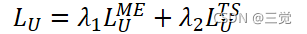- 1基于FPGA的百兆以太网通信(一)——MDIO配置PHY芯片
- 2使用StratifiedKFold实现交叉验证_手动实现kfold
- 3软件测试工程师简历项目经验怎么写(含真实简历)_通讯软件测试项目经验怎么编_软件测试项目经历
- 4java关键术语_java 术语
- 5kimi 初体验_kimi api
- 6全国青少年软件编程Python等级考试-五级标准_python 五级
- 7代码随想录——动态规划_算法随想录网站
- 84、内网安全-隧道&内网穿透上线&Ngrok&FRP&NPS&SPP&EW项目_kali系统ngrok教程
- 92024年03月 Python(一级)真题解析#中国电子学会#全国青少年软件编程等级考试_中国电子学会python一级真题
- 10python小白入门_pythen教程
Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning笔记
赞
踩
本文是Mehdi Sajjadi等作者发表在NIPS 2016上的一篇文章,该方法设计之初是为了更好的用于卷积神经网络的半监督学习。文章PDF https://proceedings.neurips.cc/paper/2016/file/30ef30b64204a3088a26bc2e6ecf7602-Paper.pdf
https://proceedings.neurips.cc/paper/2016/file/30ef30b64204a3088a26bc2e6ecf7602-Paper.pdf
在卷积神经网络的训练过程中,通常会对样本的输入特征进行随机转换,数据增强,随机max-pooling;除此之外,dropout,随机梯度下降(SGD)算法的使用都会增加模型的随机性,这样可以提高模型的学习能力,降低过拟合的风险。但是这么多随机性的加入也会导致模型预测结果的不稳定,增加模型预测效果的方差。于是本研究提出了一种无监督Loss用于保证在利用随机性提高模型性能的同时,降低随机性带来的波动。
一、
设置训练模型的数据集含有N个样本和C个分类标签,用于分类预测的模型记为,假定由于随机转换及数据增强(或者其他方法)使得在一次前向传播过程中,模型
一共会对样本
预测
次。于是我们就可以使用
表示在第j次预测时,模型
对样本
的预测向量。同时,定义
表示在进行第
次预测之前,对样本
进行的线性或非线性转换。于是,本研究提出的无监督Loss就可以写成:
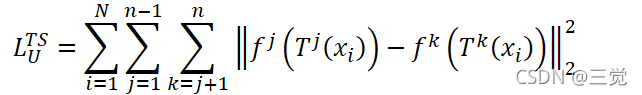
其中,TS表示“转换守恒”。在每一次预测过程中,都会为模型f生成一个不一样的输入,然后由于dropout等方法的使用,每次预测的结果都会有所不同。通过最小化上述损失
,尽可能保证模型每次预测的结果是一致的。
二、
由于上述损失函数的定义并没有利用样本的标签信息,如果仅仅使用上述损失函数训练模型是不够的。对于一个监督学习的分类任务而言,由于样本的标签是一个由0/1编码的向量,所以我们希望模型f对样本的预测向量也尽可能只有一个非0元素,而互斥损失函数(mutual-exclusivity loss)就可以完成这类任务。互斥损失函数可以迫使模型预测向量只含有一个非0元素。于是,该函数就可以很好的弥补
在监督学习任务上的不足。对于训练样本
而言,其互斥损失函数如下:
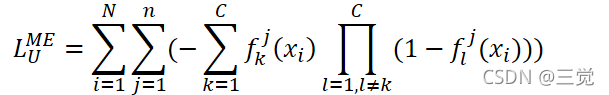
其中,ME表示“互斥”,表示预测向量
的第k个元素。
三、
研究表明,将和
联合使用可以得到更好的预测准确性,于是总Loss就可以表示为: