
- 1居然才发现!字节跳动旗下国产AI绘画工具Dreamina,这么好用居然还免费!(强烈推荐)_dreammina
- 2k-modes聚类算法及python代码实现
- 3COLMAP的安装_虚拟机安装colmap
- 4androidstudio升级2.2出现导入第三方库出错解决方法_android studio引入第三方库后the binary version of its
- 5json转换成excel在线js小工具分享【不限制大小】_json在线转excel 子对象
- 6【微信小程序开发实战项目】——如何制作一个属于自己的花店微信小程序(1)
- 7树--二叉树理论基础
- 8JVM之内存与垃圾回收——JVM与Java体系结构_创建一个初始类来完成的,这个类是由虚拟机的具体实现指定。
- 9tkinter入门(9)--布局管理器(pack,grid,place)_tk pack 两个组件并排
- 10Android实现WebServer(服务端)之AndServer_android andserver
Hive视图与索引操作_怎么建 stocks.csv
赞
踩
Hive视图与索引
1. 前置准备
实验环境
- Oracle Linux 7.4
- Java1.8.0_144
- Hadoop2.7.4
- Hive2.1.1
数据准备
实验数据用户信息表文件userinfo.txt内容
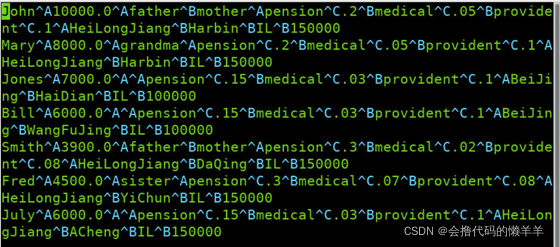
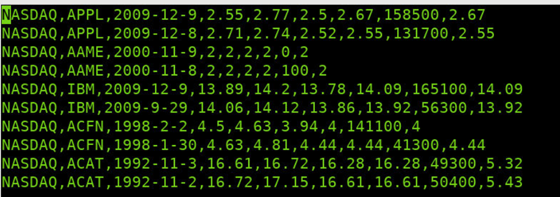
数据文件stocks.csv内容
stocks.csv内容以逗号“,”分隔,依次记录股票代码、股票交易日期、股票开盘价、股票开盘价、股票最低价、股票收盘价、股票交易量和股票成交价。
2. 视图索引
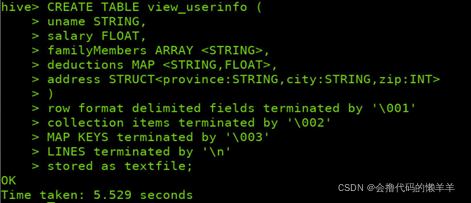
2.1 建表操作
CREATE TABLE view_userinfo (
uname STRING,
salary FLOAT,
familyMembers ARRAY <STRING>,
deductions MAP <STRING,FLOAT>,
address STRUCT<province:STRING,city:STRING,zip:INT>
)
row format delimited fields terminated by '\001'
collection items terminated by '\002'
MAP KEYS terminated by '\003'
LINES terminated by '\n'
stored as textfile;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.2 导入数据
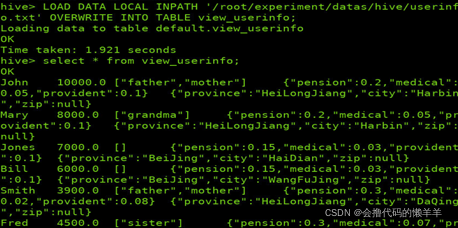
加载userinfo.txt文件内容至表view_userinfo中
LOAD DATA LOCAL INPATH '/root/experiment/datas/hive/userinfo.txt' OVERWRITE INTO TABLE view_userinfo;
- 1
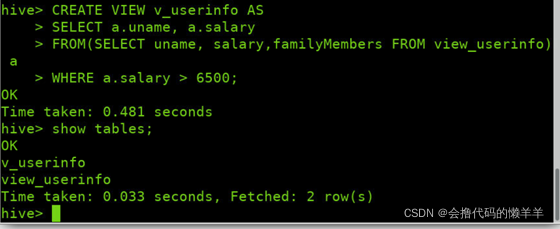
将一个嵌套子查询变成一个视图,视图名为v_userinfo并查询
CREATE VIEW v_userinfo AS
SELECT a.uname, a.salary
FROM(SELECT uname, salary,familyMembers FROM view_userinfo) a
WHERE a.salary > 6500;
- 1
- 2
- 3
- 4
2.3 视图查询
查看视图v_userinfo涉及字段类型
desc v_userinfo;
- 1
查询数组中的值
describe EXTENDED v_userinfo;
- 1
复制视图v_userinfo的结构,建立新表tb_v_userinfo
CREATE TABLE tb_v_userinfo LIKE v_userinfo;
- 1
查询新建立的表tb_v_userinfo的结构,与视图v_userinfo结构一致,新表查询无数据。
DESC tb_v_userinfo;
SELECT * FROM tb_v_userinfo;
- 1
- 2
- 3
2.3.1 动态分区
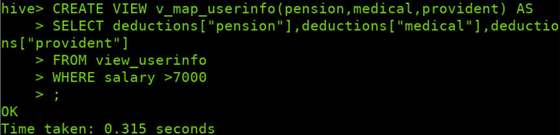
创建带动态分区中的视图v_map_userinfo和Map类型
CREATE VIEW v_map_userinfo(pension,medical,provident) AS
SELECT deductions["pension"],deductions["medical"],deductions["provident"]
FROM view_userinfo
WHERE salary >7000
;
- 1
- 2
- 3
- 4
- 5
查询动态分区的视图v_map_userinfo。
SELECT pension,medical,provident FROM v_map_userinfo;
- 1
DROP VIEW IF EXISTS v_userinfo;
- 1
2.4 Hive索引
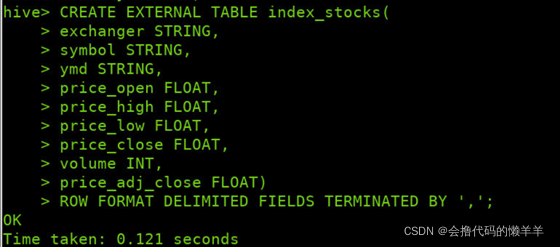
依据stocks.csv内容,将下面命令输入hive>后,建立表index_stocks
CREATE EXTERNAL TABLE index_stocks(
exchanger STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
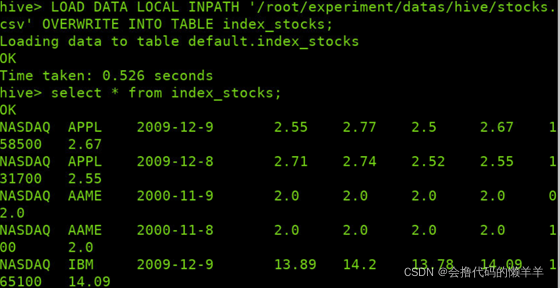
加载stocks.csv文件内容至表index_stocks中并查询所有内容
LOAD DATA LOCAL INPATH '/root/experiment/datas/hive/stocks.csv' OVERWRITE INTO TABLE index_stocks;
-- 确定数据已经成功加载至index_stocks表中
SELECT * FROM index_stocks;
- 1
- 2
- 3
为表index_stocks中字段symbol上创建一个索引i_stocks
CREATE INDEX i_stocks
ON TABLE index_stocks(symbol)AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERRED REBUILD;
- 1
- 2
- 3
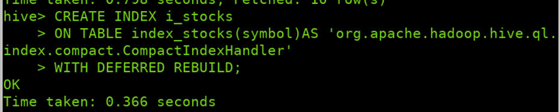
查看表index_stocks上已经存在的索引信息
格式查看表index_stocks上已经存在的索引信息
SHOW INDEX ON index_stocks;
SHOW formatted INDEX ON index_stocks;
- 1
- 2
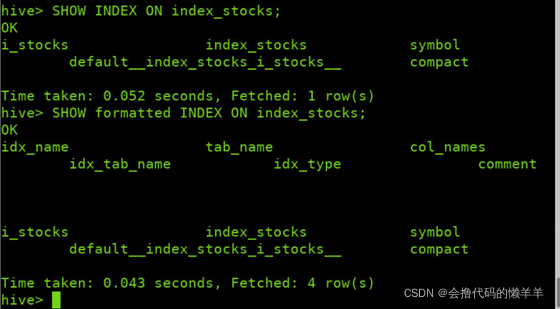
查看index_stocks表上建立的索引

3. 流程总结
视图其实是一个虚表,视图可以允许保存一个查询,并像对待表一样对这个查询进行操作,视图是一个逻辑结构,并不会存储数据。
hive中只有有限的索引功能,hive中没有主键和外键的概念,可以通过对一些字段建立索引来加速某些操作,一张表的索引数据存储在另外一张表中。
使用索引:
SELECT 字段名表
FROM 表名
WITH (INDEX(索引名))
WHERE 查询条件
申明:文章仅做记录,涉及侵权内容请联系删除

