
- 1[MRCTF2020]Ezpop
- 2llama.cpp部署(windows)_llama-cpp cmark
- 3FlinkCDC基础篇章2-数据源 SqlServerCDC写入到ES中_flink cdc sqlserver op字段
- 4windows环境下搭建MeterSphere(自动化测试平台)_metersphere本地自动化平台搭建
- 5一道网红面试题(腾讯、百度面试中都出现过)_关于网红的面试题
- 6程序员去大公司面试,直言失望:没法接受领导年龄比自己小_程序员面试想把自己年龄说小一点
- 7人脸识别(从OpenCV、Dlib到Face-Recongnition)学习_face-recognition
- 8Bert的相关疑问
- 9FPGA之zynq以太网(2)_zynq串口配置以太网ip
- 10Php—— 1.apache2.4.x+php7.x_tar: can't specify both -c and -x
推理?大语言模型能力测评
赞
踩
大语言模型能做什么?能做多好?如何验证?

接上一篇测评大语言模型的自然语言理解能力,这回把关注点放在大语言模型推理能力的测评上。看看大语言模型推理水平有多高,如何测试证实。
本文同样基于十几位中美学者在7月6日发布的《大语言模型测评调查》研究报告(https://arxiv.org/pdf/2307.03109.pdf )展开。
推理以及推论 Reasoning vs Inference

图:大语言模型通过推理过程获得结果推论
"Reasoning"(推理)和 "Inference"(推论)是两个紧密相关又有些许不同的概念。在研究大模型的自然语言理解的工作中,重点往往在自然语言的推论,即推理的结论,所以一般会讲Inference;而在研究大模型的推理能力的工作中,侧重点更多地放在了逻辑和思维的过程。会讲Reasoning多一些。即,通过推理(Reasoning)过程产生推论(Inference)的结果。
举个例子来说明:假设"所有人都需要喝水"(这是一个前提条件),然后得出"约翰需要喝水"这个结论。在这个例子中,推理(Reasoning)是整个过程,包括考虑到前提条件并应用逻辑规则来得出结论。而推论(Inference)是最终的结论,即"约翰需要喝水"。
分析结论对错不能不联系得到结论的方法,而评判方法的有效性根本上也是依赖于结果的好坏。因此,就测评而言,难以非常清晰地划分推理能力的测评与自然语言推论(NLI)能力。前文从自然语言理解的角度出发,分析大语言模型自然语言推论的性能,本文也不纠结于细节的区分和概念的重叠,从推理的角度,梳理一下大语言模型的能力。
大语言模型的推理能力
算术推理(Arithmetic Reasoning)

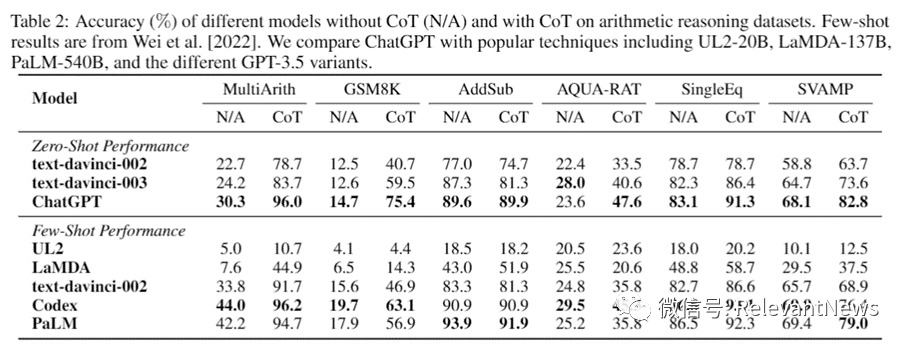
【能力描述】 多步骤推理的基本数学问题进行问答 【测试数据集举例】 MultiArith:600道算术应用题。 GSM8K:8.5K 个高质量小学数学应用题的数据集。。 AQuA: 包含问题、答案和基本原理的 100,000 个样本的代数问答数据集。 AddSub, SingleEq和SVAMP等数据集 【测试实例】 Q: George had 28 socks. If he threw away 4 old ones that didn’t fit and bought 36 new ones, how many socks would he have? A: The answer (arabic numerals) is 60. George would have 60 socks. (28 + 36 = 60) Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. 【相关模型】 ChatGPT 【评估结果】
论文截图:在7个加减乘除运算应用题数据集上的测试结果 ChatGPT在大部分任务中展现了较强的算术推理能力。 【一些评论】 简单的加减乘除应用题ChatGPT准确率75%以上。但在AQuA-RAT的测试不到50%的准确率(原因在论文中没有给出)。 多篇文章表明大模型“在数学推理方面的熟练度仍需要改进”,会表现出“粗心”(Careless)、善变(Fickle-Minded)等问题。 |
符号推理(Symbolic Reasoning)

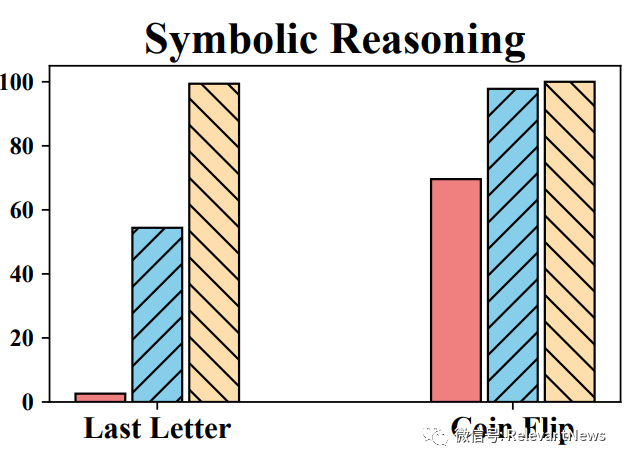
【能力描述】 根据描述得出一般的逻辑规则,在给定的参数上运用,获得结果。 【测试数据集举例】 Last Letter Concatenation: 姓名尾字母连接 Coin Flip:硬币翻面数据集 【测试实例】 Last Letter Concatenation: Q: Take the last letters of the words in “Lady Gaga” and concatenate them. A: The last letter of “Lady” is “y”. The last letter of “Gaga” is “a”. Concatenating them is “ya”. So the answer is ya. Coin Flip: Q: A coin is heads up. Maybelle flips the coin. Shalonda does not flip the coin. Is the coin still heads up? A: The coin was flipped by Maybelle. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up. So the answer is no. 【相关模型】 ChatGPT, GPT 3.5 【评估结果】
论文截图来自于https://arxiv.org/pdf/2302.06476.pdf 通过模型微调,可以将一些符号推理任务的准确率提高到90%以上。 【一些评论】 从测评结果来看,使用大模型进行符号推理并非完全可靠。从测评的方法来看,大模型并不完全采用符号推理的方法完成任务。另外,通过CoT Prompting(思想链的提示工程)为大模型提供符合逻辑推理的案例,非常有助于提高大模型的性能。 |

常识推理(Commonsense Reasoning)

【能力描述】 得出与人类对自己的经常行为和意图进行推理一致,和人类对物理世界的自然理解类似的结论的能力 【测试数据集举例】 CommonsenseQA:侧重于一般常识问题回答 PiQA: 关注实务常识推理 Pep-3k: 每个实例都是一个s-v-o谓词,任务是判断该谓词是否合理。 【测试实例】 一般常识问题:“商务餐厅很可能位于哪里?” 实务常识推理:给定一个句子,例如“当黄油煮沸时,当它准备好时,你可以将其倒入”,目标是从两个答案选项中填入空白处,即“将其倒入盘子”和“将其倒入罐子”。 Pep-3K的实例:"人-吞下-彩蛋","刀-砍-岩石" 。推理任务是判断该谓词是否合理。不仅仅基于二元判断,还检查答案是否包含导致判断的相关原因(解释)。例如,请判断以下谓词是否(很可能)合理:“刀子砍岩石”。ChatGPT 答案 刀子不可能能够砍穿岩石。刀子是用来切割较软的材料,如食物、纸张或木材。岩石比这些材料要硬得多,刀子无法在岩石上留下痕迹,更不用说砍断它了。 【相关模型】 ChatGPT 【评估结果】
论文截图:常识推理测评任务结果 测评结果显示常识推理的准确性皆超过80%。 |

时间推理 (Temporal Reasoning)

【能力描述】 对事件的持续时间和事件之间时序关系的理解。 【测试数据集举例】 TimeDial数据集 【测试实例】 "conversation": [ "A: We need to take the accounts system offline to carry out the upgrade. But don't worry, it won't cause too much inconvenience. We're going to do it over the weekend .", "B: How long will the system be down for ?", "A: We'll be taking everything offline in about two hours ' time. It'll be down for a minimum of twelve hours. If everything goes according to plan, it should be up again by 6 pm on Saturday .", "B: That's fine. We've allowed <MASK> to be on the safe side ." ], "correct1": "forty-eight hours", "correct2": "50 hours ", "incorrect1": "two hours ", "incorrect1_rule": "Rule 1", "incorrect2": "12 days ", "incorrect2_rule": "Rule 2" 【相关模型】 ChatGPT 【评估结果】 时间推理方面表现较好 (88.67%)。 |
空间推理(Spatial Reasoning)

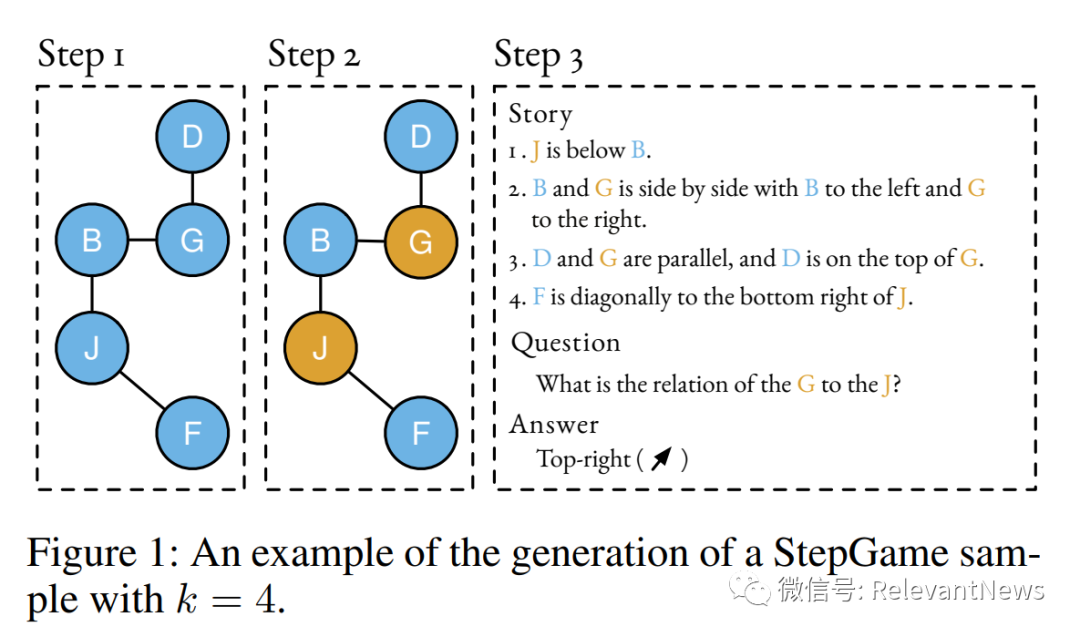
【能力描述】 空间推理是利用对不同对象和空间之间的空间关系的理解。 【测试数据集举例】 SpartQA和StepGame:由关于k+1个实体(其中k最多为10)的故事-问题对组成,以自然语言编写。 【测试实例】 SparQA Example:
StepGame Example:
【相关模型】 ChatGPT 【评估结果】
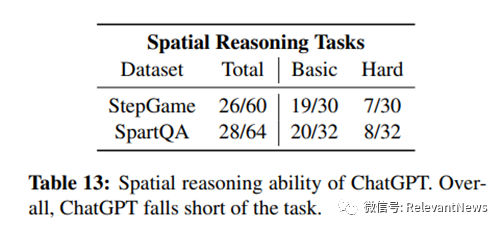
论文截图:空间推理测评任务结果 如表所示,ChatGPT在空间推理任务上表现不佳,整体成功率为43.33%(对于StepGame)和43.75%(对于SpartQA)。ChatGPT在SpartQA(困难任务)上仅得分25%,该任务涵盖了多种空间推理子类型,对于k=9的stepGame(困难任务)得分为23.33%。ChatGPT无法提供任何空间关系,而是生成“在给定的描述中没有明确指定”。即使对于微调模型,随着上下文描述中关系数目(k)的增加,性能也会下降。
论文截图:空间推理测评显示大语言模型对基本方位(Basic Cardinal)的推理能力较强 另外,大语言模型模型对基本的方位(上下左右)推理能力相对较好(准确率85%),但对于如"六点钟方向"或"左下方"等更复杂的的方位推理,准确率极低。 |


因果推理(Casual Reasoning)
【一些评论】 在前文《测评大语言模型的自然语言理解能力》中,在ECare数据集上对因果推论进行了类似的测试,ChatGPT达到80%以上的准确率,在此不再重复。 |
类比推理(Analogical Reasoning)

【能力描述】 在表面上看起来很不相似的情况下,识别出情境之间的抽象相似性的能力。通常,这涉及到一种重新表示的过程,即对初始问题表示进行修订,以便促进类比的发现。 【测试数据集举例】 字母字符串类比,用于评估类比推理的计算模型,特别强调了重新表示的过程。 【测试实例】
论文截图:在图中的例子a中,源字符串“a b c d”通过将最后一个字母转换为其后继字母,得到字符串“a b c e”。必须识别这个转换,然后将其应用于目标字符串“i j k l”,得到答案“i j k m”。 【相关模型】 ChatGPT, GPT-4 【评估结果】 大模型非常擅长类比,在一些字母串类比中测试中交出满分答案。 |

复杂多跳推理(Multi-hop Reasoning)
【能力描述】 涉及多个步骤或多个层次的推理过程。在多跳推理中,为了得出最终答案,需要在不同的知识或信息之间进行多次推理和推导,逐步建立关联并获取必要的上下文信息。 【测试数据集举例】 HotPotQA:包含113,000个基于维基百科的问题-答案对。 这些问题要求在多个支持文档中查找和推理,以便回答;这些问题是多样化的,并不限于任何预先存在的知识库或知识模式。 【测试实例】
论文截图:Multi-hop数据集样例 【相关模型】 ChatGPT 【评估结果】
论文截图:从测评结果来看,与因果推理(80%)和类比推理(100%)相比,测评显示大模型多跳推理的能力明显不足(不足30%)。 |


逻辑推理(Logical Reasoning)

【能力描述】 归纳推理、演绎推理和溯因推理等抽象推理的能力 【测试数据集举例】 bAbI, EntailmentBank(演绎), CLUTRR(归纳),αNLI(溯因)等。 【测试实例】 溯因推理:"如果珍妮从工作回来时发现她的房子很乱,然后想起她离开时把一扇窗户开着,她可以假设有个小偷闯入她的房子,造成了这个混乱"。 【相关模型】 ChatGPT,,GPT4, Bard等 【评估结果】
论文截图:逻辑推理测评显示归纳推理能力较差,演绎推理能力较强 LLM在抽象推理能力上存在一定的局限性。归纳推理能力较差,演绎推理能力较强,在提示工程帮助给出推理方向的情况下,演绎推理达到了90%以上准确率,而归纳推理达到66%的准确率。 另外,溯因推理是根据观察推断出最合理的解释。测试,它可以达到86.7%的准确率(30个样本中有26个正确)。 |

总结和随想
从当前论文梳理的情况来看,大语言模型表现出来一定的“推理”能力。但目前测试工作还是多”以结果论英雄”,并未重视推理的过程。没有看到从逻辑学的角度对大语言模型的推理能力进行系统化地解析。各类测试相互重叠,边界也有些模糊。
基于统计或者推理,人们都同样可以进行决策。但推理与统计本质上并不相同。虽然基于统计方法的大语言模型的“推理”结果可能达到特定产品性能需要,可以投入应用。但是必须清楚,大语言模型的“推理”并不是真正意义上的推理,是没有100%正确性的保障。
相信很快将有更多和更深入的工作出现,洞察大语言模型的相关能力与推理和逻辑学的确切关系。
主要资料来源
A Survey on Evaluation of Large Language Models. Yupeng Chang et al.
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. Yejin Bang et al.
Chain-of-Thought Prompting Elicits Reasoning in LLM, Jason Wei et al.
Is ChatGPT a General-Purpose Natural Language Processing Task Solver? Chengwei Qin et al.
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering, Zhilin Yang et al.
各类任务下未特别标注的概念示意插图皆来自互联网搜索


