
热门标签
热门文章
- 1BLIP-2:低计算视觉-语言预训练大模型
- 2ubuntu配置 pytouch_ubantu怎么打开pytouch
- 3AWS | IAM | 获取与用户或角色关联的策略
- 4【Linux】nginx+mysql+php搭建博客----教程(php7.2版本)_安装yum-utils
- 5unity场景优化
- 6留学生怎么合理使用ChatGPT ?还有哪些同类工具可以使用?
- 7Python知识点总结
- 8XGBoost的改进----Lightgbm_xgboost 直方图
- 9LAN技术 -- MAC地址表、端口安全_获取lan口mac地址
- 102024年金三银四必备面试题之自动化测试面试题及答案大全_自动化测试面试问题及答案
当前位置: article > 正文
python爬去新浪微博_荐爬虫实战 新浪微博爬取 详细分析
作者:tf789 | 2024-02-03 14:54:17
赞
踩
python爬新浪微博内容
目标
#2020.5.22
#author:pmy
#目标:爬取最爱的绵羊的微博,包含时间,文本内容,点赞数,评论数与转发数
#在更换博主时主要在于修改headers中的referer和参数中的containerid
分析
首先要简单讲一下Ajax。它是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
它具体体现在:
在刷微博时,我们能明显能发现,当一个页面划完,就能出现新的画面,新的内容,而此时,网页并没有刷新。
Ajax在网页中的请求类型是xhr,在其中便可以找到每次往下划获得的信息。它响应的内容是JSON格式,很方便操作,可以说是十分方便了。
具体的在我们要抓取的网页中怎么看xhr,怎么获得JSON响应呢。下面我们就来看。
我们这里爬取的是我最近最喜欢的b站up主绵羊料理的新浪微博,最喜欢大姨了嘿嘿。
我们从微博手机端网页版进入,要爬取的网页地址为:https://m.weibo.cn/profile/1733152694
往下划,查看网络:
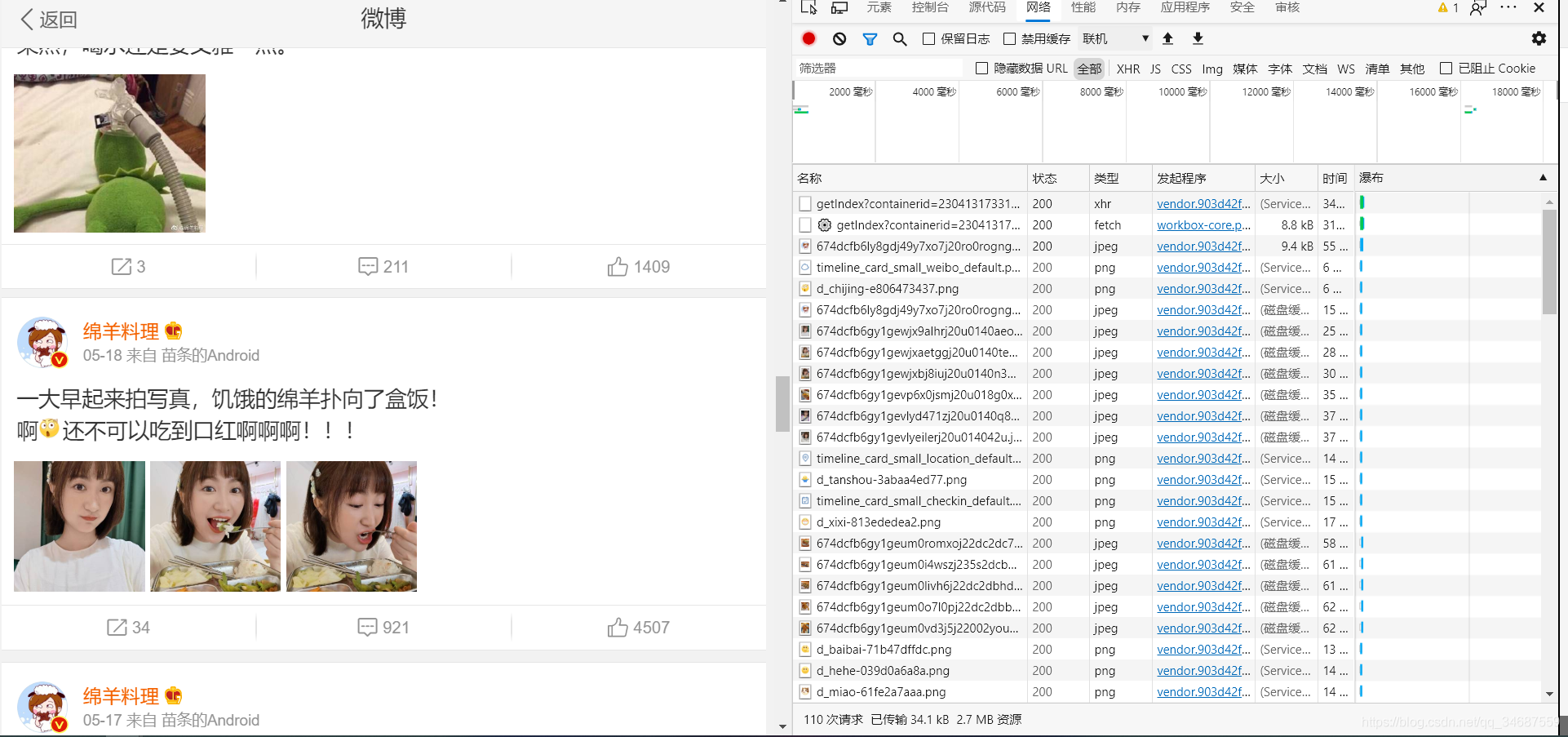
发现没有之前那种适合我们爬取的html文档,那么将筛选器选择XHR呢。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57020
推荐阅读




相关标签

