
- 1华为云云耀云服务器L实例评测|Python Selenium加Chrome Driver构建UI自动化测试实践_华为浏览器driver
- 2使用Flutter的image_picker插件实现设备的相册的访问和拍照
- 3[点云学习] 一、点云相关知识了解
- 4HarmonyOS云开发基础认证【最新题库 满分答案】
- 5aigc修复美颜学习笔记
- 6Java 算法篇-深入了解单链表的反转(实现:用 5 种方式来具体实现)
- 7华为 ensp SSL VPN 史诗级配置
- 8如何解决大模型的「幻觉」问题
- 9【动态规划】【广度优先搜索】LeetCode:2617 网格图中最少访问的格子数
- 10视觉机械臂自主抓取全流程_机械臂视觉抓取
[自用] 菜菜的sklearn 随机森林分类器
赞
踩
目录
随机森林
1 概述
1.1 集成算法概述
集成算法,通过在数据上构建多个模型,集成所有模型的建模结果
随即森林、梯度提升树(GBDT)、Xgboost等集成算法
集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总后得到一个综合的结果,以此获得比单个模型更好的回归或分类表现
多个模型集成成为的模型叫集成评估器(ensemble estimator)
组成集成评估器的每个模型都叫做基评估器(base estimator)
通常有三类集成算法:
装袋法(Bagging)
构建多个相互独立的评估器,对预测进行平均或多数表决来决定结果,代表:随机森林
提升法(Boosting)
基评估器是相关的,按顺序一一构建的,结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器,代表:Adaboost,梯度提升树
Stacking
1.2 sklearn中的集成算法
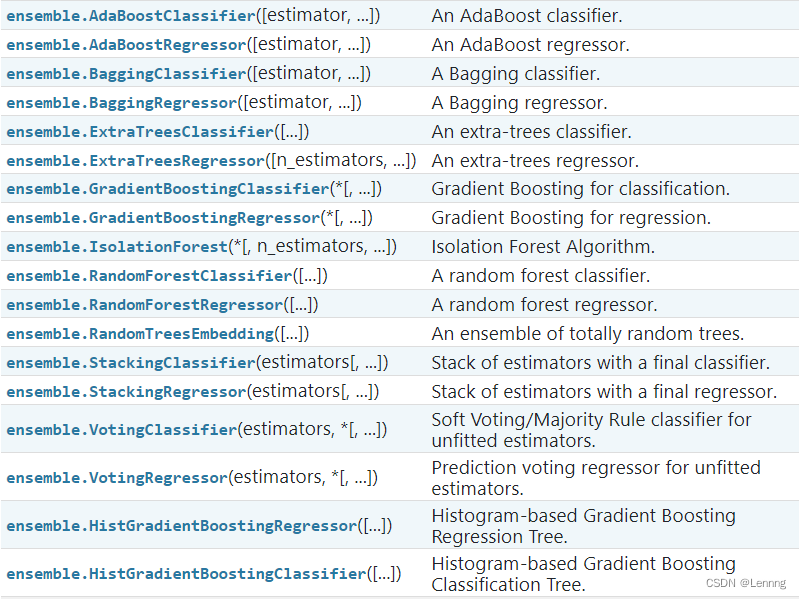
sklearn中的集成算法模块ensemble
2 RandomForestClassifier
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
随机森林是代表性的Bagging集成算法,所有基评估器都是决策树,分类树组成的森林叫做随机森林分类器,回归树所集成的森林叫做随机森林回归器
2.1 重要参数
2.1.1 控制基评估器的参数
criterion:{“gini”, “entropy”, “log_loss”}, default=”gini”
max_depth:int, default=None
min_samples_leaf:int or float, default=1
min_samples_split:int or float, default=2
max_features:{“sqrt”, “log2”, None}, int or float, default=”sqrt”
min_impurity_decrease:float, default=0.0
2.1.2 n_estimators
森林中数目的数量,即基评估器的数量,这个参数对随机森林模型的精确性影响是单调的;
值越大,模型的效果往往越好;达到一定程度之后,精确性不再提升并波动
建立一片森林
1. 导入需要的包
- %matplotlib inline
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.datasets import load_wine
2. 导入数据集
- wine = load_wine()
-
- wine.data
- wine.target
3. 进行建模
- from sklearn.model_selection import train_test_split
-
- Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data
- ,wine.target
- ,test_size=0.3
- )
- clf = DecisionTreeClassifier(random_state=0)
- rfc = RandomForestClassifier(random_state=0)
-
- clf = clf.fit(Xtrain,Ytrain)
- rfc = rfc.fit(Xtrain,Ytrain)
-
- score_c = clf.score(Xtest,Ytest)
- score_r = rfc.score(Xtest,Ytest)
-
- print(f"single tree:{score_c}, random forest:{score_r}")

single tree:0.9074074074074074, random forest:0.9814814814814815
4. 交叉验证
- from sklearn.model_selection import cross_val_score
- import matplotlib.pyplot as plt
-
- rfc = RandomForestClassifier(n_estimators=25)
- rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
-
- clf = DecisionTreeClassifier()
- clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
-
- plt.plot(range(1,11),rfc_s,label="randomforest")
- plt.plot(range(1,11),clf_s,label="decisiontree")
- plt.legend()
- plt.show()
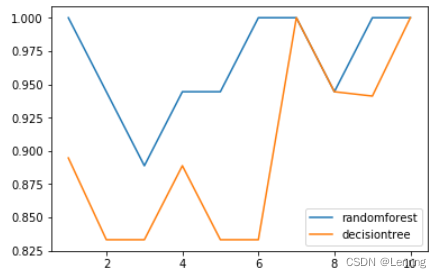
5. 画出随机森林和决策树在十组交叉验证下的效果对比
- rfc_l = []
- clf_l = []
-
- for i in range(10):
- rfc = RandomForestClassifier(n_estimators=25)
- rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
- rfc_l.append(rfc_s)
- clf = DecisionTreeClassifier()
- clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
- clf_l.append(clf_s)
-
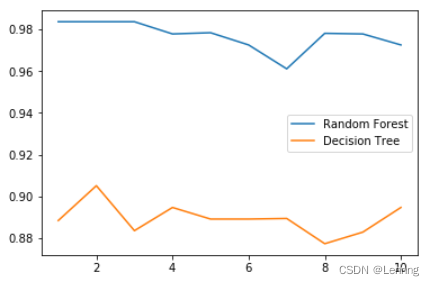
- plt.plot(range(1,11),rfc_l,label="Random Forest")
- plt.plot(range(1,11),clf_l,label="Decision Tree")
- plt.legend()
- plt.show()
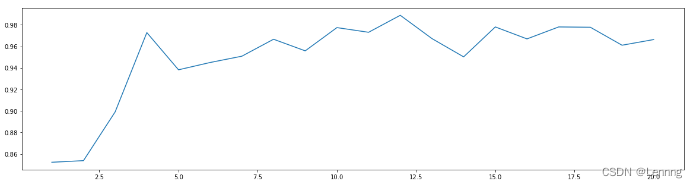
6. n_estimators的学习曲线
- superpa = []
- for i in range(200):
- rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
- rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
- superpa.append(rfc_s)
- print(max(superpa),superpa.index(max(superpa)))
- plt.figure(figsize=[20,5])
- plt.plot(range(1,201),superpa)
- plt.show()
(电脑跑不动遗憾改成20
2.1.3 random_state
随机森林的本质是一种装袋集成算法bagging,它是对基评估器的预测结果进行平均或多数表决原则来决定集成评估器的结果;
建立25棵树,当且仅当有13棵以上的树判断错误时,随机森林才会判断错误;
这是集成算法的随机森林比单棵树好的原因;
分类树中,一个random_state只控制生成一棵树;
随机森林中的random_state控制的是生成森林的模式,而非让一片森林只有一棵树
- rfc = RandomForestClassifier(n_estimators=25,random_state=2)
- rfc = rfc.fit(Xtrain,Ytrain)
-
- # 随机森林的重要属性之一:estimators_,查看森林中树的状况
- rfc.estimators_[0].random_state
- for i in range(len(rfc.estimators_)):
- print(rfc.estimators_[i].random_state)

用袋装法集成时,基分类器应当是相互独立的,不相同的
2.1.4 bootstrap & oob_score
袋装法通过有放回的随机抽样来形成不同的训练数据,bootstrap是用来控制抽样技术的参数
bootstrap参数默认True,代表采用有放回的随机抽样技术;
有放回抽样中有些样本可能会多次抽到,有些却可能被忽略;
因为使用随机森林,我们可以不划分测试集和训练集,只需要用袋外数据测试模型即可
如果希望用袋外数据测试,需要将oob_score调整为True;
并且可以用oob_score_来查看在袋外数据上测试的结果
- # 无需划分训练集和测试集
- rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
- rfc = rfc.fit(wine.data,wine.target)
-
- # 重要参数oob_score_
- rfc.oob_score_
0.9550561797752809
2.2 重要属性和接口
参数:n_estimators; random_state; boostrap; oob_score
属性:.estimators_; .oob_score_; .feature_importances
接口:apply; fit; predict; score; predict_proba
predict_proba返回每个测试样本对应的被分到每一类标签的概率;
标签有几个分类就返回几个概率;
sklearn中地随机森林平均每个样本对应的predict_proba返回的概率,得到平均概率,从而决定测试样本的分类
- # 试试属性和接口
-
- rfc = RandomForestClassifier(n_estimators=25)
- rfc = rfc.fit(Xtrain,Ytrain)
- rfc.score(Xtest,Ytest)
-
- rfc.feature_importances_
- rfc.apply(Xtest)
- rfc.predict(Xtest) # 返回测试集中的每个样本在每棵树中的叶节点的索引
- rfc.predict_proba(Xtest)
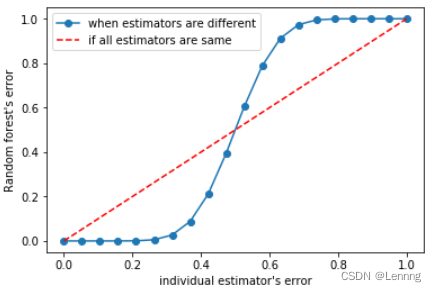
Bonus:Bagging的另一个必要条件
基分类器的判断准确率至少要超过50%;
画出基分类器的误差率ε和随机森林的误差率之间的图像
- import numpy as np
- from scipy.special import comb
-
- x = np.linspace(0,1,20)
-
- y = []
- for epsilon in np.linspace(0,1,20):
- E = np.array([comb(25,i)*(epsilon**i)*((1-epsilon)**(25-i))
- for i in range(13,26)]).sum()
- y.append(E)
-
- plt.plot(x,y,"o-",label="when estimators are different")
- plt.plot(x,x,"--",color="red",label="if all estimators are same")
- plt.xlabel("individual estimator's error")
- plt.ylabel("Random forest's error")
- plt.legend()
- plt.show()
大功告成啦!ᕙ(• ॒ ູ•)ᕘ

