- 1华为云云耀云服务器L实例评测|Python Selenium加Chrome Driver构建UI自动化测试实践_华为浏览器driver
- 2使用Flutter的image_picker插件实现设备的相册的访问和拍照
- 3[点云学习] 一、点云相关知识了解
- 4HarmonyOS云开发基础认证【最新题库 满分答案】
- 5aigc修复美颜学习笔记
- 6Java 算法篇-深入了解单链表的反转(实现:用 5 种方式来具体实现)
- 7华为 ensp SSL VPN 史诗级配置
- 8如何解决大模型的「幻觉」问题
- 9【动态规划】【广度优先搜索】LeetCode:2617 网格图中最少访问的格子数
- 10视觉机械臂自主抓取全流程_机械臂视觉抓取
用 tensorflow.js 做了一个动漫分类的功能(一)_tensorflow页面的示例动画
赞
踩
前言:
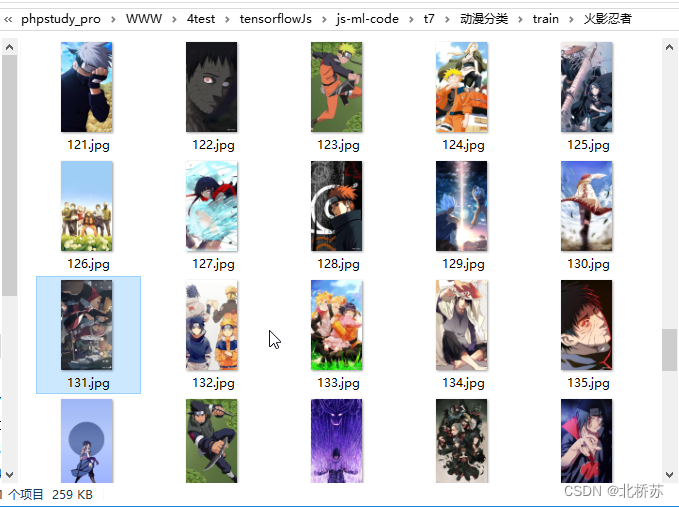
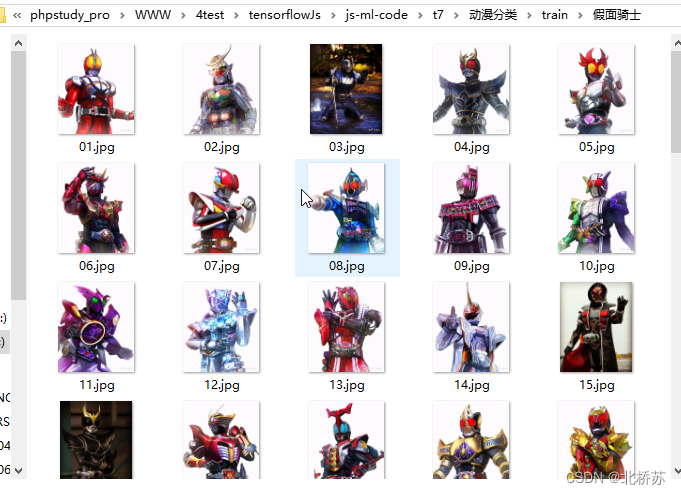
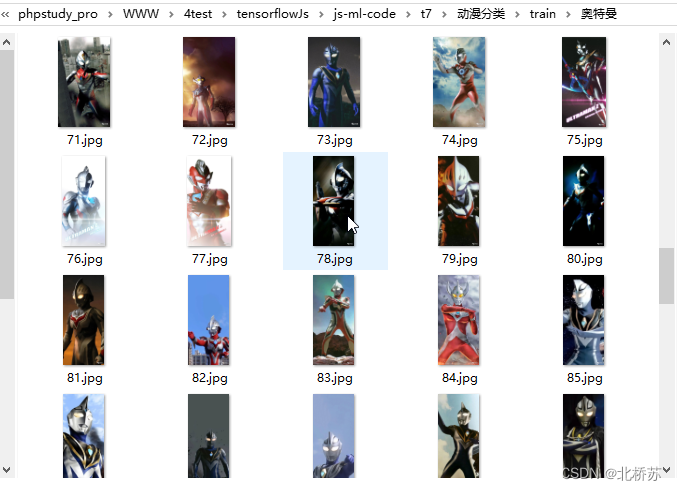
浏览某乎网站时发现了一个分享各种图片的博主,于是我顺手就保存了一些。但是一张一张的保存实在太麻烦了,于是我就想要某虫的手段来处理。这样保存的确是很快,但是他不识图片内容,最近又看了 mobileNet 的预训练模型,想着能让程序自己对图片分类,以下就通过例子从内容采集到分类的过程。
内容和资源的采集,反手就是某虫了。在网络上,经过近几年的营销渲染,可能首选是用 Python 做脚本。而这次是用 PHP 的 QueryList 来做采集,下面也就是采集的编码过程和踩坑解决方法,最后再对采集图片进行标注和训练。
环境:
PHP7.4
QueryList4.0
QueryList-CurlMulti
编码:
以下例子是基于 TP5.1,所以只需要安装上面两个依赖包。采集启动通过自定义命令实现,接下来分别以普通采集和多线程采集两种方式展示。
1. 普通采集

2. 多线程采集
问题解决:
由于普通采集的请求使用 GuzzleHttp 客户端,而多线程采集是 CURL,所以运行时报 curl 状态码 60 错误。
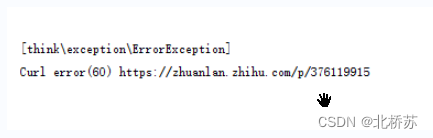
1. 解决方法:
(1). 下载 cacert
下载地址:https://curl.haxx.se/ca/cacert.pem
(2). 修改 php.ini , 并重启
在 php.ini 中找到 curl.cainfo 改为文件的绝对路径如:curl.cainfo =E:\2setsoft\1dev\phpstudy_pro\Extensions\php\php7.4.3nts\cacert.pem
图片训练:
以上的图片已经采集的差不多了,因为博主的图片有限,我也没有再去其他地方找,整个文件夹下的图片在 200 张左右。按理说图片当然是越多越好,但是整个分类标注起来耗时(看文章的配图,应该已经知道有哪几类了吧),所以就这样了。最后就是读取图片转换 Tensor 进行训练,后一篇再具体介绍吧,提醒一下。下一篇需要提前安装 Node, Http-Server,Parcel 工具。