
热门标签
热门文章
- 1【毕业设计】基于单片机的智能衣柜系统设计 - 物联网 stm32 嵌入式_基于stc89c52单片机的智能衣柜系统
- 2Linux的基本使用和web项目在云服务器上的部署_4.在linux系统中发布web项目。通过浏览器测试是否能够访问到发布的web项目。 5.在
- 3技术面试问项目难题如何解决的_技术面试感觉什么都会,面试官一问回答不上来怎么办?...
- 4cvc-complex-type.2.4.a: Invalid content was found starting with element 'async-supported'. One of
- 5使用Ptr<BasicFaceRecognizer>model = EigenFaceRecognizer::create();错误_ptr
model = eigenfacerecogniz - 6关于TC264单片机与智能车摄像头循迹的一些学习心得
- 7linux中防火墙操作命令_firewall: command not found
- 8【数据结构与算法02】栈与队列_队列进栈和出栈的时间复杂度
- 9documents4j-word excel ..转pdf格式_documents4j word转pdf
- 10DVWA-SQL Injection级别通关详解_dvwa靶机sql通关
当前位置: article > 正文
pytorch报错:RuntimeError: CUDA out of memory.(CUDA内存不足)_logits = torch.matmul(flat_q.transpose(2, 3), flat
作者:Gausst松鼠会 | 2024-03-07 04:03:19
赞
踩
logits = torch.matmul(flat_q.transpose(2, 3), flat_k) runtimeerror: cuda out
查看GPU的运行状况
- 程序运行中可以通过watch -n 0.1 -d nvidia-smi命令来实时查看GPU占用情况,按Ctrl+c退出
- 通过nvidia-smi命令来查看某一时刻的GPU的占用情况
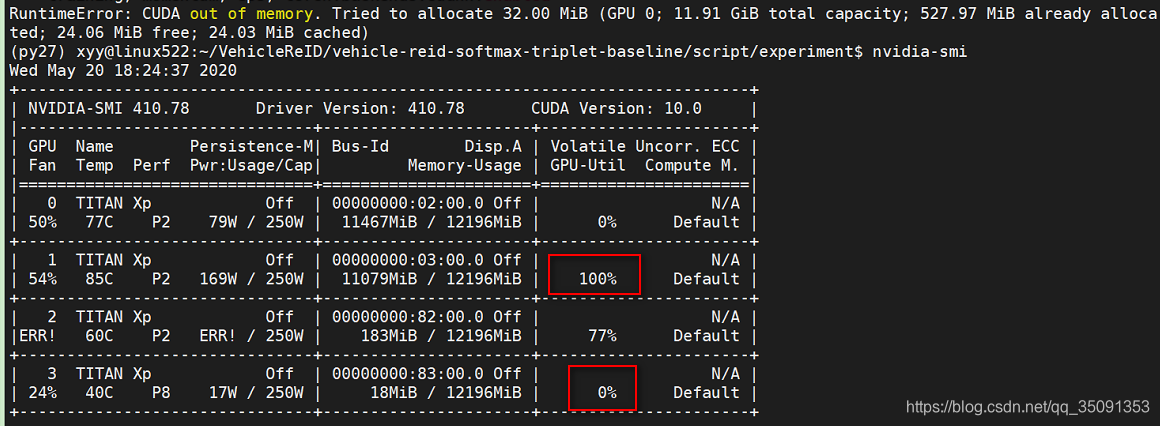
1、训练阶段
如果是训练时遇到该问题,说明模型的参数太多了,将模型的参数减少该问题就解决了,改小batch_size是不能解决的(我将batch_size设为1都没解决,而且报错时的内存数据都没变),因此,出现这个问题,应该有三个原因:
- GPU还有其他进程占用显存,导致本进程无法分配到足够的显存
- 缓存过多,使用torch.cuda.empty_cache()清理缓存(没试过)
- 卡不行,换块显存更大的卡吧(因为服务器上有4个显卡,所以,选择了序号为3的显卡进行实验)
2、测试阶段
如果是测试时遇到该问题,在测试代码前面加上:with torch.no_grad():
with torch.no_grad():
# test process
- 1
- 2
3、GPU显存未释放问题
若使用了上述两种方法还不成功,那么我们就需要手动释放那些已经不需要的进程(这些进程占据着GPU的资源)
我们在使用tensorflow+pycharm 或者PyTorch写程序的时候, 有时候会在控制台终止掉正在运行的程序,但是有时候程序已经结束了,nvidia-smi也看到没有程序了,但是GPU的内存并没有释放,这是怎么回事呢?
使用PyTorch设置多线程(threads)进行数据读取(DataLoader),其实是假的多线程,他是开了N个子进程(PID都连着)进行模拟多线程工作,所以你的程序跑完或者中途kill掉主进程的话,子进程的GPU显存并不会被释放,需要手动一个一个kill才行,具体方法描述如下:
- 1.先关闭ssh(或者shell)窗口,退出重新登录
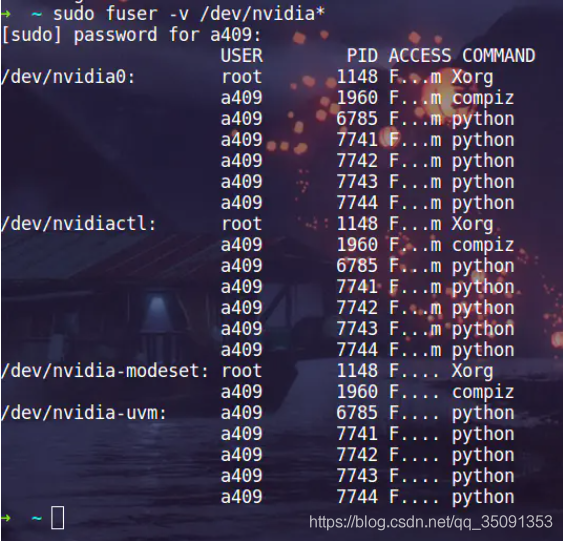
- 2.查看运行在gpu上的所有程序:
fuser -v /dev/nvidia*
- 1
- 3.kill掉所有(连号的)僵尸进程
具体操作步骤如下:
- 我们可以用如下命令查看 nvidia-smi看不到的GPU进程。
nvidia-smi
- 1
发现内存泄露问题,即没有进程时,内存被占用
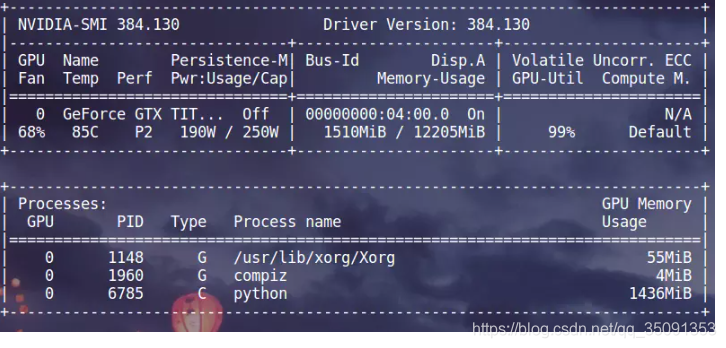
- 发现僵尸进程(连号的)
fuser -v /dev/nvidia*
- 1
- 查看具体这个进程调用GPU的情况
pmap -d PID
- 1
- 强行关掉所有当前并未执行的僵尸进程
kill -9 PID
- 1
参考1:https://blog.csdn.net/weixin_38314865/article/details/105998844
参考2:https://www.jianshu.com/p/0d8ea6ca332a
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/203423
推荐阅读
相关标签

