
热门标签
热门文章
- 1C#调用C++OpenCV直方图匹配
- 2Vue项目的基础搭建和解决Vue中的跨域问题_packjson"vue":{ "devserver":{ "port":8888, "open":
- 3104、基于STM32单片机两轮自动平衡小车蓝牙APP控制 加超声波避障和跟随模式设计OLED屏显示(程序+原理图+PCB源文件+硬件芯片资料等)_基于单片机的自平衡小车控制原理
- 4Proxmox VE 7.0的高级安装及系统盘分区-ZFS(中)_pve zfs
- 5盘点国内热门AI大模型_国内ai大模型有哪些
- 6Docker本地部署Firefox火狐浏览器并远程访问_docker远程浏览器
- 7【网络安全】——区块链安全和共识机制_在共识方面上的缺点非常明显,首先就是去中心化程度,容易出现强者恒强的情况,持币
- 8php怎么调用c语言dll,PHP调用C语言扩展
- 9从零开始构建第一个Flink项目_从零开始flink sql
- 10Nacos鉴权和配置加密—官方原版_nacos.core.auth.server.identity.key
当前位置: article > 正文
TensorFlow实战 keras调用多GPU训练模型_tensorflow2.0怎么导入multi_gpu_model
作者:编程谜题解决者 | 2024-02-01 12:27:15
赞
踩
tensorflow2.0怎么导入multi_gpu_model
参考博客:https://blog.csdn.net/lscelory/article/details/83579062
服务器中有多个GPU,选择特定的GPU运行程序可在程序运行命令前使用:CUDA_VISIBLE_DEVICES=0命令。0为服务器中的GPU编号,可以为0, 1, 2, 3等,表明对程序可见的GPU编号。
设置示例: 在python程序中,
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
- 1
- 2
CUDA_VISIBLE_DEVICES=1 # 只有编号为1的GPU对程序是可见的,在代码中gpu[0]指的就是这块儿GPU
CUDA_VISIBLE_DEVICES=0,2,3 # 只有编号为0,2,3的GPU对程序是可见的,在代码中gpu[0]指的是第0块儿,
# gpu[1]指的是第2块儿,gpu[2]指的是第3块儿
CUDA_VISIBLE_DEVICES=2,0,3 # 只有编号为0,2,3的GPU对程序是可见的,但是在代码中gpu[0]指的是第2块儿,
# gpu[1]指的是第0块儿,gpu[2]指的是第3块儿
---------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
临时设置:
Linux: export CUDA_VISIBLE_DEVICES=1
windows: set CUDA_VISIBLE_DEVICES=1
- 1
- 2
- List item
利用多块GPU加速训练模型
如果只是单纯设置机器识别到GPU的话,并不能真正利用GPU加速,反而只是白白占用GPU资源。keras在使用GPU有个特点,就是默认占满全部内存。假如机器有多个GPU,这里比如这里有两张显卡,开始训练后,在命令行输入nvidia-smi,就会当前显卡使用情况,
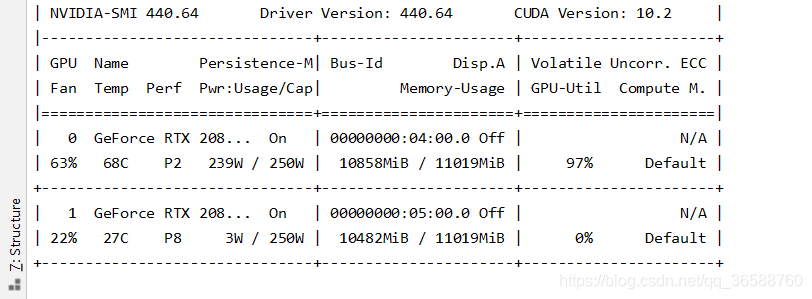
可以看到两张GPU都被占满了,但是只用了第一片GPU计算,第二片白白浪费掉(如果是租的,那可是白花花的银子啊)。
没有指定keras默认会选择所有的GPU,如果你并没有配置多GPU的训练,那么实际上keras占了所有的GPU但是实际上只在一个GPU上运行。
如何用多GPU加速计算
利用多个GPU同时训练分数据并行和模型并行两种:
- 数据并行 每块 GPU 负责一部分数据,所有 GPU 共享同一模型权重; 适合数据规模大、单 GPU 可容纳完整模型的场景;
- 模型并行
每块 GPU 负责一部分模型,所有 GPU 共享同一批数据; 适合模型参数量大,单 GPU 无法容纳的场景; - 混合方式
兼有上面两种特点,适合特殊模型场景。
————————————————————————————————————————————
这里只介绍数据并行。用到的方法是multi_gpu_model函数
multi_gpu_model
model = KerasModel()
par_model = keras- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/53776?site
推荐阅读

相关标签

