
热门标签
当前位置: article > 正文
python综合实战案例-数据分析
作者:你好赵伟 | 2024-03-29 20:53:16
赞
踩
python综合实战案例-数据分析
Python是进行数据分析的好工具,今天就是借助一个案例给大家进行数据分析讲解。
本例设计一个log.txt⽂件,该文件记录了某个项⽬中某个 api 的调⽤情况,采样时间为每分钟⼀次,包括调⽤次数、响应时间等信息,⼤约18万条数据。下⾯进⾏探索性数据分析。
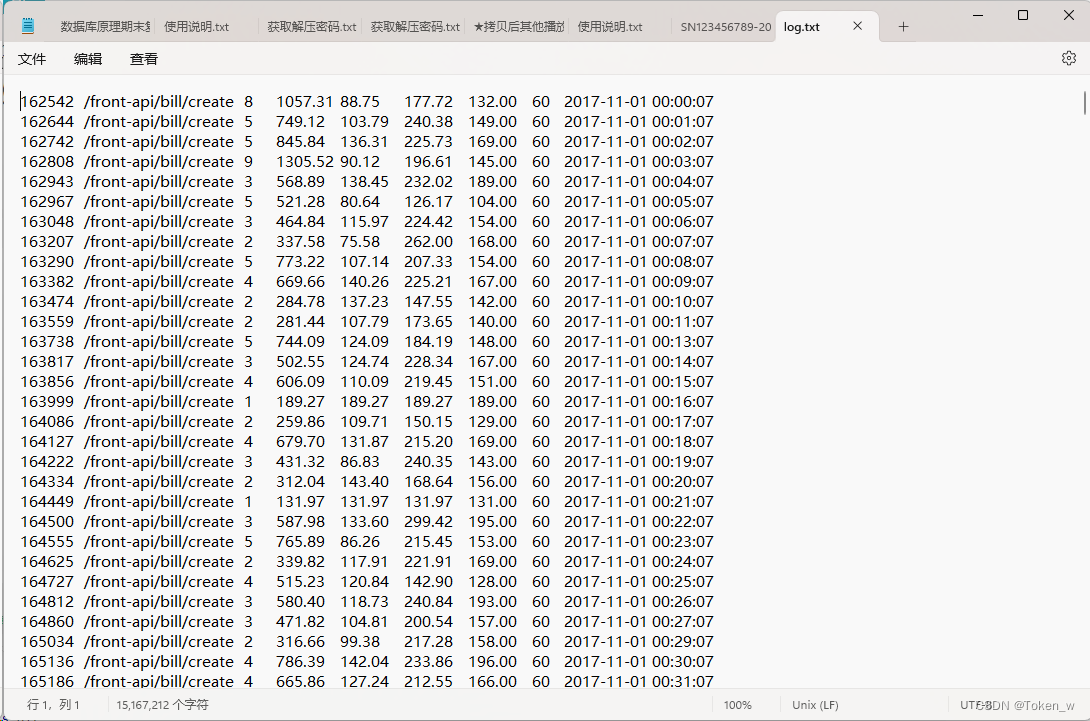
一、分析api调用次数
import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rc('font', **{'family':'SimHei'}) # 从log.txt导⼊数据 data = pd.read_table('log.txt', header=None,names=['id', 'api', 'count', 'res_time_sum', 'res_time_min','res_time_max', 'res_time_avg', 'interval', 'created_at']) # 检查是否有重复值 print( data.duplicated().sum() ) # 0 # 检查是否有空值 print( data.isnull().sum() ) # 分析 api 和 interval 这两列的数据是否对分析有⽤ print( len(data) ) # 得到 179496 print( len(data[data['interval'] == 60]) ) # 得到 179496 print( len(data[data['api'] == '/front-api/bill/create']) ) # 得到 179496 # 查看api字段信息,可以发现unique=1,也就是说只有⼀个值,所以是没有意义的 print( data['api'].describe() ) # 删除api⼀列 data = data.drop('api', axis=1) # 还发现 interval 的值全是60 print( data.interval.unique() ) # [60] # 把 id 字段都删掉 data = data.drop(['id'], axis=1) # 发现数据中每⼀⾏的 interval 字段的值都⼀样,所以丢弃这列 data2 = data.drop(columns=['interval']) print( data2.head() ) # 查看维度信息 print( data2.shape ) # (179496, 6) # 查看字段类型 print( data2.dtypes ) print( data2.info() ) print( data2.describe() ) print( "------------------------------------------" ) # 查看时间字段,会发现count=unique=179496,说明没有重复值 data2['created_at'].describe() # 选取 2018-05-01 的数据,但是没有显⽰ print( data2[data2.created_at == '2018-05-01'] ) # 这样就可以,但是这样选取毕竟挺⿇烦的 print( data2[(data2.created_at >= '2018-05-01') & (data2.created_at < '2018-05-01')] ) # 所以,将时间序列作为索引 data2.index = data2['created_at'] # 为了能 data['2018-05-01'] 这样选取数据,我们还要将时间序列由字符串转为时间索引 data2.index = pd.to_datetime(data2['created_at']) # 有了时间索引,后⾯的操作就⽅便多了 print( data2['2018-05-01'] ) print( "------------------------------------------" ) print( "------------------------------------------" ) # 分析 api 调⽤次数情况 # 下⾯直⽅图表⽰单位时间调⽤api的次数,最⼤值为31,所以就分31组 data['count'].hist(bins=31, rwidth=0.8) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
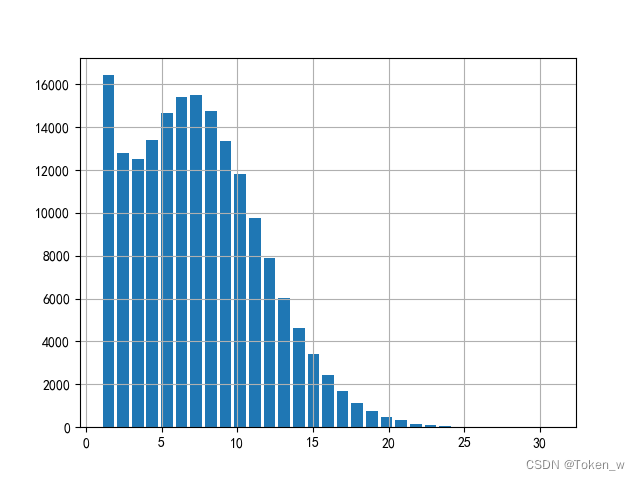
二、分析访问高峰时段
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
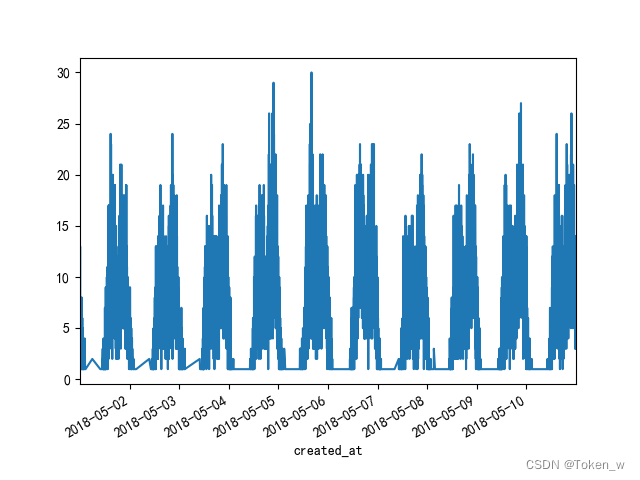
# 分析 api 调⽤次数情况,例如,在2018-5-1这⼀天中,哪些时间是访问⾼峰,哪些时间段访问⽐较少
# 如下图所⽰,从凌晨2点到11点访问少,业务⾼峰出现在下午两三点,晚上⼋九点。
data2['2018-5-1']['count'].plot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
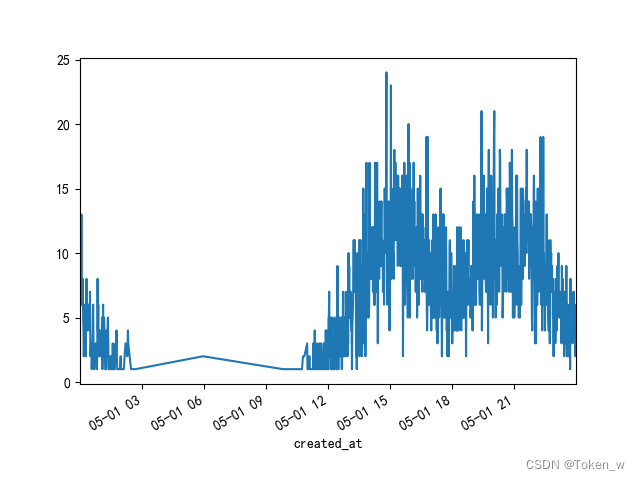
三、分析api相应时间1
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
data2['2018-5-1'].describe()
# 分析⼀天中 api 响应时间
data2['2018-5-1']['res_time_avg'].plot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
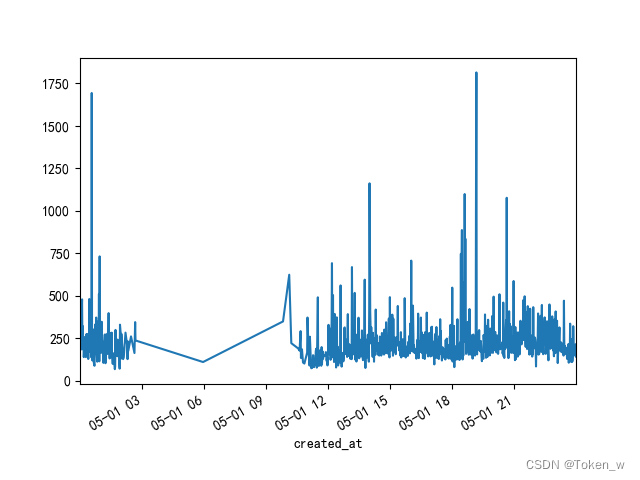
四、分析api响应时间2
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
data2['2018-5-1'][['res_time_avg']].boxplot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
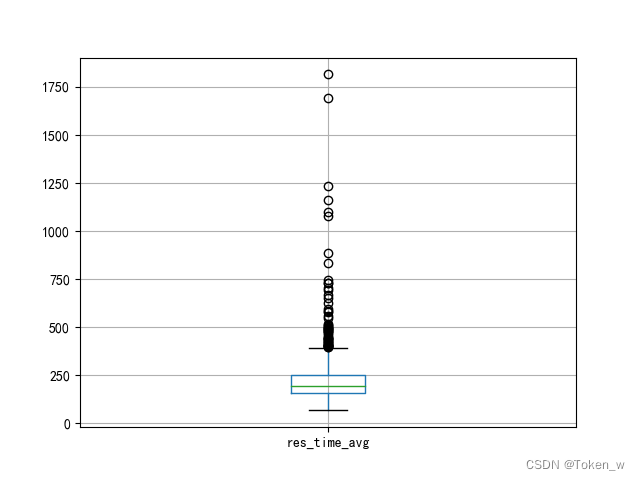
五、分析api响应时间3
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
data2['2018-5-1'][['res_time_avg']].boxplot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
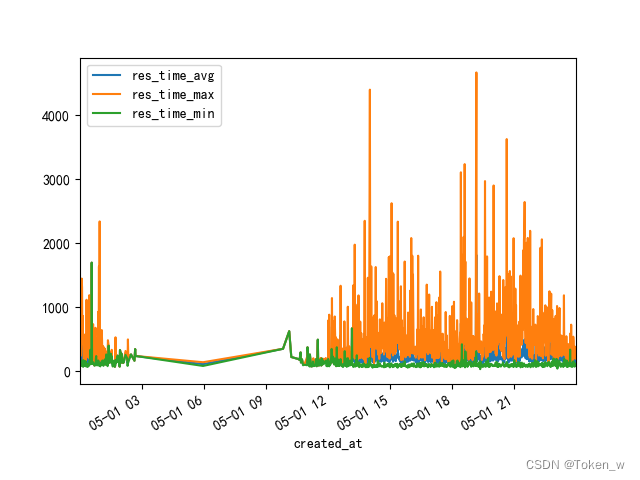
六、分析api相应时间4
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
# 以20分钟为单位重新采样,可以看到在业务⾼峰时间段,最⼤响应时间和平均响应时间都有所上升
# data2['2018-5-1'].resample('20T').mean()
# data2[['res_time_avg','res_time_max','res_time_min','res_time_sum']].plot()
data2['2018-5-1'].resample('20T').mean()
data2[['res_time_avg','res_time_max','res_time_min']].plot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
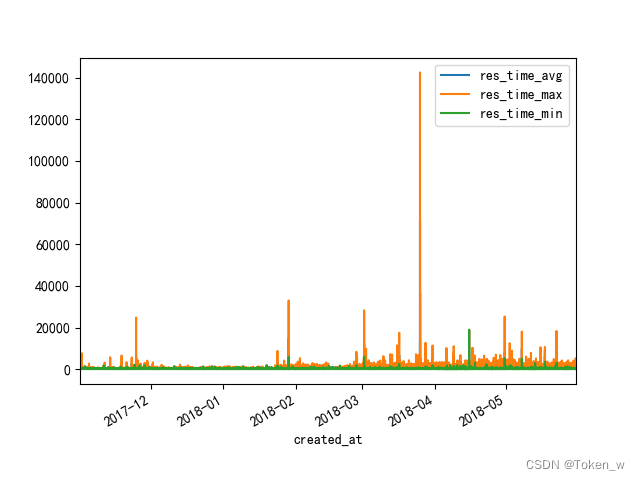
七、分析连续几天数据
# 相同代码省略
print( "------------------------------------------" )
print( "------------------------------------------" )
# 分析连续的⼏天数据,可以发现,每天的业务⾼峰时段都⽐较相似
data2['2018-5-1':'2018-5-10']['count'].plot()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
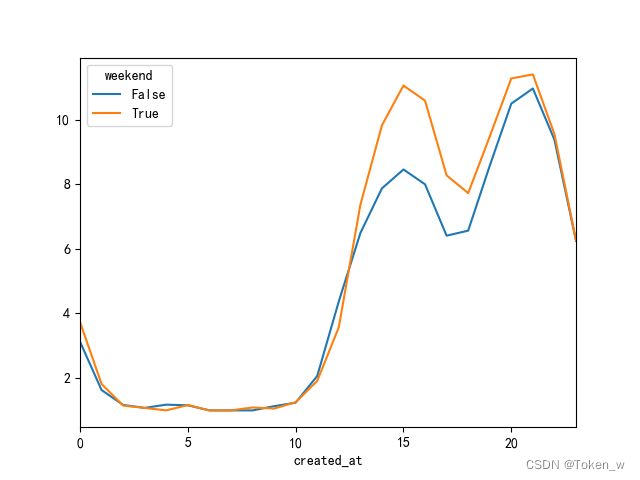
八、分析周末访问量增加情况
# 相同代码省略 print( "------------------------------------------" ) print( "------------------------------------------" ) # 分析周末访问量是否有增加 data2['weekday'] = data2.index.weekday data2.head() # weekday从0开始,5和6表⽰星期六和星期天 data2['weekend'] = data2['weekday'].isin({5,6}) data2.head() data2.groupby('weekend')['count'].mean() data2.head() #data2.groupby(['weekend', data2.index.hour])['count'].mean().plot() #plt.show() data2.groupby(['weekend', data2.index.hour])['count'].mean().unstack(level=0).plot() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
总结
根据上面的代码分析案例,进行数据分析,首先根据之前文章讲到的数据清洗,对数据进行导入、重复值检查、空值检测、数据精简处理……
通过对数据的分析、处理,我们可以清楚可视化观察到数据的变化走向,更好的通过数据分析得到结论。
python分析数据绘制图片注意的问题我们后续再讲,感谢!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/337381
推荐阅读
相关标签

