
- 1Android PDF 的 读取 与 生成_android pdf解析
- 2HarmonyOS鸿蒙基于Java开发:Java UI 常用组件 WebView_harmonyos webview开发
- 3Flutter开发环境配置_flutter sdk配置
- 4元宇宙由哪些底层技术支撑?_为元宇宙网络通信提供基础支撑的是
- 5使用Android studio 运行cocos2dx-js 工程(mac)_cocos2dx-js 开发需要先编译吗
- 6AI:151-使用机器学习技术进行信用风险评估与管理
- 7【朝夕教育】2023年10月 WPF+上位机+工业互联 096-WebApi(minimalApi、AOP、鉴权)_wpf + webapi
- 8想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)_deepfacelab训练多少次合适
- 9java与sqlerver 数据库连接_java怎么连接数据库sql server
- 10Linux操作系统(一)_汇编语言实现cat /etc/passwd
Pandas数据分析及可视化应用实践_运用数据分析算法对所选取的数据集进行分析处理和可视化展示
赞
踩
Pandas是一个基于Numpy的数据分析库,它提供了多种数据统计和数据分析功能,使得数据分析人员在Python中进行数据处理变得方便快捷,接下来将使用Pandas对MovieLens 1M数据集进行相关的数据处理操作,运用具体例子更好地认识和学习Pandas在数据分析方面的独特魅力。
准备工作
首先使用Anaconda安装Jupyter Notebook,由于Jupyter支持单个文件上传,为了便于管理,可以通过upload先上传数据集的压缩包,然后通过zipfile解压数据集,解压后的数据集保存在data文件夹下,可以执行如下代码:

注:若upload无法上传数据压缩包,可以将数据压缩包放到Desktop,在Jupyter中找到Desktop文件夹,通过move移动到目标路径下。
导入Pandas,Numpy数据分析包,等待数据分析

数据读取与处理
1、Movielens数据集
MovieLens数据集是GroupLens Research收集电影评分数据集,包括100K,1M,10M等不同规模的数据集,本文选取MovieLens-1M数据集,该数据集包括6040名用户对3900部电影发布的1000209条评论数据。常用作推荐算法,数据统计数据集。
2、读取数据集
Pandas提供了多种方式来读取不同类型数据,本文使用read_csv来读取Movielens-1M各个子数据集,该方法将表格型数据读取为DataFrame对象,这是Pandas核心数据结构之一,另一个是Series。DataFrame表示的是矩阵的数据表,二维双索引数据结构,包括行索引和列索引。Series是一种一维数组型对象,仅包含一个值序列与一个索引。本文所涉及的数据结构主要是DataFrame。
函数描述|------
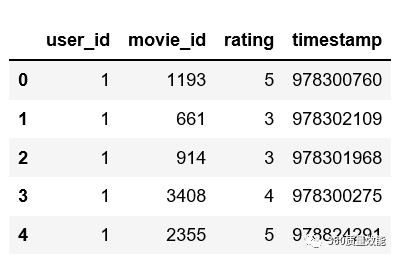
② 读取movies.dat数据集并输出前6条数据,此处自定义数据展示的条数。
movies.dat数据集movie_id:电影id,title:电影名称以及上映时间,genres:电影的题材。

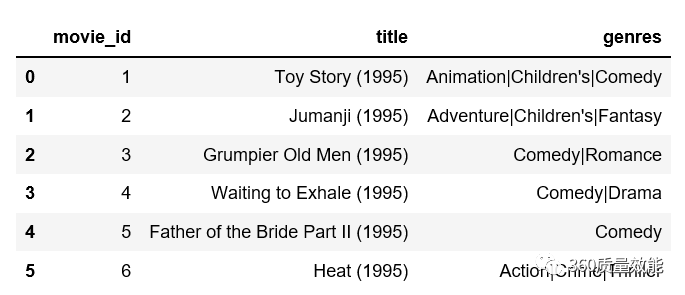
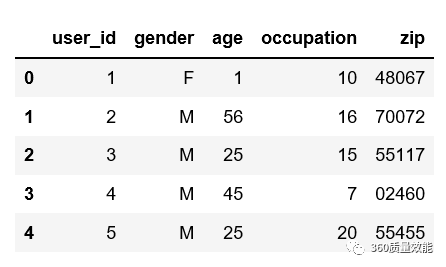
③读取users.dat子数据集,user_id:用户id,gender:用户性别,age:用户所处的年龄段,并不是具体的年龄,occupation:用户职业,zip:邮编。

注意:若有的时候数据集列数过多,无法展示多列,出现省略号,此时可以使用pandas中的set_option()进行显示设置。
若输入的数据集较大,可能需要读入文件的一个小片段或者按照小块来遍历文件。若要读取一小部分行数据,可以指明nrows。若是分块去读数据文件,可以指明chunksize作为每一块的行数。
3、数据处理
上面展示的都是子数据的原始状态,但是在数据分析过程中,原始数据可能不满足数据分析的要求,这里做一些简单的处理。
① 去掉title中的年份
通过正则表达式去掉title中的年份


② 通过Pandas中的to_datetime函数将timestamp转换成具体时间
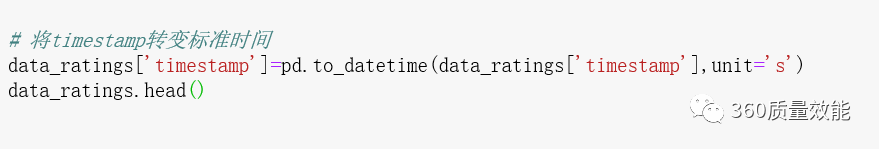
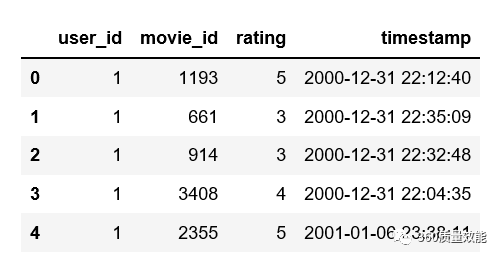
③ 通过rename函数更改列名,具体代码如下:
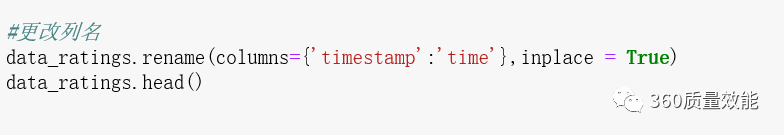
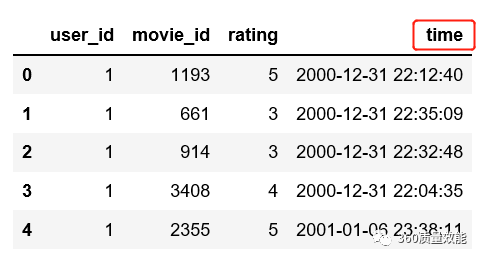
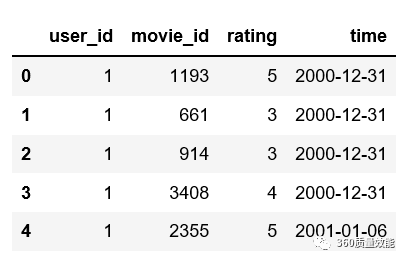
④ 将data_ratings中time列格式变成‘年-月-日’
首先使用Pandas中的to_datetime函数将date列从object格式转化为datetime格式,然后通过strftime(‘%Y%m%d’)取出年月日,把这个函数用apply lambda应用到data_ratings[‘timestamp’]的这一列中。

4、数据合并
Pandas提供merge函数合并数据集,类似于sql中的join操作,分为可设为inner(默认内连接),outer(外连接),left(左连接),right(右连接)。将data_movies与data_ratings合并成data数据集。
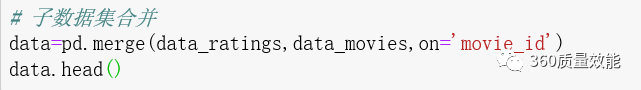
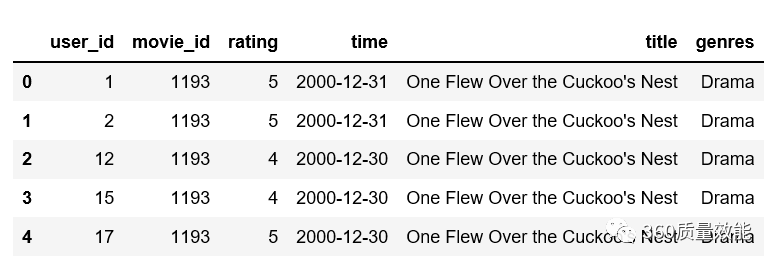
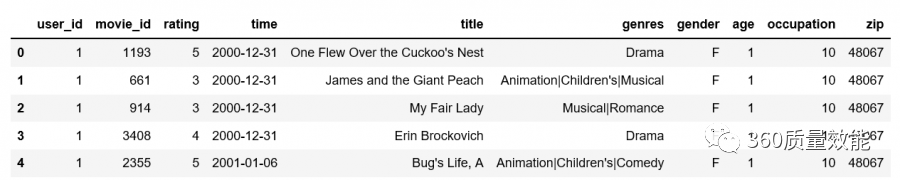
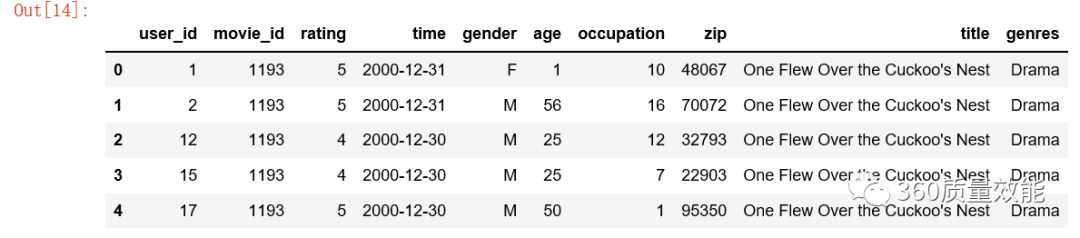
上面是将两个子数据集合并,也可以多个子数据集合并,将data_movies,data_ratings与data_users一起合并成data1,可以使用两层merge函数合并数据集,也可以使用merge函数将data与data_users合并。


数据分析
1、统计变量
变量描述|------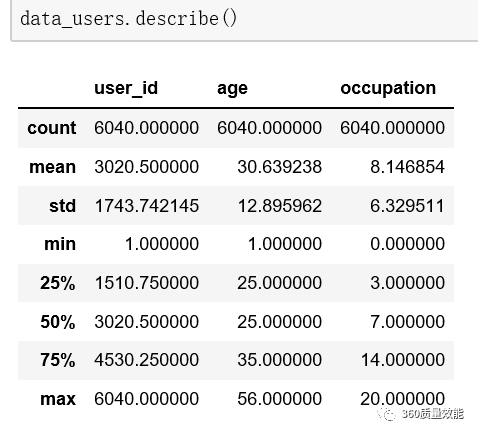
2、分组统计
Pandas中使用groupby函数进行分组统计,groupby分组实际上就是将原有的DataFrame按照groupby的字段进行划分,groupby之后可以添加计数(count)、求和(sum)、求均值(mean)等操作。
① 统计评分最多的5部电影
首先根据电影名称进行分组,然后使用size函数计算每组样本的个数,最后采用降序的方式输出前5条观测值。

② 根据用户id统计电影评分的均值
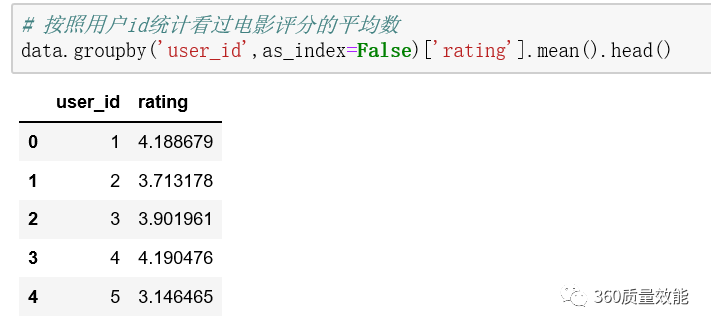
3、分组聚合统计
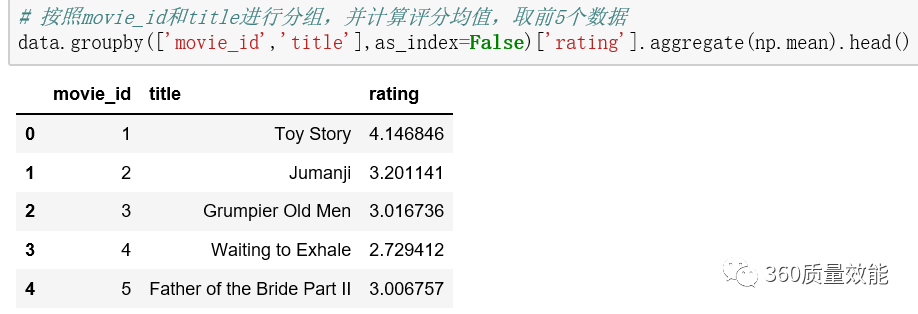
Pandas提供aggregate函数实现聚合操作,可简写为agg,可以与groupby一起使用,作用是将分组后的对象使给定的计算方法重新取值,支持按照字段分别给定不同的统计方法。
按照movie_id和title进行分组,并计算评分均值,取前5个数据。
4、使用数据透视表pivot_table获得根据性别分级的每部电影的平均电影评分
数据透视表pivot_table是一种类似groupby的操作方法,常见于EXCEL中,数据透视表按列输入数据,输出时,不断细分数据形成多个维度累计信息的二维数据表。
DataFrame.pivot_table(data, values=None, index=None, columns=None,
aggfunc='mean', fill_value=None, margins=False,
dropna=True, margins_name='All')
- 1
- 2
- 3
- 4
index : 行索引,必要参数
**values :**对目标数据进行筛选,默认是全部数据,可通过values参数设置我们想要展示的数据列。
**columns
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

