- 1copilot 产生 python工具函数并生成单元测试
- 2终极解决python安装包时需要Microsoft Visual C++ 14.0的问题_microsoft visual c++ 14.0的安装
- 3Tomcat 优化
- 42023年最新Java八股文面试题,面试应该是够用了(吊打面试官)
- 52-4《学生食堂信息管理系统》饭卡管理模块_录入时间列(register_date)默认值为当前录入时间
- 6STM32F103C8T6+LD3320语音识别模块智能灯控
- 7架构设计(一) 架构演变_业务维度拆分属于水平拆分吗
- 8SpringCloud微服务常见问题
- 9JAVA(SpringBoot)对接微信登录_java对接微信登录
- 10astilectron之Go语言golang的图形界面_go-astilectron
Python实现爬取移动端网页版微博用户信息及(部分)粉丝和(部分)关注信息(一)_无法获得所有用户页,怎么爬取关注数
赞
踩
电脑端网页版微博weibo.com的处理相对复杂,先从最简单的移动端weibo.cn开始。因为微博系统限制,移动端只能查看前20页关注和粉丝信息,所以对于关注或粉丝超过200的用户,只能获取部分粉丝和部分关注的信息。
用户主页的链接有3种形式
www.weibo.cn/uid
www.weibo.cn/u/uid
www.weibo.cn/个性域名
- 1
- 2
- 3
1. UID

所以打开用户主页的时候链接不一定含有UID,还需要重新获取。方法就是获取这个标签href的属性值
<a href="/1744395855/info">资料</a>
- 1
查找这一标签与一般的查找稍有不同,因为只能确定标签名是a,属性名是href,属性值的第一个字符是/,最后五个字符是/info,中间的数字正是我们要查找的内容。这是正则表达式表现的时间,恰好BeautifulSoup的查找函数支持正则表达式。
from bs4 import BeautifulSoup as bs
import regex # 正则表达式
def getUid(soup: bs):
"""
soup是用户主页html解析的结果,BeautifulSoup的实例
"""
addr = soup.find(name='a', attrs={'href', regex.compile(r"/\S*/info")})
if addr:
return addr['href'].split('/')[1]
print('uid 查找失败')
return None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2. 基本信息
进入用户资料页,URL很有特点:
weibo.cn/uid/info
- 1
进入资料页面的前提是得到uid,所以上一步非常重要。
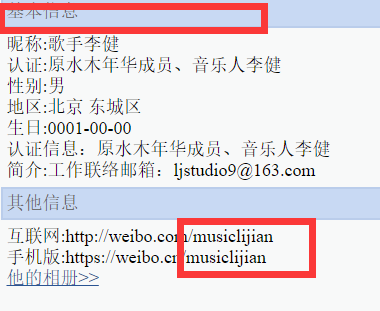
资料页面包含了用户的基本信息和个性域名。页面显示的都是基本的文本,在同一个标签下,用<br>换行分隔。从基本信息的规律发现,信息的排版规律,均为(除了认证信息)“属性:属性值”的格式。利用find(text=*)函数可以查找对应文本。所以定义一个函数获得这些内容(除生日,需特殊处理)。
basicInfoType = {'nickname': '昵称', 'identity': '认证', 'sex': '性别', 'location': '地区', 'description': '简介' } def getBasicInfo(soup: bs, infoType: str) -> str: """ soup是信息页html解析返回结果,BeautifulSoup的实例 infoType: 昵称, 认证, 性别, 地区, 简介 """ if infoType.lower() not in basicInfoType: raise ValueError('wrong basic infomation type\n' + str(basicInfoType)) pattern = basicInfoType[infoType] + ':*' infoSection = soup.find(text=regex.compile(pattern)) if infoSection: info = infoSection.split(':')[1:] basicInfo = '' for item in info: basicInfo += item return basicInfo return ''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这里也用了正则表达式来匹配一行文字。
在这一页中,获得文本的方法基本相同,仅仅是一些项要多处理一次。个性域名信息与前面方法一致——找到个性域名URL所在的行,对文本进行“/”分割。字符串"手机版:https://weibo.cn/个性域名"进行“/”分割后得到列表[“手机版https:”, “”, “weibo.cn”, “个性域名”],个性域名是该列表的最后一个元素,用索引-1取出即可。实际上,假如一个用户没有设置个性域名,那么在“其他信息”这一栏将会出现:
电脑版:http://weibo.com/u/uid
手机版:https://weibo.cn/u/uid
- 1
- 2
这种情况下,分割字符串得到的列表元素个数为5。因此,正确获得个性域名的前提是列表元素个数是4。
def getCustomDomain(soup):
"""
soup是信息页html解析返回结果,BeautifulSoup的实例
"""
addr = soup.find(text=regex.compile(r"手机版:https://weibo.cn/*"))
#print(addr)
if addr:
if len(urlSection := addr.split('/')) == 4:
return urlSection[-1]
return ''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
NOTE: 上面的代码使用了“:=”运算符。“:=”运算符称作海象运算符(walrus operator),是Python 3.8的新特性。海象运算符不仅能让代码更简洁和增加可读性,还能提高运算速度。该运算符的作用是把右边表达式的值赋值给左边的变量,左边的变量还能进行下一步运算。以判断列表元素是否大于5,如果大于5则输出元素个数为例
# a是一个列表
# 以前的写法
n = len(a)
if n > 5:
print(n)
# 或者
if len(a) > 5:
print(len(a))
# 海象运算符的写法
if (n := len(a)) > 5:
print(n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
例子说明应用海象运算符可以减少代码或避免重复调用。另一个有趣的例子是
print((a:=(1+(b:=2+(c:=3+(d:=4+(e:=5+6))))))<5) # False
print(a,b,c,d,e) # 21 20 18 15 11
- 1
- 2
获得出生日期的方法基本相同,不过需要添加额外的判断,简单判断是否是有效的日期,判断日期形式(年、年-月、年-月-日、月-日)
def getBirthdate(soup):
"""
soup是信息页html解析的返回结果,BeautifulSoup的实例
"""
date = soup.find(text=regex.compile(r"生日:*"))
if date:
dateBlock = date.split(':')[-1].split('-')
if len(dateBlock) == 3:
return int(dateBlock[0]), int(dateBlock[1]), int(dateBlock[2])
if len(dateBlock) == 2:
return int(dateBlock[0]), int(dateBlock[1])
if len(dateBlock) == 1:
return int(dateBlock[0])
return None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
主页和资料页信息抓取代码如下
def getUserHomepageInfo(person, mobile=False): # mobile用来注明是否是移动端网页 homeURL = homepageUrl(person, mobile) print(homeURL) soup = getHtml(url=homeURL, headers=header) if uid := getUid(soup): person.uid = uid person.realFansNum = soup.find(name='a', attrs={'href': '/'+person.oid+'/fans'}).text.split('[')[1][:-1] person.realFocusNum = soup.find(name='a', attrs={'href': '/'+person.oid+'/follow'}).text.split('[')[1][:-1] infoURL = infoPageUrl(person) infoSoup = getHtml(url=infoURL, headers=header) if (customDomain := getCustomDomain(infoSoup)): person.CustomDomain = customDomain if (date := getBirthdate(infoSoup)): try: if len(date) == 3: person.birthYear, person.birthMonth, person.birthDay = date if len(date) == 2: if date[0] > 12: person.birthYear, person.birthMonth = date else: person.birthMonth, person.birthDay = date if len(date) == 1: person.birthYear = date except: pass if (name := getBasicInfo(infoSoup, 'nickname')): person.name = name if (identity := getBasicInfo(infoSoup, 'identity')): person.identity = identity if (sex := getBasicInfo(infoSoup, 'sex')): person.sex = sex if (description := getBasicInfo(infoSoup, 'description')): person.description = description if (location := getBasicInfo(infoSoup, 'location')): person.location = location print(person.name + " 主页信息抓取成功\n-----------------------------------------------")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
3. 关注和粉丝
关注和粉丝信息的页面结构相同,所以只要写一个函数就可以完成两个类似的任务。首先分析URL的特点,打开任意一个移动端网页版微博的关注页和粉丝页。关注URL,有以下两种形式
关注: https://weibo.cn/uid/follow?page=页码
粉丝: https://weibo.cn/uid/fans?page=页码
- 1
- 2
很容易就能打开相应的页面。再来看系统允许我们查看多少页
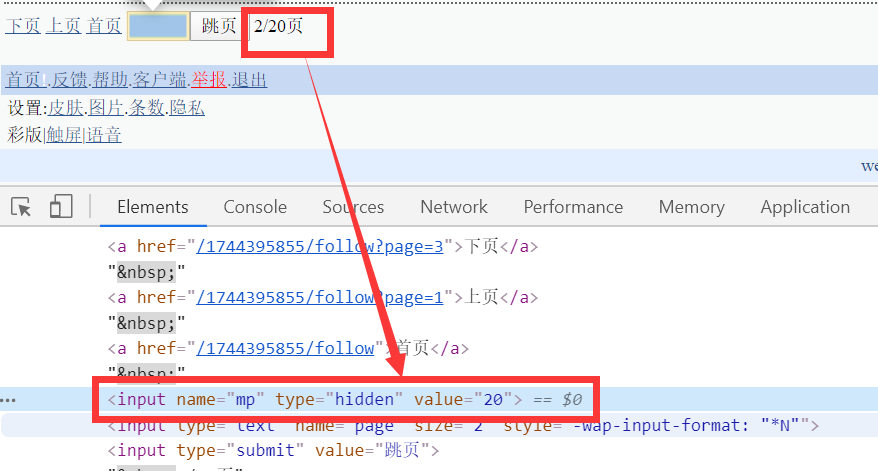
写一个函数获得可以迭代的次数
def getPageNum(soup):
"""
soup是关注页或粉丝页html的解析的返回结果,BeautifulSoup的实例
"""
return int(soup.find(name='input', attrs={'name': 'mp'})['value'])
- 1
- 2
- 3
- 4
- 5
同样地,F12检查
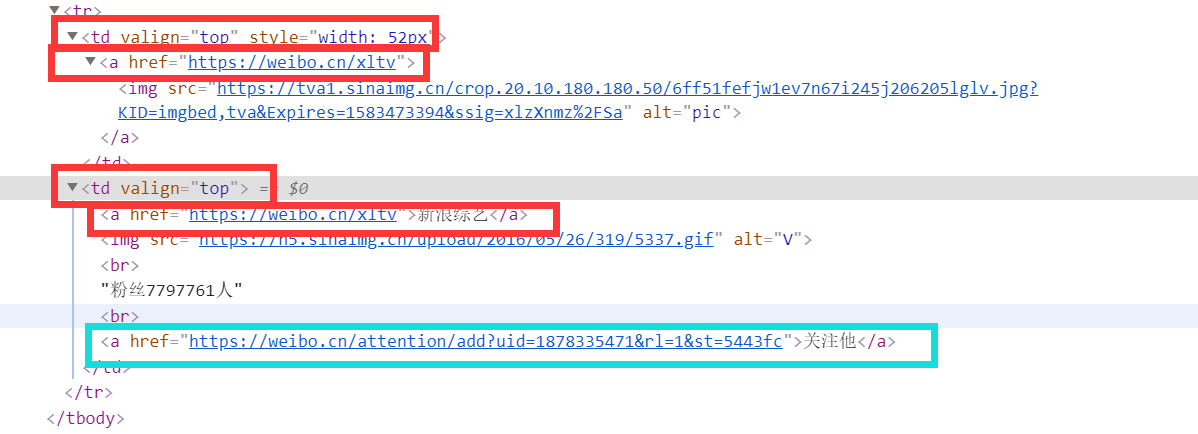
每一个用户的主页链接出现两次(红色方框),并且父标签都是<td>、属性都是valign=“top”,所以每个关注(粉丝)用户信息出现两次。获取的方法比较简单,用findAll函数找出所有标签,后以step=2逐个提取。从红色方框中也能看到,用户主页URL不一定包含UID(优先展示个性域名),所以第一步获得UID很重要。其实这里使用了一种麻烦的方法,因为每条信息都出现两次。观察图中第一个<td>标签,它还有style="width: 52px"属性。还有一个更简单的方案是蓝色方框的内容,这个表情是“关注他”按钮的链接,每个用户只出现一次,而且链接中已经包含了uid。如果利用这个标签的信息,第一步获取uid就是不必要的。
利用红色方框标签信息代码
def getRelation(person, relation, mobile=False): if not (relation := relation.lower()) in ['focus', 'fans']: raise ValueError('参数必须是 [\'focus\',\'fans\']') if relation == 'focus': pageUrlFunc = focusPageUrl addFunc = person.addFocus else: pageUrlFunc = fansPageUrl addFunc = person.addFans url = pageUrlFunc(person, 1, mobile) soup = getHtml(url=url, headers=header) pageNum = getPageNum(soup) for page in range(1, pageNum+1): url = pageUrlFunc(person, page, mobile) soup = getHtml(url=url, headers=header) blank = ' ' if page < 10 else '' print('正在抓取第', str(page)+blank, '页信息') memberList = soup.findAll(name='td', attrs={'valign': 'top'}) for i in range(1, len(memberList), 2): memberInfo = memberList[i].find(name='a') name = memberInfo.text uid = memberInfo['href'].split('/')[-1] addFunc(WeiboUser(name=name, uid=uid)) print(person.name + ': ' + relation + " 信息抓取成功\n-------------------------------------------")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4. 基本链接和HTML
def homepageUrl(person, mobile=False): if mobile: pofix = '' if person.uid: pofix = person.uid elif person.customDomain: pofix = person.customDomain else: raise RuntimeError('缺少必要信息') return 'https://weibo.cn/' + pofix if oid := person.oid: return 'https://www.weibo.com/u/' + oid if pid := person.pageId: return 'https://www.weibo.com/p/' + pid if domain := person.customDomain: return 'https://www.weibo.com/' + domain def focusPageUrl(person, page=1, mobile=False): if mobile: return 'https://weibo.cn/' + person.uid + '/follow?page=' + str(page) return 'https://weibo.com/p/' + person.pageId + '/follow?page=' + str(page) def fansPageUrl(person, page=1, mobile=False): if mobile: return 'https://weibo.cn/' + person.uid + '/fans?page=' + str(page) return 'https://weibo.com/p/' + person.pageId + '/follow?relate=fans&page=' + str(page) def getHtml(url, headers): response = requests.get(url=url, headers=headers) if (html := response.text): return bs(html, 'lxml') print('无内容,正在重新请求') getHtml(url, headers)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
getHtml函数接收URL和请求头,返回经过BeautifulSoup实例。因为不登录微博,我们看不到用户的关注,所以请求头里应该包含登录信息,cookie正是包含登录信息的一项。打开浏览器登录微博,按F12进入开发者工具,选中网络(Network)
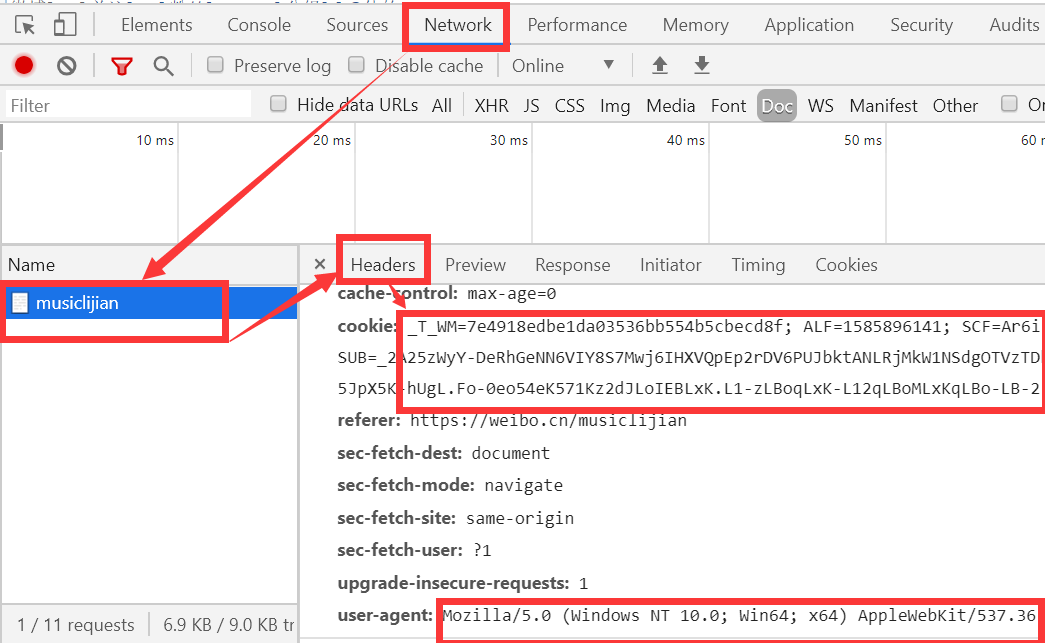
把cookie所有内容保存下来。为了模拟浏览器浏览,把user-agent也保存下来。
cookie = '**************'
userAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ****'
header = {'User-Agent': userAgent,
'cookie': cookie
}
- 1
- 2
- 3
- 4
- 5
除此之外,getHtml函数还可能进入递归。有时候因为各种原因,请求没有响应。getHtml函数调用自身相当于可以多请求几次直到有返回结果。但是没必要一直请求(python也不允许一直递归,不能超过递归深度),设置递归深度可以实现这一功能,在文件的开头设置
import sys
sys.setrecursionlimit(10) #设置递归深度
- 1
- 2
在程序最后,恢复默认递归深度(998)。(递归深度10时,matplotlib包导入失败)
sys.setrecursionlimit(998)
- 1
高频地请求可能会导致访问被限制,在getHtml函数里添加命令,使每次请求前暂停一段时间,模拟人的操作。
import time
pauseTime = 1 # 1秒
def getHtml(url, headers):
# *** 其他 ***
time.sleep(pauseTime)
# *** 其他 ***
- 1
- 2
- 3
- 4
- 5
- 6
5. 数据保存
使用类作为用户的模板可以提高代码的可读性,每创建一个用户的时候只要创建一个实例。准备工作已经实现微博用户类的创建。
6. 完整代码
import requests from bs4 import BeautifulSoup as bs from Person import WeiboUser # 准备工作 import regex import time import sys import os sys.setrecursionlimit(10) # 设置递归深度,不必多次请求同一个页面 pauseTime = 1 basicInfoType = {'nickname': '昵称', 'identity': '认证', 'sex': '性别', 'location': '地区', 'description': '简介' } cookie = '************************************' userAgent = '********************************' header = {'User-Agent': userAgent, 'cookie': cookie } def homepageUrl(person, mobile=False): if mobile: pofix = '' if person.uid: pofix = person.uid elif person.customDomain: pofix = person.customDomain else: raise RuntimeError('neccessary information is needed') return 'https://weibo.cn/' + pofix if oid := person.oid: return 'https://www.weibo.com/u/' + oid if pid := person.pageId: return 'https://www.weibo.com/p/' + pid if domain := person.customDomain: return 'https://www.weibo.com/' + domain def focusPageUrl(person, page=1, mobile=False): if mobile: return 'https://weibo.cn/' + person.oid + '/follow?page=' + str(page) return 'https://weibo.com/p/' + person.pageId + '/follow?page=' + str(page) def fansPageUrl(person, page=1, mobile=False): if mobile: return 'https://weibo.cn/' + person.oid + '/fans?page=' + str(page) return 'https://weibo.com/p/' + person.pageId + '/follow?relate=fans&page=' + str(page) def getHtml(url, headers): time.sleep(pauseTime) response = requests.get(url=url, headers=headers) if (html := response.text): return bs(html, 'lxml') print('无内容,正在重新请求') getHtml(url, headers) def getInfoFromText(soup, tagName, attrs): return soup.find(name=tagName, attrs=attrs).text def getInfoFromAttr(soup, searchTagName, searchAttr, targetedAttrName): return soup.find(name=searchTagName, attrs=searchAttr)[targetedAttrName].text def getPageNum(soup): return int(soup.find(name='input', attrs={'name': 'mp'})['value']) def getUid(soup): addr = soup.find(name='a', attrs={'href': regex.compile(r"\S*/info")}) print(addr) if addr: return addr['href'].split('/')[1] print('uid查找失败 跳过') return None def infoPageUrl(person): return 'https://weibo.cn/' + person.uid + '/info' def getCustomDomain(soup): """ soup: html of info page """ addr = soup.find(text=regex.compile(r"手机版:https://weibo.cn/*")) #print(addr) if addr: if len(urlSection := addr.split('/')) == 4: return urlSection[-1] return '' def getBirthdate(soup): """ html of info page """ date = soup.find(text=regex.compile(r"生日:*")) if date: dateBlock = date.split(':')[-1].split('-') if len(dateBlock) == 3: return int(dateBlock[0]), int(dateBlock[1]), int(dateBlock[2]) if len(dateBlock) == 2: return int(dateBlock[0]), int(dateBlock[1]) if len(dateBlock) == 1: return int(dateBlock[0]) return None def getBasicInfo(soup, infoType): """ html of info page infoType: 昵称, 认证, 性别, 地区, 简介 """ if infoType.lower() not in basicInfoType: raise ValueError('wrong basic infomation type\n' + str(basicInfoType)) pattern = basicInfoType[infoType] + ':*' infoSection = soup.find(text=regex.compile(pattern)) if infoSection: info = infoSection.split(':')[1:] basicInfo = '' for item in info: basicInfo += item return basicInfo return '' def getUserHomepageInfo(person, mobile=False): # mobile用来注明是否是移动端网页 homeURL = homepageUrl(person, mobile) print(homeURL) soup = getHtml(url=homeURL, headers=header) if uid := getUid(soup): person.uid = uid person.realFansNum = soup.find(name='a', attrs={'href': '/'+person.oid+'/fans'}).text.split('[')[1][:-1] person.realFocusNum = soup.find(name='a', attrs={'href': '/'+person.oid+'/follow'}).text.split('[')[1][:-1] infoURL = infoPageUrl(person) infoSoup = getHtml(url=infoURL, headers=header) if (customDomain := getCustomDomain(infoSoup)): person.CustomDomain = customDomain if (date := getBirthdate(infoSoup)): try: if len(date) == 3: person.birthYear, person.birthMonth, person.birthDay = date if len(date) == 2: if date[0] > 12: person.birthYear, person.birthMonth = date else: person.birthMonth, person.birthDay = date if len(date) == 1: person.birthYear = date except: pass if (name := getBasicInfo(infoSoup, 'nickname')): person.name = name if (identity := getBasicInfo(infoSoup, 'identity')): person.identity = identity if (sex := getBasicInfo(infoSoup, 'sex')): person.sex = sex if (description := getBasicInfo(infoSoup, 'description')): person.description = description if (location := getBasicInfo(infoSoup, 'location')): person.location = location print(person.name + " 主页信息抓取成功\n-----------------------------------------------") def getRelation(person, relation, mobile=False): if not (relation := relation.lower()) in ['focus', 'fans']: raise ValueError('argument relation must be in [\'focus\',\'fans\']') if relation == 'focus': pageUrlFunc = focusPageUrl addFunc = person.addFocus else: pageUrlFunc = fansPageUrl addFunc = person.addFans url = pageUrlFunc(person, 1, mobile) soup = getHtml(url=url, headers=header) pageNum = getPageNum(soup) for page in range(1, pageNum+1): url = pageUrlFunc(person, page, mobile) soup = getHtml(url=url, headers=header) blank = ' ' if page < 10 else '' print('正在抓取第', str(page)+blank, '页信息') memberList = soup.findAll(name='td', attrs={'valign': 'top'}) for i in range(1, len(memberList), 2): memberInfo = memberList[i].find(name='a') name = memberInfo.text uid = memberInfo['href'].split('/')[-1] addFunc(WeiboUser(name=name, uid=uid)) print(person.name + ': ' + relation + " 信息抓取成功\n-------------------------------------------") def userInformation(person, mobile=True): getUserHomepageInfo(person, mobile) getRelation(person, 'focus', mobile) getRelation(person, 'fans', mobile) def test(person, func, mobile=True): url = func(person, mobile=mobile) return getHtml(url, header) lijian = WeiboUser(uid = '1744395855') userInformation(lijian) sys.setrecursionlimit(998)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
尽管如此,有时候访问还是被限制。暂停时间设置为2秒或以上使得获取数据很慢。在技术上应该可以通过以下方式改进:
- 使用代理。不断地更换ip
- 使用多个账号。不断更换cookie
- 更换User-Agent。不断更改user-agent,fakeuseragent包提供该功能。
7. 测试
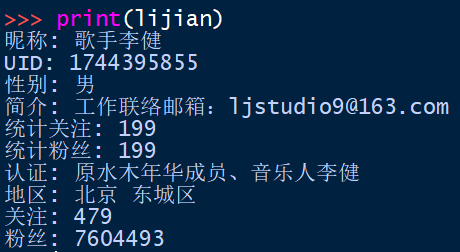
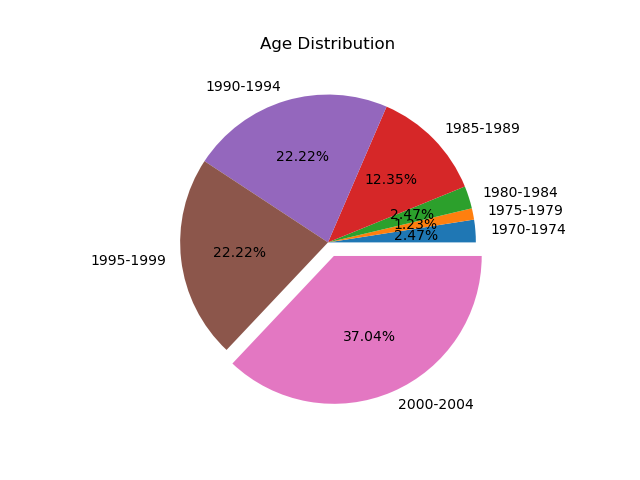
从获得的199个粉丝数据中统计性别比例,其中有130个信息填写为女性
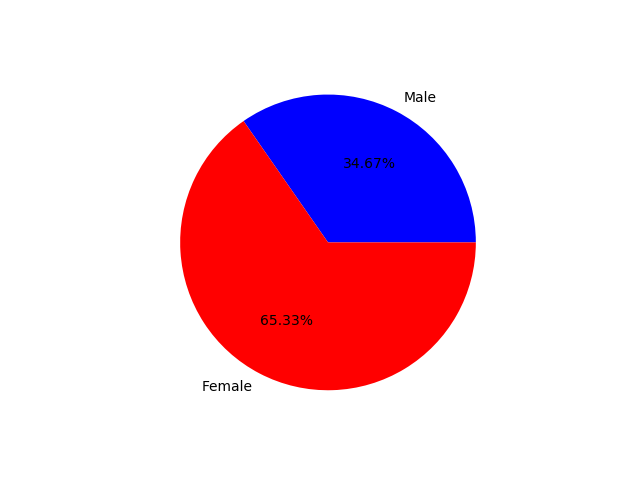
说明在最新的199个粉丝中,女性粉丝占比比较大。

从199个粉丝中统计填写了生日并且出生年份在1970-2005的人数,00-04年龄段最多,号称90后和号称00后的最多。但在这组统计中只有81个有效的数据。