
- 1小发猫火车头插件【php源码】_火车头插件大全
- 2Unity之TimeLine自定义_unity程序调用timelineasset
- 3Kafka教程(一)---------------kafka环境的部署(单机版/集群版)_kafka自带(zk)单机搭建
- 4AttributeError: module 'cv2.cv2' has no attribute 'face' 模块'cv2.cv2'没有属性'face'_attributeerror: module 'cv2' has no attribute 'fac
- 5Embedded Browser(ZFBrowser)使用相关问题(不安全证书链接)_zfbrowser不能播放视频
- 62023年美赛C题 预测Wordle结果Predicting Wordle Results这题太简单了吧_eerie在2023年3月1日玩家猜测次数预测结果
- 7python opencv kcf_pybind11—目标跟踪demo(KCF,python version)
- 8vue+element实现动态表格:根据后台返回的属性名和字段动态生成可变表格_后端返回前端动态表格
- 9Unity RenderStreaming 云渲染3.1.0-exp.6 食用手册_unity云渲染教程
- 10粗糙集matlab,粗糙集理论权重确定方法用matlab实现
支持向量机简介
赞
踩
支持向量机(SVM)是一类非常经典的算法,在深度学习成为主流之前,曾一度统治着机器学习界。支持向量机就是要在两个类别中找到一条分隔边界,这条分隔边界可以很好的分开两个类别,并且这个边界到两个类别的距离是最大的。其中两个类别中到这条边界最近的向量叫做支持向量。如下图所示:
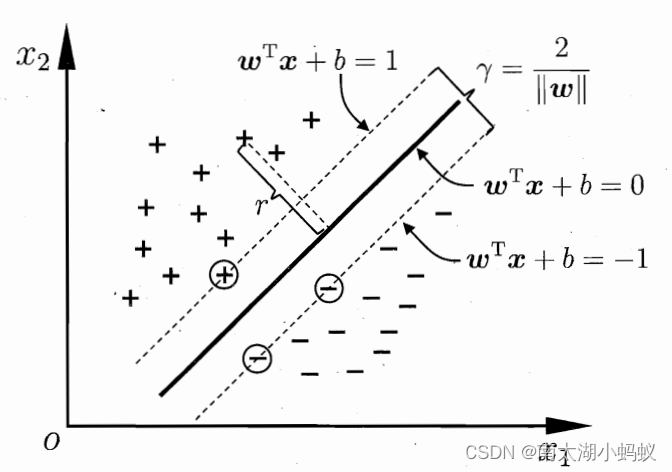
支持向量机一般分为三种:线性可分支持向量机,线性支持向量机(也叫软间隔支持向量机,近似线性可分支持向量机),非线性支持向量机。
一般我们所说的就是线性可分支持向量机,事实上,现实生活中更多的是近似线性可分的情况。所谓的“软间隔”就是允许某些样本不满足约束条件,但是在最大化间隔的同时,不满足约束的样本应该尽可能少。

而非线性支持向量机,就是指两个类别的间隔不再是一条直线,而是非线性的,如下图所示:
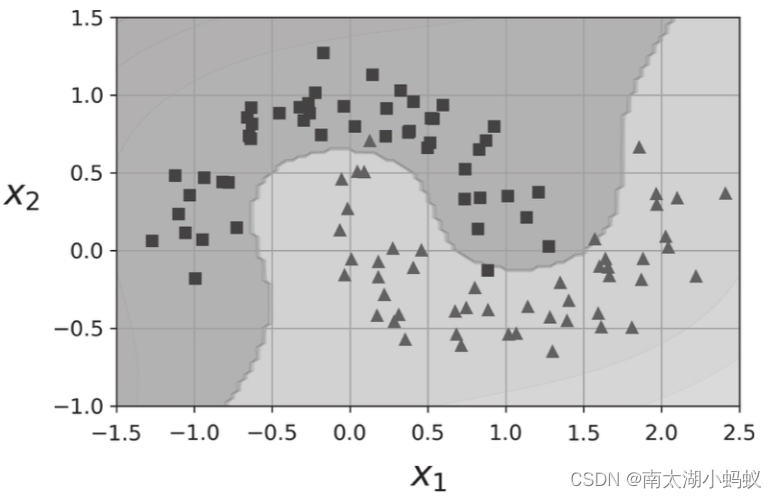
由于支持向量机算法比较复杂,涉及数学知识较多,我这次就直接用sklearn实现了,从应用角度出发,数学原理方面的内容可以参考周志华的《机器学习》和李航的《统计学习方法》,里面讲的很清楚。
下面我们通过具体的程序来熟悉一下支持向量机的使用方法。首先,从sklearn自带的鸢尾花数据集开始:
- import numpy as np
- from sklearn import datasets
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import StandardScaler
- from sklearn.svm import LinearSVC
-
- iris = datasets.load_iris()
- X = iris["data"][:,(2,3)] # 长度,宽度
- y = (iris["target"]==2).astype(np.float64) # 第二种类型的鸢尾花
- svm_clf = Pipeline([("scaler", StandardScaler()),
- ("linear_svc", LinearSVC(C=1, loss="hinge"))]) # pipeline是一种类似流水线的机制
- # LinearSVC,代表线性支持向量机,C是一个用来进行正则化的参数,C越小,错分会越多,
- # 但是泛化性较好;C越大,错分越少,但容易过拟合,
- # hinge损失函数
- svm_clf.fit(X,y)
-
- # 预测
- svm_clf.predict([[5.5,1.7]])
- # 输出:array([1.])

这里我们使用鸢尾花的长度和宽度特征来训练,标签值为是否是第二种类型的鸢尾花,1代表是,0代表否。使用pipeline机制对特征进行标准化,然后使用一个线性支持向量机来学习。可以看到,预测时候,给出特定的鸢尾花长度和宽度,即可判断该鸢尾花是否是第二种鸢尾花类型。
上次我们在介绍逻辑回归的时候使用过手写数字识别数据集,现在用支持向量机SVM来试试结果如何。
- from sklearn.svm import SVC
-
- digits = datasets.load_digits()
- x = digits['data']
- y = digits['target']
- svm_clf = SVC(kernel="poly",max_iter=1000) # 采用多项式核函数训练
-
- svm_clf.fit(x,y)
-
- # 预测
- x0 = x[5].reshape(1,-1)
- print(svm_clf.predict(x0))
- print(y[5])
- # 输出:[5] 5
我这里采用了支持向量机分类器来训练,SVC是通用的支持向量机分类器,可以通过指定参数kernel来设置所使用的核函数,SVC支持的核函数有以下几种:
’linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:高斯核函数
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵,表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵,核矩阵需要为n*n的。
我这里选择了多项式核函数进行训练。预测值为5,真实值也是5,可以看到预测的结果还是比较准确的。
- import matplotlib.pyplot as plt
- plt.imshow(digits['images'][5],cmap='gray') # 显示出数字图像
- plt.show()

下面我们尝试一下非线性数据集,看看sklearn效果如何。我们先用sklearn自带的make_moons()函数生成数据集并可视化。
- from sklearn.datasets import make_moons
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import PolynomialFeatures
- from matplotlib import pyplot as plt
-
- X,y = make_moons(n_samples=100, noise=0.15)
- print(X.shape)
- print(y.shape)
- # 输出:
- # (100, 2)
- # (100,)
- plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
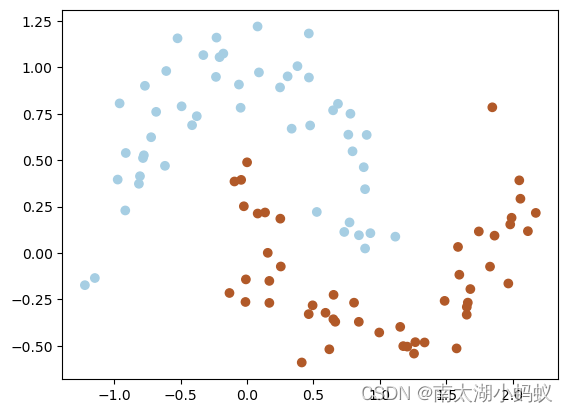
可见,模拟了100个数据,X的维度是(100,2),100行2列,我们把一列作为纵坐标,一列作为横坐标,y作为颜色值区分类型,画出了图形,可以看到有很明显的非线性特征,无法用一条直线将两个数据集分开。
下面我们尝试用支持向量机分隔两类数据。
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import StandardScaler
- from sklearn.svm import LinearSVC
- from sklearn.svm import SVC
- svm_clf = Pipeline([("poly_features", PolynomialFeatures(degree=3)),
- ("sclaer",StandardScaler()),("svm_clf",LinearSVC(C=10, loss="hinge"))])
-
- svm_clf.fit(X,y)
这里我用了一个多项式回归特征,degree=3代表了生成的是三次多项式,最后通过线性SVC来进行训练,C是一个惩罚变量,如果C越大,分类会越精确但是可能存在过拟合的情况,C越小相当于允许犯错,泛化能力较强。我们把训练后的结果用等高线contourf画出来,可以清晰的看到分隔边界。np.meshgrid根据给出的x坐标点和y坐标点生成更多的点,用每个x去和每个y分别配对,得到更多的坐标,然后去预测得到结果,把结果z作为高度,画出等高线,也就得到了分隔边界。
- # 生成两个坐标轴的范围,生成密集可以看得更清楚
- x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
- y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
- h=0.01
- print(np.arange(y_min,y_max,h).shape) # 输出:(282,)
- xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
- print(xx.shape) # 输出:(282, 440)
- print(yy.shape) # 输出:(282, 440)
- # ravel表示把数组拉成一维数组,np.c_表示把按列拼接两个矩阵
- z=svm_clf.predict(np.c_[xx.ravel(),yy.ravel()])
- z=z.reshape(xx.shape) # 转换成跟xx一样的维度
- plt.contourf(xx, yy, z, cmap=plt.cm.Paired, alpha=0.8) # 按z来画出决策边界
- plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired) # 按y来画出原始数据的散点图
- plt.show()
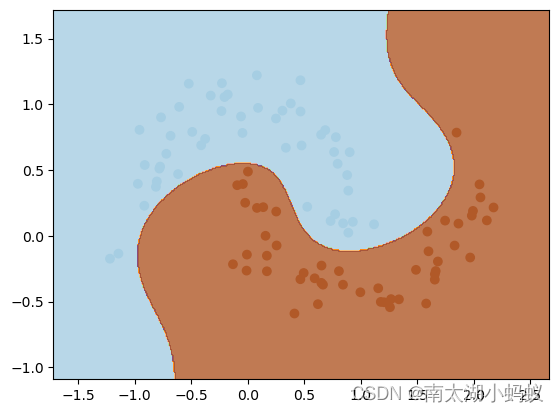
可以看到,划分的还是比较准确的。
如果采用高斯核函数的话,看看决策边界是怎么样的。
- rbf_svm_clf = Pipeline([("sclaer",StandardScaler()),
- ("svm_clf",SVC(kernel="rbf", gamma=5, C=0.001))])
- rbf_svm_clf.fit(X,y)
- # 生成两个坐标轴的范围,生成密集可以看得更清楚
- x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
- y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
- h=0.01
- print(np.arange(y_min,y_max,h).shape)
- xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
- print(xx.shape)
- print(yy.shape)
- # ravel表示把数组拉成一维数组,np.c_表示把按列拼接两个矩阵
- z=rbf_svm_clf.predict(np.c_[xx.ravel(),yy.ravel()])
- z=z.reshape(xx.shape) # 转换成跟xx一样的维度
- plt.contourf(xx, yy, z, cmap=plt.cm.Paired, alpha=0.8) # 按z来画出决策边界
- plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired) # 按y来画出原始数据的散点图
- plt.show()
gamma类似于C,也是一个正则项参数,只对核函数是rbf和sigmoid时生效。gamma越大越容易过拟合。画出决策边界,如下图所示:
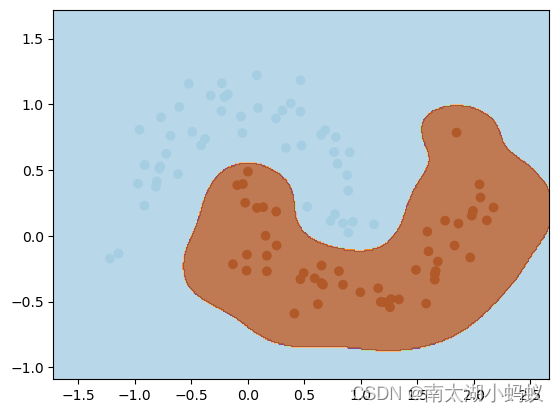
可以看到,gamma值越大,模型越倾向于准确划分每个训练数据,从而会导致过拟合的问题,所以需要通过C来做正则化,在精度和泛化性中做权衡。
最后,我们尝试用sklearn提供的人脸数据集实现一个简单的人脸识别程序,看看SVM的效果。
- from sklearn.datasets import fetch_lfw_people
-
- lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
- n_samples, h, w = lfw_people.images.shape
- n_samples,h,w # 输出:(1288, 50, 37)
-
- X = lfw_people.data
- n_features = X.shape[1]
- # the label to predict is the id of the person
- y = lfw_people.target
- target_names = lfw_people.target_names
- n_classes = target_names.shape[0]
-
- print("Total dataset size:")
- print("n_samples: %d" % n_samples)
- print("n_features: %d" % n_features)
- print("n_classes: %d" % n_classes)
- # 输出:
- Total dataset size:
- n_samples: 1288
- n_features: 1850
- n_classes: 7
由于LFW数据比较大,所以并不能像鸢尾花数据集iris那样直接导入,需要额外下载,如果下载不了可以百度搜索一下,通过国内的某些链接来进行下载和部署。
下载后就可以正常使用了。可以看到人脸数据集一共有1288张图像,经过处理后的大小为50*37=1850个像素。类别为7类,也就是7个人。下面列出数据集中的前10张图片以及标签,也就是人名。
- import matplotlib.pyplot as plt
-
- fig = plt.figure(figsize=(20,20))
- for i in range(1,11):
- ax = fig.add_subplot(1,10,i)
- ax.imshow(images[i-1],cmap='gray')
- ax.axis('off') # 关闭坐标轴
- ax.set_title(target_names[y[i-1]])
-
- plt.show()

先进行训练:
- from sklearn.model_selection import RandomizedSearchCV, train_test_split
- from sklearn.svm import SVC
- from sklearn.pipeline import Pipeline
- from sklearn.preprocessing import StandardScaler
-
- X_train, X_test, y_train, y_test = train_test_split(
- X, y, test_size=0.25, random_state=42
- )
- svm_clf = Pipeline([("scaler",StandardScaler()),
- ("svm_clf",SVC(kernel="linear", gamma=5, C=0.001))])
- svm_clf.fit(X_train, y_train)
验证预测的精度:
- y_pred = svm_clf.predict(X_test)
- correct = 0
- for i in range(len(y_test)):
- if y_pred[i] == y_test[i]:
- correct += 1
- print("accuracy: %f" % (correct/len(y_test)))
- # 输出:accuracy: 0.835404
总体精度84%,下面打印出分类预测报告:
- from sklearn.metrics import ConfusionMatrixDisplay, classification_report
- print(classification_report(y_test, y_pred, target_names=target_names))
- precision recall f1-score support
-
- Ariel Sharon 0.57 0.62 0.59 13
- Colin Powell 0.77 0.88 0.82 60
- Donald Rumsfeld 0.68 0.63 0.65 27
- George W Bush 0.89 0.92 0.90 146
- Gerhard Schroeder 0.88 0.84 0.86 25
- Hugo Chavez 0.92 0.73 0.81 15
- Tony Blair 0.93 0.69 0.79 36
-
- accuracy 0.84 322
- macro avg 0.80 0.76 0.78 322
- weighted avg 0.84 0.84 0.83 322
我们下面展示前十张图片,以及图片的真实人物名字和预测的人物名字:
- fig = plt.figure(figsize=(20,10))
- for i in range(1,11):
- ax = fig.add_subplot(2,5,i)
- ax.imshow(X_test[i-1].reshape(h,w),cmap='gray')
- ax.axis('off') # 关闭坐标轴
- ax.set_title("pred:{}\ntrue:{}".format(target_names[y_pred[i-1]],target_names[y_test[i-1]]))
-
- plt.show()

可以看到,基本还是比较准确的。

