
- 1大数据与云计算——部署Hadoop集群并运行MapReduce集群案例(超级详细!)_部署hadoop集群(容器)及基于mapreduce的倒排索引构建
- 2【MySQL】mysql中不推荐使用uuid或者雪花id作为主键的原因以及差异化对比
- 3【云原生】深入掌握k8s中Pod和生命周期_k8spod 生命周期配置
- 4【Shell 命令集合 网络通讯 】Linux 串口通信 minicom命令 使用指南
- 5分布式定时任务调度框架_分布式任务调度框架
- 6人工神经网络的发展历程,神经网络发展历程简述
- 7Linux完全卸载Anaconda3和MiniConda3
- 85分钟搭建开源运维监控工具Uptime Kuma并实现无公网IP远程访问
- 9粒子群算法
- 10阿里云Linux服务器登录名root和ecs-user怎么选择?_centos的ecs 自定义密码选root好?
SpringBoot中数据库连接池的使用_max-pool-prepared-statement-per-connection-size
赞
踩
目录
一、前言
开发web项目,我们肯定会和数据库打交道,因此就会涉及到数据库链接的问题。在以前我们开发传统的SSM结构的项目时进行数据库链接都是通过JDBC进行数据链接,我们每和数据库打一次交道都需要先获取一次链接,操作完后再关闭链接,这样子效率很低,因此就出现了连接池,用于高效创建并合理分配数据库链接,数据库连接池跟线程池其实也一样的道理。
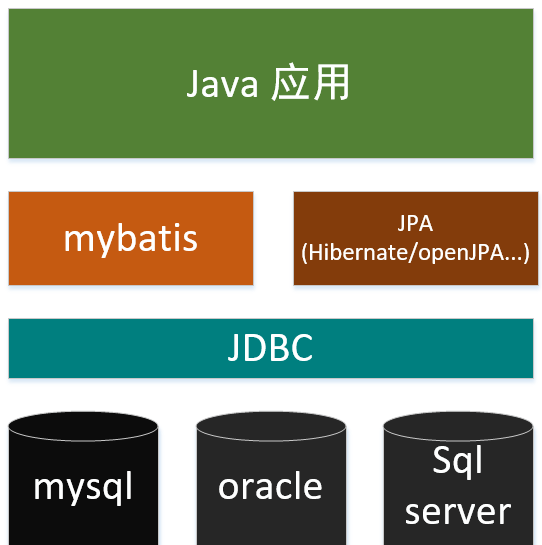
说到连接池就不得不说到持久层的框架JDBC、MyBatis、Hibernate、Spring Data等,目前市面上最流行的应该属于MyBatis(底层JDBC),其中还有个MyBatis-plus并不属于新的框架,只能算是在MyBatis上包装了一层更便于开发人员使用而已。从上图可以看出来,其实现在市面上演变而来的持久层框架大多都是基于JDBC而来的,下面我们就讲一讲连接池相关的内容吧。
二、连接池介绍
1. 使用连接池的好处
①资源重用
避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
②更快的系统响应速度
在初始化过程中,就已经创建好若干数据库连接。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
③新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术,几年钱也许还是个新鲜话题,对于目前的业务系统而言,如果设计中还没有考虑到连接池的应用,那么…….快在设计文档中加上这部分的内容吧。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。
④ 统一的连接管理,避免数据库连接泄漏
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄漏。
2. 常见连接池
现在市面上的连接池有很多种,此处我也只列举几种使用较多的:
①C3P0
开源的JDBC连接池,实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。目前使用它的开源项目有Hibernate、Spring等。单线程,性能较差,适用于小型系统,代码600KB左右。
②DBCP
全称(Database Connection Pool),由Apache开发的一个Java数据库连接池项目, Jakarta commons-pool对象池机制,Tomcat使用的连接池组件就是DBCP。单独使用dbcp需要3个包:common-dbcp.jar,common-pool.jar,common-collections.jar,预先将数据库连接放在内存中,应用程序需要建立数据库连接时直接到连接池中申请一个就行,用完再放回。单线程,并发量低,性能不好,适用于小型系统。
③Tomcat Jdbc Pool
Tomcat在7.0以前都是使用common-dbcp做为连接池组件,但是dbcp是单线程,为保证线程安全会锁整个连接池,性能较差,dbcp有超过60个类,也相对复杂。Tomcat从7.0开始引入了新增连接池模块叫做Tomcat jdbc pool,基于Tomcat JULI,使用Tomcat日志框架,完全兼容dbcp,通过异步方式获取连接,支持高并发应用环境,超级简单核心文件只有8个,支持JMX,支持XA Connection。
④BoneCP
官方说法BoneCP是一个高效、免费、开源的Java数据库连接池实现库。设计初衷就是为了提高数据库连接池性能,根据某些测试数据显示,BoneCP的速度是最快的,要比当时第二快速的连接池快25倍左右,完美集成到一些持久化产品如Hibernate和DataNucleus中。BoneCP特色:高度可扩展,快速;连接状态切换的回调机制;允许直接访问连接;自动化重置能力;JMX支持;懒加载能力;支持XML和属性文件配置方式;较好的Java代码组织,100%单元测试分支代码覆盖率;代码40KB左右。
⑤Druid(德鲁伊)–推荐使用
Druid是Java语言中最好的数据库连接池,Druid能够提供强大的监控和扩展功能,是一个可用于大数据实时查询和分析的高容错、高性能的开源分布式系统,尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。主要特色:为分析监控设计;快速的交互式查询;高可用;可扩展;Druid是一个开源项目,源码托管在github上。
⑥Hikari
HiKariCP是数据库连接池的一个后起之秀,号称性能最好,可以完美地PK掉其他连接池,是一个高性能的JDBC连接池,基于BoneCP做了不少的改进和优化。并且 在springboot2.0之后,采用的默认数据库连接池就是Hikari。
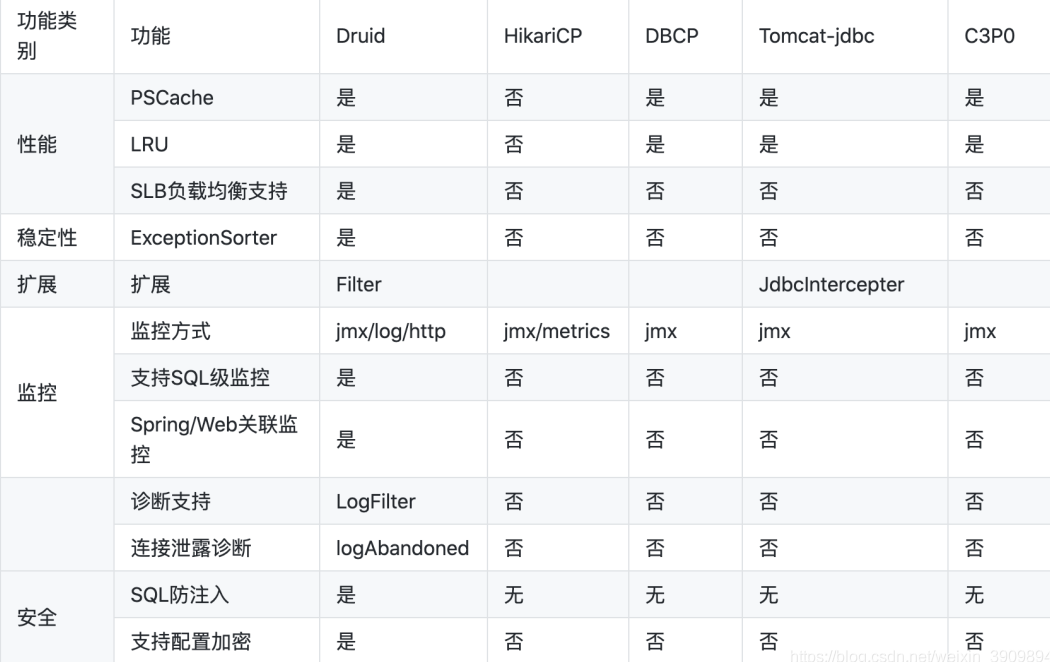
3. 各种连接池的优缺点
4. 项目中该如何选择连接池
小型项目
若只是小型SpringBoot项目,那么你无论使用Druid和Hikari哪种都可以,都有各自的优缺点。使用SpringBoot自带的Hikari数据库连接池操作简单,不需要引入额外的jar包,拿来即用,也不需要额外的多做配置等,使用Druid连接池还支持sql级监控、扩展、SQL防注入等。–推荐使用Druid连接池
中型项目
推荐使用Druid数据库,也就是我们平时说的德鲁伊连接池,使用理由如下:
Druid功能更全面,除具备连接池基本功能外,还支持sql级监控、扩展、SQL防注入等。最新版甚至有集群监控
单从性能角度考虑,从数据上确实HikariCP要强,但Druid有更多、更久的生产实践,它可靠。
大型项目
推荐使用默认的HikariCP连接池,因为大型项目中有专门用于监控的系统(skywalking、prometheus),连接池就只需要它做好连接池的本职工作即可,因此性能更好的HikariCP才是首选。
三、SpringBoot中的连接池及使用
1.SpringBoot默认连接池(Hikari)使用
配置文件中的数据源配置中不设置数据源类型即使用默认的Hikari,如果需要设置连接池配置参数直接在配置文件中设置即可:
- #数据库配置
- spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
- spring.datasource.url=jdbc:mysql://localhost:3306/gsnm_base_0000?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
- spring.datasource.username=root
- spring.datasource.password=123456
-
- # 数据库连接池配置
- #最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size
- spring.datasource.hikari.minimum-idle=10
- #最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值
- spring.datasource.hikari.maximum-pool-size=20
- #空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒
- spring.datasource.hikari.idle-timeout=500000
- #连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短
- spring.datasource.hikari.max-lifetime=540000
- #连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒
- spring.datasource.hikari.connection-timeout=60000

Hikari连接池的使用是很简单的,因为是默认的连接池,因此我们也不需要做过多的配置,拿来既可以使用。
2.SpringBoot整合druid(德鲁伊)连接池
①导入druid-spring-boot-starter包(推荐1.2.21版本)
注意:此包1.1.10后的版本数据监控中心做了调整需要自己新增配置类
- <!--引入druid数据源 1.1.10 此版本的数据监控中心可以直接使用-->
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>druid-spring-boot-starter</artifactId>
- <version>1.1.10</version>
- </dependency>
- <!--druid数据源 1.1.21 此版本的数据监控中心增加了登录界面需要增加配置类-->
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>druid-spring-boot-starter</artifactId>
- <version>1.1.21</version>
- </dependency>
②修改配置文件
③新增数据源配置类DruidConfig
若没有指定连接池参数,则无需此配置类
- import com.alibaba.druid.pool.DruidDataSource;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
- import org.springframework.beans.factory.annotation.Value;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
- import org.springframework.context.annotation.Primary;
-
- import java.sql.SQLException;
-
- /**
- * Druid连接池调优配置信息:只有配置数据库连接池调优信息才需要该类
- */
- @Configuration
- public class DruidConfig {
- private Logger logger = LoggerFactory.getLogger(DruidConfig.class);
-
- @Value("${spring.datasource.url}")
- private String dbUrl;
-
- @Value("${spring.datasource.username}")
- private String username;
-
- @Value("${spring.datasource.password}")
- private String password;
-
- @Value("${spring.datasource.driver-class-name}")
- private String driverClassName;
-
- @Value("${spring.datasource.initial-size}")
- private int initialSize;
-
- @Value("${spring.datasource.min-idle}")
- private int minIdle;
-
- @Value("${spring.datasource.max-active}")
- private int maxActive;
-
- @Value("${spring.datasource.max-wait}")
- private int maxWait;
-
- @Value("${spring.datasource.time-between-eviction-runs-millis}")
- private int timeBetweenEvictionRunsMillis;
-
- @Value("${spring.datasource.min-evictable-idle-time-millis}")
- private int minEvictableIdleTimeMillis;
-
- @Value("${spring.datasource.test-while-idle}")
- private boolean testWhileIdle;
-
- @Value("${spring.datasource.test-on-borrow}")
- private boolean testOnBorrow;
-
- @Value("${spring.datasource.test-on-return}")
- private boolean testOnReturn;
-
- @Value("${spring.datasource.pool-prepared-statements}")
- private boolean poolPreparedStatements;
-
- @Value("${spring.datasource.max-pool-prepared-statement-per-connection-size}")
- private int maxPoolPreparedStatementPerConnectionSize;
-
- @Value("${spring.datasource.filters}")
- private String filters;
-
- @Primary //在同样的DataSource中,首先使用被标注的DataSource
- @Bean
- public DruidDataSource dataSourceDefault(){
- DruidDataSource datasource = new DruidDataSource();
-
- datasource.setUrl(this.dbUrl);
- datasource.setUsername(username);
- datasource.setPassword(password);
- datasource.setDriverClassName(driverClassName);
-
- //configuration
- datasource.setInitialSize(initialSize);
- datasource.setMinIdle(minIdle);
- datasource.setMaxActive(maxActive);
- datasource.setMaxWait(maxWait);
- datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
- datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
- datasource.setTestWhileIdle(testWhileIdle);
- datasource.setTestOnBorrow(testOnBorrow);
- datasource.setTestOnReturn(testOnReturn);
- datasource.setPoolPreparedStatements(poolPreparedStatements);
- datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
- try {
- datasource.setFilters(filters);
- } catch (SQLException e) {
- logger.error("druid configuration initialization filter", e);
- }
- return datasource;
- }
- }
④新增数据监控中心配置类DruidMonitorConfig
若jar包版本高于1.1.10时才需要配置该类
- import com.alibaba.druid.support.http.StatViewServlet;
- import com.alibaba.druid.support.http.WebStatFilter;
- import org.springframework.boot.web.servlet.FilterRegistrationBean;
- import org.springframework.boot.web.servlet.ServletRegistrationBean;
- import org.springframework.context.annotation.Bean;
- import org.springframework.context.annotation.Configuration;
-
- import java.util.HashMap;
- import java.util.Map;
-
- /**
- * Druid连接池监控配置信息
- * 提示:druid-spring-boot-starter jar包的版本高于1.1.10时才需要配置该类
- * 1.若低于1.1.10版本时直接访问:IP:端口/druid/index.html即可
- * 2.若高于1.0.10版本时访问:IP:端口/druid/login.html即可 账号密码根据自己设置的来
- *
- * @author wyj
- * @date 2022/8/16 15:54
- */
- @Configuration
- public class DruidMonitorConfig {
-
- //因为Springboot内置了servlet容器,所以没有web.xml,替代方法就是将ServletRegistrationBean注册进去
- //加入后台监控
- @Bean //这里其实就相当于servlet的web.xml
- public ServletRegistrationBean<StatViewServlet> statViewServlet() {
- ServletRegistrationBean<StatViewServlet> bean =
- new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
-
- //后台需要有人登录,进行配置
- //bean.addUrlMappings(); 这个可以添加映射,我们在构造里已经写了
- //设置一些初始化参数
- Map<String, String> initParas = new HashMap<>();
- initParas.put("loginUsername", "admin");//它这个账户密码是固定的
- initParas.put("loginPassword", "123456");
- //允许谁能防伪
- initParas.put("allow", "");//这个值为空或没有就允许所有人访问,ip白名单
- //initParas.put("allow","localhost");//只允许本机访问,多个ip用逗号,隔开
- //initParas.put("deny","");//ip黑名单,拒绝谁访问 deny和allow同时存在优先deny
- initParas.put("resetEnable", "false");//禁用HTML页面的Reset按钮
- bean.setInitParameters(initParas);
- return bean;
- }
-
- //再配置一个过滤器,Servlet按上面的方式注册Filter也只能这样
- @Bean
- public FilterRegistrationBean<WebStatFilter> webStatFilter() {
- FilterRegistrationBean<WebStatFilter> bean = new FilterRegistrationBean<>();
- //可以设置也可以获取,设置一个阿里巴巴的过滤器
- bean.setFilter(new WebStatFilter());
- bean.addUrlPatterns("/*");
- //可以过滤和排除哪些东西
- Map<String, String> initParams = new HashMap<>();
- //把不需要监控的过滤掉,这些不进行统计
- initParams.put("exclusions", "*.js,*.css,/druid/*");
- bean.setInitParameters(initParams);
- return bean;
- }
- }
数据监控中心访问地址:
1.若jar包版本低于1.1.10版本时访问:127.0.0.1:端口/druid/index.html
2.若jar包版本高于1.0.10版本时访问:127.0.0.1:端口/druid/login.html(账号密码根据自己设置的来)



