
热门标签
热门文章
- 1Whale 帷幄创始人叶生晅:AIGC 时代,营销的范式变了丨未来 AI 谈
- 2【OpenCV+OCR】计算机视觉:识别图像验证码中指定颜色文字
- 3java调用chatgpt接口,实现专属于自己的人工智能助手
- 4postman自动化测试如何设置环境变量教程
- 5华为OD机试题【篮球比赛】用 C++ 进行编码 (2023.Q1)_华为机考篮球比赛吃+
- 6字节跳动程序媛教你如何刷算法题:面试手撕代码我就没怕过_手撕代码不会怎么办
- 7探索 C# 中的程序运行目录获取方法
- 8商用车第一张,比亚迪引领汽车智能网联安全合规新趋势_比亚迪数据安全管理体系
- 9postman官网下载安装登录测试详细教程
- 10Stable-Diffusion|从图片反推prompt的工具:Tagger(五)_在线tagger反推
当前位置: article > 正文
Python_微博热搜&保存数据库_微博热搜数据库
作者:算法编织者 | 2024-02-03 15:22:23
赞
踩
微博热搜数据库
本文章通过两种保存模式:csv文件、Mysql数据库
目录
实现效果如图:
Mysql数据库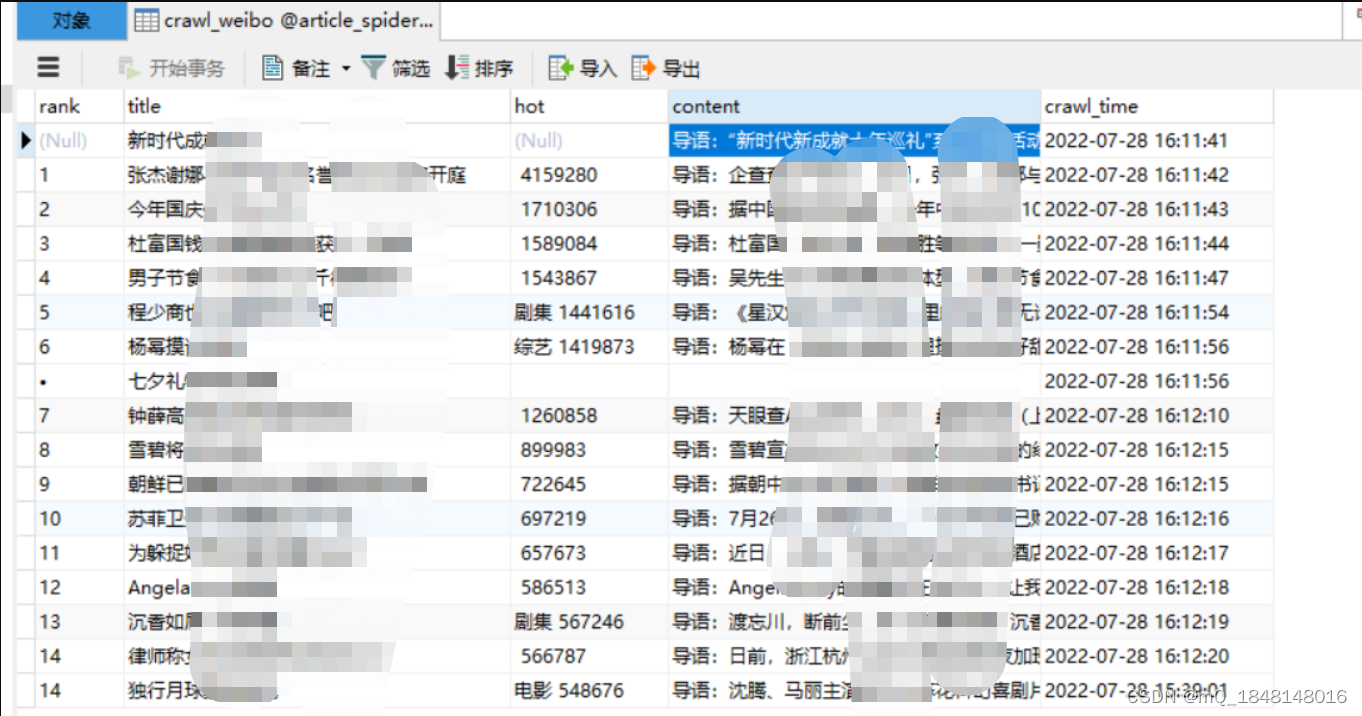
一、导入的模块
- # 请求模块
- import requests
- # 数据解析模块
- import parsel
- # csv模块
- import csv
- # 解析xpath数据
- from lxml import etree
- # Mysql数据库
- from pymysql import *
- # 获取当前时间
- import datetime
二、请求数据及发送数据
抓取到这个包后要提取出cookie及user_agent.

- # 请求网址
- url = 'https://s.weibo.com/top/summary?cate=realtimehot'
- # 请求头伪装
- headers = {
- # 用户信息,常用于检测是否有登陆账号
- 'cookie': 'SINAGLOBAL=7937404926931.249.1636464635344; UM_distinctid=17f2703fd68a04-0bab97066d76a7-b7a1b38-144000-17f2703fd69b9a; _s_tentry=www.google.com; Apache=7622137159879.738.1658974841979; ULV=1658974841984:18:1:1:7622137159879.738.1658974841979:1654582588849; login_sid_t=202fe80fe56d14cc0f16efb902e5ea28; cross_origin_proto=SSL; SCF=AkDb37fbylKlxUz0nDM7_r_svEEQmTEpkUnvdkGWHpo07aipJQEMqhirljndvz5wo6lbLvXIeS2eK0Tz2hjlqm4.; ariaDefaultTheme=undefined; ariaMouseten=null; ariaStatus=false; SUBP=0033WrSXqPxfM72wWs9jqgMF55529P9D9WWE-XFkVMDPj6Dil2V2rMDY5JpVF020SK-ce0.pShn7; webim_unReadCount=%7B%22time%22%3A1658980416385%2C%22dm_pub_total%22%3A0%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A0%2C%22msgbox%22%3A0%7D; SUB=_2AkMVvq5QdcPxrARSnvsczmnqa4xH-jyma8emAn7uJhMyAxh87mwGqSVutBF-XFs_2PBC2NmYIWsqsFsk7X8raSk-; PC_TOKEN=71860c5fd4; UOR=www.google.com,weibo.com,www.google.com',
- # 用户代理,表示浏览器基本身份标识
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
- }
- # 发送请求
- response = requests.get(url=url, headers=headers)
三、解析数据
- # 转数据类型
- selector = parsel.Selector(response.text)
- # 第一次提取 css选择器 获取所有标签数据内容
- trs = selector.css('#pl_top_realtimehot tbody tr')
四、提取数据
- for tr in trs:
- params =list()
- rank = tr.css('.td-01::text').get()
- title = tr.css('.td-02 a::text').get()
- hot = tr.css('.td-02 span::text').get()
- detail_url = 'https://s.weibo.com/'+tr.css('.td-02 a::attr(href)').get()
- detail_response = requests.get(url=detail_url,headers=headers)
- page_text = detail_response.text
- tree = etree.HTML(page_text)
- content = tree.xpath('//*[@id="pl_feedlist_index"]/div[2]/div/p/text()')
- content=''.join(content)
- dit = {
- '排名': rank,
- '标题': title,
- '热度': hot,
- '内容': content,
- '爬取时间':datetime.datetime.now()
- }
- params.append(rank)
- params.append(title)
- params.append(hot)
- params.append(content)
- params.append(datetime.datetime.now())

五、保存数据
1、Mysql数据库存储
- # 接上个for循环代码,将数据存储到Mysql库
- try:
- # 创建一个游标对象,进行数据库操作
- cur = conn.cursor()
- insersql = "insert into crawl_weibo(rank,title,hot,content,crawl_time) value(%s,%s,%s,%s,%s)ON DUPLICATE KEY UPDATE title=VALUES(title)"
- cur.execute(insersql,tuple(params))
- conn.commit()
- except Exception as ex:
- print(ex)
2、 csv文件存储
csv_writer.writerow(dit)
六、代码补充
Mysql
- # 创建数据库连接
- conn = connect(host='localhost', user='root', password='123456', database='article_spider',
- port=3306,charset='utf8')
csv
- # 创建csv文件
- f = open('微博热搜.csv', mode='a', encoding='utf-8', newline='')
- # 配置文件
- csv_writer = csv.DictWriter(f,fieldnames=['排名','标题','热度','内容','爬取时间'])
- # 写入表头
- csv_writer.writeheader()
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57158
推荐阅读




相关标签

