:
- stream = miniaudio.stream_file(str(resources_folder1.joinpath(str(hzid) + '.wav')))
- elif hzid > 1000 and hzid < 2001:
- stream = miniaudio.stream_file(str(resources_folder2.joinpath(str(hzid) + '.wav')))
- elif hzid > 2000 and hzid < 3001:
- stream = miniaudio.stream_file(str(resources_folder3.joinpath(str(hzid) + '.wav')))
- elif hzid > 3000 and hzid < 4000:
- stream = miniaudio.stream_file(str(resources_folder3.joinpath('cuo.wav')))
- #大于3000为错,其余为对
- else:
- stream = miniaudio.stream_file(str(resources_folder3.joinpath('dui.wav')))
- with miniaudio.PlaybackDevice() as device:
- device.start(stream)
- sleep(idsc)
- #播放声音函数
- def maxmin(xzng):
- if xzng < 9:
- yshen = 0
- else:
- yshen = 1
- if xzng == 1 or xzng ==9:
- njt = '一年级'
- elif xzng ==2 or xzng ==10:
- njt = '二年级'
- elif xzng == 3 or xzng ==11:
- njt = '三年级'
- elif xzng == 4 or xzng ==12:
- njt = '四年级'
- elif xzng == 5 or xzng ==13:
- njt = '五年级'
- elif xzng == 6 or xzng ==14:
- njt = '六年级'
- else:
- njt = '二年级'
- return(njt,yshen)
-
- njt,yshen = maxmin(3)
- #选择年级和有声无声的函数,默认是3
- def u_record(testcs,cuo_cs,etime,begintime,cid):
- if testcs > 0:
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- c.execute("UPDATE record SET ts = ?,ct = ?,mt = ? WHERE cid = ?;", (testcs,cuo_cs,int((etime-begintime) / testcs),cid))
- conn.commit()
- c.close()
- conn.close()
- #记录每次的题数,错题数,每题用多少秒,每个界面用一个cid
- def u_cs1(duid):
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- query_sql = "update hz set cs1 = cs1 + 1 where id= ?"
- c.execute(query_sql, (str(duid),))
- conn.commit()
- c.close()
- conn.close()
- #记录这个汉字的练习次数+1
- def u_cs(addcs,duid):
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- query_sql = "update hz set cs = cs + ? where id= ?"
- c.execute(query_sql, (str(addcs),str(duid),))
- conn.commit()
- c.close()
- conn.close()
- #为某个汉字加积分
- def j_cs(addcs,duid):
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- query_sql = "update hz set cs = cs - ? where id= ?"
- c.execute(query_sql, (str(addcs),str(duid),))
- conn.commit()
- c.close()
- conn.close()
- #为某个汉字减少积分
- def tj_cs():
- if globals()['testcs'] == 0:
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- query_str = 'select rq,sum(ts),sum(ct),round(avg(mt),0) from record group by rq order by rq desc limit 0,4;'
- cursor = c.execute(query_str)
- rows = cursor.fetchall()
- stext3 = ""
- for row in rows:
- stext3 += "%s:做%d题,错%d题,平均用%d秒\n" % (row[0],row[1],row[2],row[3])
- c.close()
- conn.close()
- globals()['tjcs'] = stext3
- else:
- stext3 = globals()['tjcs']
- return(stext3)
- #在界面的下面显示最近4天学习总题数等信息,方便家长检查孩子的学习情况
- def set_all(njt):
- fid = random.randint(0, 16)
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- cursor = c.execute(
- "SELECT id, hz, py, zc1, zc2, zc3, zc4, zc5, kw, sc from (SELECT *,rank() over (PARTITION by hz order by id desc) as rank FROM hz where nj like '%" + njt + "%' order by cs asc) where rank = 1 limit " + str(fid) + ",16")
- rows = cursor.fetchall()
- hz = []
- py = []
- zc1 = []
- zc2 = []
- zc3 = []
- zc4 = []
- zc5 = []
- hzid = []
- kw = []
- idsc = []
- i = 1
- for row in rows:
- if i < 17:
- hzid.append(row[0])
- hz.append(row[1])
- py.append(row[2])
- zc1.append(row[3])
- zc2.append(row[4])
- zc3.append(row[5])
- zc4.append(row[6])
- zc5.append(row[7])
- kw.append(row[8])
- idsc.append(row[9])
- i = i + 1
- ii = list(range(1,17))
- random.shuffle(ii)
- c.close()
- conn.close()
- return ii,hzid,hz,py,zc1,zc2,zc3,zc4,zc5,kw,idsc
- #按年级返回16个汉字的拼音组词、课文、id、和音频文件的播放长度,等整个程序发完专门说明这个
- def build(app):
- # 定义组件
- c_box = toga.Box()
- b1_box = toga.Box()
- b2_box = toga.Box()
- b3_box = toga.Box()
- b4_box = toga.Box()
- box = toga.Box()
- c_input = toga.TextInput(readonly=True,style=Pack(font_size=22))
- c_label = toga.Label("请选择几年级开始学习...", style=Pack(text_align=LEFT))
- c_label1 = toga.Label("", style=Pack(text_align=LEFT, font_size=12))
- c_label2 = toga.Label("", style=Pack(text_align=LEFT))
- c_label3 = toga.Label("", style=Pack(text_align=LEFT))
- #界面设置
- def bt1(bb, widget):
- xzng = int(bb)
- globals()['testcs'] += 1
- globals()['etime'] = time()
- globals()['ytime'] = int(etime - stime)
- #记录用时
- if rid == 0:
- current_date = datetime.datetime.now()
- formatted_date = current_date.strftime("%Y-%m-%d")
- formatted_time = current_date.strftime("%H:%M:%S")
- #每次rid=0时,生成一个记录,记录学习情况
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- c.execute("INSERT INTO record (rq,sj,ts,ct,mt) VALUES (?,?,?,?,?);", (formatted_date,formatted_time,0,0,0))
- conn.commit()
- cursor = c.execute("SELECT cid from record order by cid desc")
- row = cursor.fetchone()
- c.close()
- conn.close()
- globals()['cid'] = row[0]
- #提取cid到全局变量中
- globals()['testcs'] = 0
- #rid为0时,测试次数重计
- globals()['cuo_cs'] = 0
- #错误次数也重计
- globals()['begintime'] = time()
- #设定rid为0是的开始时间,可以计算做完16个汉字的时间
- globals()['njt'],globals()['yshen'] = maxmin(xzng)
- #将年级和有声的变量按选择存入到全局变量
- globals()['ii'],globals()['hzid'],globals()['hz'],globals()['py'],globals()['zc1'],globals()['zc2'],globals()['zc3'],globals()['zc4'],globals()['zc5'],globals()['kw'],globals()['idsc']=set_all(globals()['njt'])
- #将全部要用到的变量存入全局变量
- globals()['stime'] = time()
- #设定本次开始时间
- for i in range(1,17):
- setattr(names['button_' + str(i)],"text",hz[ii[i-1]-1])
- #设置按键名称,即把汉字显示在按钮上,汉字通过随机错排列,这个ii就是打乱了的1到16顺序,2个-1是因为最小是0
- globals()['rid'] = 1
- #rid变为1,算第一次,答对了rid才会增加1
- globals()['duid'] = hzid[rid-1]
- #这个是对的汉字在数据库中的id
- globals()['jj'] = ii.index(rid) + 1
- #这个变量是记忆对的汉字选择的按钮的编码,index是寻址,寻找rid在ii列中的位置,这个位置+1为按钮的参数
- if yshen == 0:
- if zc2[rid-1] == '':
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□')
- else:
- zc = []
- zc.append(zc1[rid-1])
- zc.append(zc2[rid-1])
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□') + "、" + zc2[rid-1].replace(hz[rid-1],'□')
- if zc3[rid-1] != '':
- zc.append(zc3[rid-1])
- if zc4[rid-1] != '':
- zc.append(zc4[rid-1])
- if zc5[rid-1] != '':
- zc.append(zc5[rid-1])
- zc = random.sample(zc,2)
- c_value = py[rid-1] + " " + zc[0].replace(hz[rid-1], '□')+ "、" + zc[1].replace(hz[rid-1],'□')
- #无声是在输入栏显示拼音和隐去本字的组词,这里面采用随机数,在多个组词中随机选择2个
- c_text = '来自:' + globals()['njt'] + '的' + kw[rid-1]
- #显示来自年级和课文
- c_label.text = c_text
- c_label3.text = tj_cs()
- #rid为0是,显示统计的4天学习情况
- if yshen == 0:
- c_input.value = c_value
- else:
- play_sound_background(hzid[rid-1],idsc[rid-1])
- #当选择有声时,用miniaudio发出声音,不使用sleep就不会播放声音,sleep的时长就是播放声音的时长,后台播放,虽然会重音但比较流畅
- #rid为0为一开始设置第一题
- else:
- text5 = "复习:"
- if rid >=1:
- text5 = text5 + hz[rid-1] + "(" + py[rid-1] + ") " + zc1[rid-1] + " " + zc2[rid-1] + " " + zc3[rid-1] + " " + zc4[rid-1] + " " + zc5[rid-1]
- #text5是复习内容
- if testcs > 0:
- stext = '%d分钟,共答%d题,错%d题,每题%d秒。' % (int((etime-begintime) / 60),testcs,cuo_cs,int((etime-begintime) / testcs))
- if xzng == globals()['jj']:
- c_label1.text = text5
- #回答正确才显示复习内容
- if yshen == 1:
- c_input.value = hz[rid-1] + " 字答对了。"
- c_label2.text = '累计学习' + stext
- else:
- c_label2.text = '答对。累计' + stext
- if ytime <= 7:
- u_cs(2,hzid[rid-1])
- #用时小于7秒加2分
- else:
- u_cs(1,hzid[rid-1])
- #用时大于7秒加1分
- #play_sound_background(0,1.174) 播放正确的声音
- globals()['stime'] = time()
- globals()['rid'] += 1
- #回答正确,开始下一个汉字的计时和rid
- if rid == 17:
- if yshen != 0:
- play_sound_background(4500,1.174)
- sleep(1.1)
- #切换16个字界面时,播放答对了,让孩子知道过篇了
- u_record(testcs,cuo_cs,etime,begintime,cid)
- current_date = datetime.datetime.now()
- formatted_date = current_date.strftime("%Y-%m-%d")
- formatted_time = current_date.strftime("%H:%M:%S")
- conn = sqlite3.connect(db_filepath, timeout=10, check_same_thread=False)
- c = conn.cursor()
- c.execute("INSERT INTO record (rq,sj,ts,ct,mt) VALUES (?,?,?,?,?);", (formatted_date,formatted_time,0,0,0))
- conn.commit()
- cursor = c.execute("SELECT cid from record order by cid desc")
- row = cursor.fetchone()
- globals()['cid'] = row[0]
- c.close()
- conn.close()
- globals()['testcs'] = 0
- globals()['cuo_cs'] = 0
- globals()['begintime'] = time()
- globals()['stime'] = time()
- njt = globals()['njt']
- globals()['ii'],globals()['hzid'],globals()['hz'],globals()['py'],globals()['zc1'],globals()['zc2'],globals()['zc3'],globals()['zc4'],globals()['zc5'],globals()['kw'],globals()['idsc']=set_all(njt)
- globals()['stime'] = time()
- for i in range(1,17):
- setattr(names['button_' + str(i)],"text",hz[ii[i-1]-1])
- globals()['rid'] = 1
- #当rid等于17是,实际就是第二轮开始,初始化一些变量,重新写入cid
- globals()['duid'] = hzid[rid-1]
- globals()['jj'] = ii.index(rid) + 1
- #因为上面rid加1了,所以这2个全局变量都要变。
- if yshen == 0:
- if zc2[rid-1] == '':
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□')
- else:
- zc = []
- zc.append(zc1[rid-1])
- zc.append(zc2[rid-1])
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□') + "、" + zc2[rid-1].replace(hz[rid-1],'□')
- if zc3[rid-1] != '':
- zc.append(zc3[rid-1])
- if zc4[rid-1] != '':
- zc.append(zc4[rid-1])
- if zc5[rid-1] != '':
- zc.append(zc5[rid-1])
- zc = random.sample(zc,2)
- c_value = py[rid-1] + " " + zc[0].replace(hz[rid-1], '□')+ "、" + zc[1].replace(hz[rid-1],'□')
- if yshen == 0:
- c_input.value = c_value
- else:
- play_sound_background(hzid[rid-1],idsc[rid-1])
- #上面为选择正确时的程序
- else:
- globals()['cuo_cs'] += 1
- if yshen == 1:
- c_input.value = "答错了!请重新选择!"
- c_label2.text = '累计学习' + stext
- play_sound_background(3500,1.325)
- sleep(1.2)
- #播放错误的声音,还是需要sleep,不然不会停下来
- play_sound_background(hzid[rid-1],idsc[rid-1])
- #选择错误时的程序,重新读一遍
- else:
- if zc2[rid-1] == '':
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□')
- else:
- zc = []
- zc.append(zc1[rid-1])
- zc.append(zc2[rid-1])
- c_value = py[rid-1] + " " + zc1[rid-1].replace(hz[rid-1],'□') + "、" + zc2[rid-1].replace(hz[rid-1],'□')
- if zc3[rid-1] != '':
- zc.append(zc3[rid-1])
- if zc4[rid-1] != '':
- zc.append(zc4[rid-1])
- if zc5[rid-1] != '':
- zc.append(zc5[rid-1])
- zc = random.sample(zc,2)
- c_value = py[rid-1] + " " + zc[0].replace(hz[rid-1], '□')+ "、" + zc[1].replace(hz[rid-1],'□')
- c_input.value = "重答:" + c_value
- c_label2.text = '答错!累计' + stext
- j_cs(3,hzid[rid-1])
- #选择错误,扣3分
- globals()['stime'] = time()
- c_text = '来自:' + globals()['njt'] + '的' + kw[rid-1]
- c_label.text = c_text
- c_label3.text = tj_cs()
- if globals()['cid'] > 0:
- u_record(testcs,cuo_cs,etime,begintime,cid)
- u_cs1(hzid[rid-1])
- #记录学习情况
- aaa = '一 二 三 四 五 六 无 声 ㈠ ㈡ ㈢ ㈣ ㈤ ㈥ 有 声'.split()
- #print(aaa) 用字符串变为数组,这样代码比较简
- for i in range(1,17):
- names['button_' + str(i)] = toga.Button(aaa[i-1], on_press=partial(bt1, str(i)),style=Pack(font_size=25))
- #初始界面
- # 设置组件样式和布局
- c_box.add(c_input)
- box.add(c_box)
- for i in range(1,5):
- b1_box.add(names['button_' + str(i)])
- for i in range(5,9):
- b2_box.add(names['button_' + str(i)])
- for i in range(9,13):
- b3_box.add(names['button_' + str(i)])
- for i in range(13,17):
- b4_box.add(names['button_' + str(i)])
- box.add(b1_box)
- box.add(b2_box)
- box.add(b3_box)
- box.add(b4_box)
- box.add(c_label)
- box.add(c_label1)
- box.add(c_label2)
- box.add(c_label3)
- # 设置 outer box 和 inner box 的样式
- box.style.update(direction=COLUMN, padding=5)
- b1_box.style.update(direction=ROW, padding=1)
- b2_box.style.update(direction=ROW, padding=1)
- b3_box.style.update(direction=ROW, padding=1)
- b4_box.style.update(direction=ROW, padding=1)
- c_box.style.update(direction=ROW, padding=5)
-
- # 设置单个组件的样式
- c_input.style.update(width=345, flex=1)
-
- # button.style.update(padding=15)
- c_label.style.update(width=345, padding_left=4)
- c_label1.style.update(width=345, padding_left=4)
- c_label2.style.update(width=345, padding_left=4)
- c_label3.style.update(width=345, padding_left=4)
- for i in range(1,17):
- names['button_' + str(i)].style.update(width=85, height=85, padding=1)
-
- return box
- def play_sound_background(hzid,idsc):
- thread = threading.Thread(target=bfsy, args=(hzid,idsc,))
- thread.daemon = True
- thread.start()
- #用线程,在后台播放声音
- def main():
- return toga.App("千纬认字(舒尔特版)", "org.qwrz2", startup=build)
-
- if __name__ == "__main__":
- main().main_loop()
-
-
-
然后是注意在briefcase create android后修改那个xml文件。
后记:
一开始我设计的程序是在16个按钮中选择一个念到的汉字,然后在跳到下一题,又是16个不同的字中选择一个汉字,这样老是变动选择的汉字,我觉得不方便孩子记得汉字,参考舒尔格表格(一个可以让孩子专注的训练表格),我将16个字放在一个界面上,让孩子听到就选择。因为有时候需要无声,所以我也设计了无声的选择,就是用汉字拼音提示,让孩子根据拼音去选择汉字。以下是程序的运行界面:选择带括号的是有声音的。
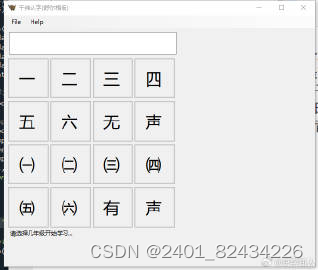
因为一年级有相同的汉字,我用了sql的开窗函数才让这个界面不会出现相同的汉字: cursor = c.execute(
"SELECT id, hz, py, zc1, zc2, zc3, zc4, zc5, kw, sc from (SELECT *,rank() over (PARTITION by hz order by id desc) as rank FROM hz where nj like '%" + njt + "%' order by cs asc) where rank = 1 limit " + str(fid) + ",16")
rows = cursor.fetchall()
网上有人说sqlite是不支持开窗函数的,实际是错误的。后面的fid是一个随机数,cs是积分,答对又快就增加这个汉字的积分,答慢或错就减少积分,所以错误和不熟悉的汉字就要经常练。这个就是这个程序比汉字3000好的地方,当然也能够记录练习的次数。
app下载:百度网盘 请输入提取码 9ohc (这个版本已经更新,请下载后面的版本)
补充修改:原程序发布后我发现,不会记录每个字测试了几次,发现代码错了,便修改过来。同时我准备制作一个可以对战的认识字的游戏,即能够给2个人玩,发现播放声音的时候,另一个人玩不了,对于单人玩(按上面下载的app)也出现读某个汉字的时候,其他按键按不了,好像有点卡的感觉,于是我将播放声音交给后台线程播放,能够最大限度保持app的运行流畅,但存在一个问题,如果答题太快就是出现多个声音,但我认为这个可以让孩子自己去把握答题速度,也不再去改善。
app下载:链接:https://pan.baidu.com/s/1MMHFJenl_n8f1AhHFgj5Ng
提取码:u3n5

