
- 12023年4月Web3行业月度发展报告区块链篇 | 陀螺科技会员专享
- 2ubuntu20.04安装完没有连接wifi的选项,ubuntu网卡驱动_ubuntu20.04没有连接wifi选项
- 3解决subprocess.CalledProcessError: Command ‘[‘dot‘, ‘-Tpdf‘, ‘-O‘, ‘Digraph.gv‘]‘ returned non-zero
- 4使用Golang创建windows GUI图形界面并添加图标_golang 图形界面
- 5Linux TCP/IP 网络工具对比:net-tools 和 iproute2_linux tcptool
- 6【就业必备知识】大学毕业如何处理档案和户口,小心变成死档和黑户_毕业户口没转出会变成黑户吗
- 7mqtt集群搭建并使用nginx做负载均衡_亲测得结论_mqtt负载均衡
- 8Unity 从0开始编写一个技能编辑器_01_分析需求_技能编辑器 unity
- 9【Python爬虫】基于selenium库爬取京东商品数据——以“七夕”为例_京东图书 selenium
- 10【C++基础入门】cLion的安装、搭建C++环境_clion创建c++项目
paddle学习赛——钢铁目标检测(yolov5、ppyoloe+,Faster-RCNN)_paddle faster rcnn
赞
踩
文章目录
参考:
- 《飞桨新人赛:钢铁缺陷检测挑战赛-第1名方案》FasterRCNN+Swin
- 《飞桨新人赛:钢铁缺陷检测挑战赛-第2名方案》FasterRCNN
- 《飞桨新人赛:钢铁缺陷检测挑战赛-第3名方案》
一、赛事简介
- 比赛地址:https://aistudio.baidu.com/aistudio/competition/detail/114/0/introduction
- 赛题介绍:本次比赛为图像目标识别比赛,要求参赛选手识别出钢铁表面出现缺陷的位置,并给出锚点框的坐标,同时对不同的缺陷进行分类。
- 数据简介:本数据集来自NEU表面缺陷检测数据集,收集了6种典型的热轧带钢表面缺陷,即氧化铁皮压入(RS)、斑块(Pa)、开裂(Cr)、点蚀(PS)、夹杂(In)和划痕(Sc)。下图为六种典型表面缺陷的示例,每幅图像的分辨率为200 * 200像素。
- 训练集图片1400张,测试集图片400张

提交内容及格式:
- 结果文件命名:submission.csv(否则无法成功提交)
- 结果文件格式:.csv(否则无法成功提交)
- 结果文件内容:submission.csv结果文件需包含多行记录,每行包括4个字段,内容示例如下:
image_id bbox category_id confidence
1400 [0, 0, 0, 0] 0 1
- 1
- 2
各字段含义如下:
- image_id(int): 图片id
- bbox(list[float]): 检测框坐标(XMin, YMin, XMax, YMax)
- category_id: 缺陷所属类别(int),类别对应字典为:{‘ crazing’:0,’inclusion’:1, ’pitted_surface’:2, ,’scratches’:3,’patches’:4,’rolled-in_scale’:5}
- confidence(float): 置信度
备注: 每一行记录1个检测框,并给出对应的category_id;同张图片中检测到的多个检测框,需分别记录在不同的行内。
二、ppyoloe+l模型,41.32分 (PaddleDetection-voc)
2.1 安装PaddleDetection
- 克隆PaddleDetection
- 安装PaddleDetection文件夹的requirements.txt(python依赖)
- 编译安装paddledet
- 安装后确认测试通过
%cd ~/work
#!git clone https://github.com/PaddlePaddle/PaddleDetection.git
#如果github下载代码较慢,可尝试使用gitee
#git clone https://gitee.com/paddlepaddle/PaddleDetection
# 安装其他依赖
%cd PaddleDetection
!pip install -r requirements.txt
# 编译安装paddledet
!python setup.py install
#安装后确认测试通过:
!python ppdet/modeling/tests/test_architectures.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
!python ppdet/modeling/tests/test_architectures.py
- 1
W1001 15:08:57.768669 1185 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1001 15:08:57.773610 1185 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
.......
----------------------------------------------------------------------
Ran 7 tests in 2.142s
OK
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 数据预处理
2.2.1 解压数据集
# 解压到work下的dataset文件夹
!mkdir dataset
!unzip ../data/test.zip -d dataset
!unzip ../data/train.zip -d dataset
# 重命名为annotations和images
!mv dataset/train/IMAGES dataset/train/images
!mv dataset/train/ANNOTATIONS dataset/train/annotations
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2.2 自定义数据集(感觉很麻烦,暂时放弃)
PaddleDetection的数据处理模块的所有代码逻辑在ppdet/data/中,数据处理模块用于加载数据并将其转换成适用于物体检测模型的训练、评估、推理所需要的格式。- 数据集定义在
source目录下,其中dataset.py中定义了数据集的基类DetDataSet, 所有的数据集均继承于基类,DetDataset基类里定义了如下等方法:
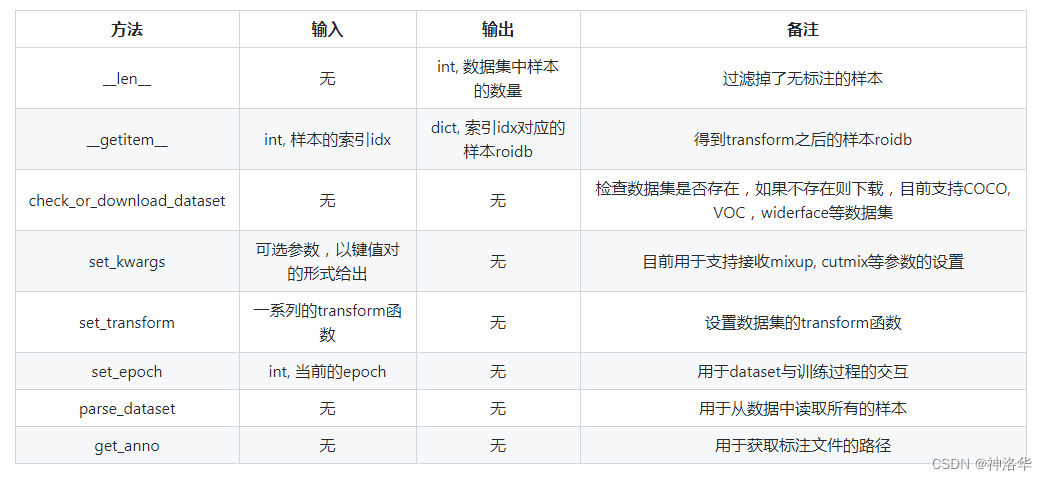
- 当一个数据集类继承自DetDataSet,那么它只需要实现parse_dataset函数即可
parse_dataset根据数据集设置:
- 数据集根路径
dataset_dir - 图片文件夹
image_dir - 标注文件路径
anno_path
取出所有的样本,并将其保存在一个列表roidbs中,每一个列表中的元素为一个样本xxx_rec(比如coco_rec或者voc_rec),用dict表示,dict中包含样本的image, gt_bbox, gt_class等字段。COCO和Pascal-VOC数据集中的xxx_rec的数据结构定义如下:
xxx_rec = {
'im_file': im_fname, # 一张图像的完整路径
'im_id': np.array([img_id]), # 一张图像的ID序号
'h': im_h, # 图像高度
'w': im_w, # 图像宽度
'is_crowd': is_crowd, # 是否是群落对象, 默认为0 (VOC中无此字段)
'gt_class': gt_class, # 标注框标签名称的ID序号
'gt_bbox': gt_bbox, # 标注框坐标(xmin, ymin, xmax, ymax)
'gt_poly': gt_poly, # 分割掩码,此字段只在coco_rec中出现,默认为None
'difficult': difficult # 是否是困难样本,此字段只在voc_rec中出现,默认为0
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
xxx_rec中的内容也可以通过DetDataSet的data_fields参数来控制,即可以过滤掉一些不需要的字段,但大多数情况下不需要修改,按照configs/dataset中的默认配置即可。
-
此外,在parse_dataset函数中,保存了类别名到id的映射的一个字典cname2cid。在coco数据集中,会利用COCO API从标注文件中加载数据集的类别名,并设置此字典。在voc数据集中,如果设置use_default_label=False,将从label_list.txt中读取类别列表,反之将使用voc默认的类别列表。
2.2.3 准备VOC数据集(直接用这个)
参考:《如何准备训练数据》
-
尝试coco数据集
- COCO数据标注是将所有训练图像的标注都存放到一个json文件中。数据以字典嵌套的形式存放
- 用户数据集转成COCO数据后目录结构如下:
dataset/xxx/ ├── annotations │ ├── train.json # coco数据的标注文件 │ ├── valid.json # coco数据的标注文件 ├── images │ ├── xxx1.jpg │ ├── xxx2.jpg │ ├── xxx3.jpg │ | ... ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- json格式标注文件,得自己生成,目前我知道的就是用
paddledetection./tools/中提供的x2coco.py,将VOC数据集、labelme标注的数据集或cityscape数据集转换为COCO数据(生成json标准为文件)。这样太麻烦,还不如直接用VOC格式训练。
-
尝试自定义数据集(参考《数据处理模块》,重写
parse_dataset感觉也很麻烦) -
准备voc数据集(最简单,麻烦一点的就是生成txt文件)
-
模仿VOC数据集目录结构,新建
VOCdevkit文件夹并进入其中,然后继续新建VOC2007文件夹并进入其中,之后新建Annotations、JPEGImages和ImageSets文件夹,最后进入ImageSets文件夹中新建Main文件夹,至此完成VOC数据集目录结构的建立。 -
将该数据集中的
train/annotations/xmls与val/annotations/xmls(如果有val验证集的话)下的所有xml标注文件拷贝到VOCdevkit/VOC2007/Annotations中, -
将该数据集中的
train/images/与val/images/下的所有图片拷贝到VOCdevkit/VOC2007/JPEGImages中 -
最后在数据集根目录下输出最终的trainval.txt和test.txt文件(可用pandas完成,一会说):
-
-
生成VOC格式目录。
如果觉得后面移动文件很麻烦,可以先生成VOC目录,再将数据集解压到VOC2007中,将其图片和标注文件夹分别重命名为Annotations和JPEGImages。
%cd work
!mkdir VOCdevkit
%cd VOCdevkit
!mkdir VOC2007
%cd VOC2007
!mkdir Annotations JPEGImages ImageSets
%cd ImageSets
!mkdir Main
%cd ../../
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 生成
trainval.txt和val.txt
由于该数据集中缺少已标注图片名列表文件trainval.txt和val.txt,所以需要进行生成,用pandas处理更直观
# 遍历图片和标注文件夹,将所有文件后缀正确的文件添加到列表中
import os
import pandas as pd
ls_xml,ls_image=[],[]
for xml in os.listdir('dataset/train/annotations'):
if xml.split('.')[1]=='xml':
ls_xml.append(xml)
for image in os.listdir('dataset/train/images'):
if image.split('.')[1]=='jpg':
ls_image.append(image)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
读取xml文件列表和image文件名列表之后,要先进行排序。
- 直接df.sort_values([‘image’,‘xml’],inplace=True)是先对image排序,再对xml排序,是整个表排序而不是单列分别排序,这样的结果是不对的
- 直接分别排序再合并,结果也不对。因为添加xml列的时候,默认是按key=index来合并的,而两个列表的文件都是乱序的,这样排序后index也不相同,所以需要分别排序后重设索引,且丢弃原先索引,最后再合并。
df=pd.DataFrame(ls_image,columns=['image'])
df.sort_values('image',inplace=True)
df=df.reset_index(drop=True)
s=pd.Series(ls_xml).sort_values().reset_index(drop=True)
df['xml']=s
df.head(3)
- 1
- 2
- 3
- 4
- 5
- 6
image xml
0 0.jpg 0.xml
1 1.jpg 1.xml
2 10.jpg 10.xml
- 1
- 2
- 3
- 4
训练时,文件都是相对路径,所以要加前缀VOC2007/JPEGImages/和VOC2007/Annotations/
%cd VOCdevkit
trainval=df.sample(frac=1)
trainval.image=trainval.image.apply(lambda x : 'VOC2007/JPEGImages/'+str(x))
trainval.xml=trainval.xml.apply(lambda x : 'VOC2007/Annotations/'+str(x))
trainval.to_csv('trainval.txt',sep=' ',index=0,header=0)
# 划分出训练集和验证集,保存为txt格式,中间用空格隔开
train_df=trainval[:1200]
val_df=trainval[1200:]
train_df.to_csv('train.txt',sep=' ',index=0,header=0)
val_df.to_csv('val.txt',sep=' ',index=0,header=0)
!cp -r train/annotations/* ../VOCdevkit/VOC2007/Annotations
!cp -r train/images/* ../VOCdevkit/VOC2007/JPEGImages
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
查看一张图片信息:
from PIL import Image
image = Image.open('dataset/train/images/0.jpg')
print('width: ', image.width)
print('height: ', image.height)
print('size: ', image.size)
print('mode: ', image.mode)
print('format: ', image.format)
print('category: ', image.category)
print('readonly: ', image.readonly)
print('info: ', image.info)
image.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.3 修改配置文件,准备训练
- 模型效果请参考ppyolo文档
- 配置参数参考yolo配置参数说明、《如何更好的理解reader和自定义修改reader文件》
- PaddleYOLO库集成了yolo系列模型,包括yolov5/6/7/X,后续可以试试。
- 修改配置文件
- 手动复制一个
configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml文件的副本,其它类似,防止改错了无法还原 configs/datasets/voc.yml不用复制,免得下次重新写,修改后如下:(TestDataset最好不要写dataset_dir字段,否则后面infer.py推断的时候,选择参数save_results=True会报错label_list label_list.txt not a file)metric: VOC map_type: 11point num_classes: 6 TrainDataset: !VOCDataSet dataset_dir: ../VOCdevkit anno_path: train.txt label_list: label_list.txt data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult'] EvalDataset: !VOCDataSet dataset_dir: ../VOCdevkit anno_path: val.txt label_list: label_list.txt data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult'] TestDataset: !ImageFolder anno_path: ../VOCdevkit/label_list.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 学习率改为0.00025,epoch=60,max_epochs=72,!LinearWarmup下的epoch改为4。
- reader部分训练验证集的batch_size从8改为16,推理时bs也改为16,大大加快推理速度(之前默认为1,特别慢)
- PP-YOLOE+支持混合精度训练,请添加
--amp. - 使用YOLOv3模型如何通过yml文件修改输入图片尺寸
Multi-Scale Training:多尺度训练 。yolov3中作者认为网络输入尺寸固定的话,模型鲁棒性受限,所以考虑多尺度训练。具体的,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸[320,352,416…608](Darknet-19最终将图片缩放32倍,所以一般选择32的倍数)。- 模型预测部署需要用到指定的尺寸时,首先在训练前需要修改
configs/_base_/yolov3_reader.yml中的TrainReader的BatchRandomResize中target_size包含指定的尺寸,训练完成后,在评估或者预测时,需要将EvalReader和TestReader中的Resize的target_size修改成对应的尺寸,如果是需要模型导出(export_model),则需要将TestReader中的image_shape修改为对应的图片输入尺寸 。 - 如果只改了训练集入网尺寸,验证测试集尺寸不变,会报错
- Paddle中支持的优化器Optimizer在PaddleDetection中均支持,需要手动修改下配置文件即可
- 手动复制一个
ppyoloe_plus_reader.yml修改如下:(图片都很小,把默认的入网尺寸改了)
worker_num: 4 eval_height: &eval_height 224 eval_width: &eval_width 224 eval_size: &eval_size [*eval_height, *eval_width] TrainReader: sample_transforms: - Decode: {} - RandomDistort: {} - RandomExpand: {fill_value: [123.675, 116.28, 103.53]} - RandomCrop: {} - RandomFlip: {} batch_transforms: - BatchRandomResize: {target_size: [96, 128, 160, 192, 224, 256, 288,320,352], random_size: True, random_interp: True, keep_ratio: False} - NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none} - Permute: {} - PadGT: {} batch_size: 16 shuffle: true drop_last: true use_shared_memory: true collate_batch: true EvalReader: sample_transforms: - Decode: {} - Resize: {target_size: *eval_size, keep_ratio: False, interp: 2} - NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none} - Permute: {} batch_size: 16 TestReader: inputs_def: image_shape: [3, *eval_height, *eval_width] sample_transforms: - Decode: {} - Resize: {target_size: *eval_size, keep_ratio: False, interp: 2} - NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none} - Permute: {} batch_size: 1 #最好是1,下文会说明
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
训练参数列表:(可通过–help查看)
| FLAG | 支持脚本 | 用途 | 默认值 | 备注 |
|---|---|---|---|---|
| -c | ALL | 指定配置文件 | None | 必选,例如-c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml |
| -o | ALL | 设置或更改配置文件里的参数内容 | None | 相较于-c设置的配置文件有更高优先级,例如:-o use_gpu=False |
| –eval | train | 是否边训练边测试 | False | 如需指定,直接--eval即可 |
| -r/–resume_checkpoint | train | 恢复训练加载的权重路径 | None | 例如:-r output/faster_rcnn_r50_1x_coco/10000 |
| –slim_config | ALL | 模型压缩策略配置文件 | None | 例如--slim_config configs/slim/prune/yolov3_prune_l1_norm.yml |
| –use_vdl | train/infer | 是否使用VisualDL记录数据,进而在VisualDL面板中显示 | False | VisualDL需Python>=3.5 |
| –vdl_log_dir | train/infer | 指定 VisualDL 记录数据的存储路径 | train:vdl_log_dir/scalar infer: vdl_log_dir/image | VisualDL需Python>=3.5 |
| –output_eval | eval | 评估阶段保存json路径 | None | 例如 --output_eval=eval_output, 默认为当前路径 |
| –json_eval | eval | 是否通过已存在的bbox.json或者mask.json进行评估 | False | 如需指定,直接--json_eval即可, json文件路径在--output_eval中设置 |
| –classwise | eval | 是否评估单类AP和绘制单类PR曲线 | False | 如需指定,直接--classwise即可 |
| –output_dir | infer/export_model | 预测后结果或导出模型保存路径 | ./output | 例如--output_dir=output |
| –draw_threshold | infer | 可视化时分数阈值 | 0.5 | 例如--draw_threshold=0.7 |
| –infer_dir | infer | 用于预测的图片文件夹路径 | None | --infer_img和--infer_dir必须至少设置一个 |
| –infer_img | infer | 用于预测的图片路径 | None | --infer_img和--infer_dir必须至少设置一个,infer_img具有更高优先级 |
| –save_results | infer | 是否在文件夹下将图片的预测结果保存到文件中 | False | 可选 |
2.4 ppyoloe+s,mAP=77.6%
# lr=0.0002,epoch=40,time=2572s
%cd ~/work/PaddleDetection/
!python -u tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco-Copy1.yml \
--use_vdl=true \
--vdl_log_dir=vdl_dir/scalar \
--eval \
--amp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[10/02 02:51:09] ppdet.engine INFO: Epoch: [45] [ 0/75] learning_rate: 0.000085 loss: 1.671754 loss_cls: 0.781011 loss_iou: 0.174941 loss_dfl: 0.880325 loss_l1: 0.378740 eta: 0:10:17 batch_cost: 0.5481 data_cost: 0.0049 ips: 29.1918 images/s [10/02 02:51:58] ppdet.engine INFO: Epoch: [46] [ 0/75] learning_rate: 0.000080 loss: 1.672976 loss_cls: 0.782366 loss_iou: 0.173936 loss_dfl: 0.885129 loss_l1: 0.378303 eta: 0:09:36 batch_cost: 0.5459 data_cost: 0.0049 ips: 29.3068 images/s [10/02 02:52:48] ppdet.engine INFO: Epoch: [47] [ 0/75] learning_rate: 0.000075 loss: 1.679924 loss_cls: 0.791866 loss_iou: 0.173251 loss_dfl: 0.892923 loss_l1: 0.371434 eta: 0:08:55 batch_cost: 0.5490 data_cost: 0.0049 ips: 29.1445 images/s [10/02 02:53:37] ppdet.engine INFO: Epoch: [48] [ 0/75] learning_rate: 0.000069 loss: 1.669277 loss_cls: 0.785255 loss_iou: 0.173793 loss_dfl: 0.879943 loss_l1: 0.384001 eta: 0:08:14 batch_cost: 0.5546 data_cost: 0.0072 ips: 28.8511 images/s [10/02 02:54:25] ppdet.engine INFO: Epoch: [49] [ 0/75] learning_rate: 0.000064 loss: 1.653534 loss_cls: 0.783021 loss_iou: 0.173808 loss_dfl: 0.865887 loss_l1: 0.377161 eta: 0:07:32 batch_cost: 0.5445 data_cost: 0.0080 ips: 29.3847 images/s [10/02 02:55:18] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/02 02:55:19] ppdet.engine INFO: Eval iter: 0 [10/02 02:55:24] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [10/02 02:55:24] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 77.23% [10/02 02:55:24] ppdet.engine INFO: Total sample number: 200, averge FPS: 36.900204541994455 [10/02 02:55:24] ppdet.engine INFO: Best test bbox ap is 0.772. [10/02 02:55:30] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/02 02:55:31] ppdet.engine INFO: Epoch: [50] [ 0/75] learning_rate: 0.000059 loss: 1.639129 loss_cls: 0.777811 loss_iou: 0.172295 loss_dfl: 0.865005 loss_l1: 0.371313 eta: 0:06:51 batch_cost: 0.5446 data_cost: 0.0056 ips: 29.3792 images/s [10/02 02:56:18] ppdet.engine INFO: Epoch: [51] [ 0/75] learning_rate: 0.000054 loss: 1.643418 loss_cls: 0.775152 loss_iou: 0.170642 loss_dfl: 0.866506 loss_l1: 0.374402 eta: 0:06:10 batch_cost: 0.5376 data_cost: 0.0058 ips: 29.7619 images/s [10/02 02:57:07] ppdet.engine INFO: Epoch: [52] [ 0/75] learning_rate: 0.000050 loss: 1.652525 loss_cls: 0.774686 loss_iou: 0.170963 loss_dfl: 0.863157 loss_l1: 0.375742 eta: 0:05:28 batch_cost: 0.5396 data_cost: 0.0068 ips: 29.6510 images/s [10/02 02:57:56] ppdet.engine INFO: Epoch: [53] [ 0/75] learning_rate: 0.000045 loss: 1.627508 loss_cls: 0.768282 loss_iou: 0.168563 loss_dfl: 0.865570 loss_l1: 0.368651 eta: 0:04:47 batch_cost: 0.5505 data_cost: 0.0093 ips: 29.0646 images/s [10/02 02:58:45] ppdet.engine INFO: Epoch: [54] [ 0/75] learning_rate: 0.000041 loss: 1.630234 loss_cls: 0.768148 loss_iou: 0.168092 loss_dfl: 0.868954 loss_l1: 0.361416 eta: 0:04:06 batch_cost: 0.5521 data_cost: 0.0096 ips: 28.9806 images/s [10/02 02:59:39] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/02 02:59:40] ppdet.engine INFO: Eval iter: 0 [10/02 02:59:45] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [10/02 02:59:45] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 76.88% [10/02 02:59:45] ppdet.engine INFO: Total sample number: 200, averge FPS: 34.83328737953738 [10/02 02:59:45] ppdet.engine INFO: Best test bbox ap is 0.772. [10/02 02:59:47] ppdet.engine INFO: Epoch: [55] [ 0/75] learning_rate: 0.000037 loss: 1.630969 loss_cls: 0.772440 loss_iou: 0.170143 loss_dfl: 0.868614 loss_l1: 0.365805 eta: 0:03:25 batch_cost: 0.5482 data_cost: 0.0057 ips: 29.1862 images/s [10/02 03:00:35] ppdet.engine INFO: Epoch: [56] [ 0/75] learning_rate: 0.000033 loss: 1.637988 loss_cls: 0.769367 loss_iou: 0.170256 loss_dfl: 0.869540 loss_l1: 0.361416 eta: 0:02:44 batch_cost: 0.5446 data_cost: 0.0055 ips: 29.3816 images/s [10/02 03:01:24] ppdet.engine INFO: Epoch: [57] [ 0/75] learning_rate: 0.000029 loss: 1.627233 loss_cls: 0.764908 loss_iou: 0.166364 loss_dfl: 0.872990 loss_l1: 0.351342 eta: 0:02:03 batch_cost: 0.5433 data_cost: 0.0054 ips: 29.4497 images/s [10/02 03:02:12] ppdet.engine INFO: Epoch: [58] [ 0/75] learning_rate: 0.000025 loss: 1.621432 loss_cls: 0.766320 loss_iou: 0.165519 loss_dfl: 0.872478 loss_l1: 0.342992 eta: 0:01:22 batch_cost: 0.5474 data_cost: 0.0084 ips: 29.2273 images/s [10/02 03:03:01] ppdet.engine INFO: Epoch: [59] [ 0/75] learning_rate: 0.000022 loss: 1.618331 loss_cls: 0.764125 loss_iou: 0.167583 loss_dfl: 0.870914 loss_l1: 0.356742 eta: 0:00:41 batch_cost: 0.5461 data_cost: 0.0093 ips: 29.2967 images/s [10/02 03:03:50] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/02 03:03:50] ppdet.engine INFO: Eval iter: 0 [10/02 03:03:55] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [10/02 03:03:55] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 77.04% [10/02 03:03:55] ppdet.engine INFO: Total sample number: 200, averge FPS: 36.8503525942714 [10/02 03:03:55] ppdet.engine INFO: Best test bbox ap is 0.772.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2.5 ppyoloe+l,mAP=84.71%,3571s
60epoch共3571s,差不多一个epoch1分钟。
# bs=16,lr=0.00025,epoch=60,time=3571s
%cd ~/work/PaddleDetection/
!python -u tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco-Copy1.yml \
--use_vdl=true \
--vdl_log_dir=vdl_dir/scalar \
--eval --amp \
-o output_dir=output/ppyoloe_l_plus_10e\
snapshot_epoch=2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[10/01 16:52:44] ppdet.engine INFO: Epoch: [50] [ 0/87] learning_rate: 0.000061 loss: 1.627664 loss_cls: 0.770285 loss_iou: 0.169481 loss_dfl: 0.865384 loss_l1: 0.369002 eta: 0:07:53 batch_cost: 0.5706 data_cost: 0.0075 ips: 28.0426 images/s [10/01 16:53:44] ppdet.engine INFO: Epoch: [51] [ 0/87] learning_rate: 0.000056 loss: 1.632395 loss_cls: 0.771937 loss_iou: 0.170442 loss_dfl: 0.873482 loss_l1: 0.374619 eta: 0:07:07 batch_cost: 0.5764 data_cost: 0.0108 ips: 27.7600 images/s [10/01 16:54:41] ppdet.engine INFO: Epoch: [52] [ 0/87] learning_rate: 0.000051 loss: 1.632395 loss_cls: 0.770529 loss_iou: 0.171579 loss_dfl: 0.871368 loss_l1: 0.374107 eta: 0:06:19 batch_cost: 0.5642 data_cost: 0.0099 ips: 28.3589 images/s [10/01 16:55:38] ppdet.engine INFO: Epoch: [53] [ 0/87] learning_rate: 0.000046 loss: 1.612642 loss_cls: 0.753961 loss_iou: 0.171108 loss_dfl: 0.863146 loss_l1: 0.360852 eta: 0:05:32 batch_cost: 0.5599 data_cost: 0.0120 ips: 28.5753 images/s [10/01 16:56:34] ppdet.engine INFO: Epoch: [54] [ 0/87] learning_rate: 0.000042 loss: 1.606246 loss_cls: 0.752236 loss_iou: 0.168287 loss_dfl: 0.849859 loss_l1: 0.353835 eta: 0:04:44 batch_cost: 0.5536 data_cost: 0.0086 ips: 28.9019 images/s [10/01 16:57:30] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/01 16:57:31] ppdet.engine INFO: Eval iter: 0 [10/01 16:57:36] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [10/01 16:57:36] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 84.07% [10/01 16:57:36] ppdet.engine INFO: Total sample number: 200, averge FPS: 35.00615985304822 [10/01 16:57:36] ppdet.engine INFO: Best test bbox ap is 0.841. [10/01 16:57:42] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/01 16:57:43] ppdet.engine INFO: Epoch: [55] [ 0/87] learning_rate: 0.000038 loss: 1.600404 loss_cls: 0.750651 loss_iou: 0.167692 loss_dfl: 0.850050 loss_l1: 0.356826 eta: 0:03:57 batch_cost: 0.5343 data_cost: 0.0044 ips: 29.9444 images/s [10/01 16:58:42] ppdet.engine INFO: Epoch: [56] [ 0/87] learning_rate: 0.000034 loss: 1.598746 loss_cls: 0.750651 loss_iou: 0.167707 loss_dfl: 0.855518 loss_l1: 0.357439 eta: 0:03:09 batch_cost: 0.5491 data_cost: 0.0042 ips: 29.1369 images/s [10/01 16:59:38] ppdet.engine INFO: Epoch: [57] [ 0/87] learning_rate: 0.000030 loss: 1.617750 loss_cls: 0.758843 loss_iou: 0.169149 loss_dfl: 0.867757 loss_l1: 0.359384 eta: 0:02:22 batch_cost: 0.5589 data_cost: 0.0055 ips: 28.6267 images/s [10/01 17:00:33] ppdet.engine INFO: Epoch: [58] [ 0/87] learning_rate: 0.000026 loss: 1.615083 loss_cls: 0.764672 loss_iou: 0.169149 loss_dfl: 0.866775 loss_l1: 0.358770 eta: 0:01:34 batch_cost: 0.5437 data_cost: 0.0114 ips: 29.4296 images/s [10/01 17:01:29] ppdet.engine INFO: Epoch: [59] [ 0/87] learning_rate: 0.000023 loss: 1.600423 loss_cls: 0.762148 loss_iou: 0.168355 loss_dfl: 0.865254 loss_l1: 0.353518 eta: 0:00:47 batch_cost: 0.5460 data_cost: 0.0144 ips: 29.3045 images/s [10/01 17:02:26] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1 [10/01 17:02:27] ppdet.engine INFO: Eval iter: 0 [10/01 17:02:32] ppdet.metrics.metrics INFO: Accumulating evaluatation results... [10/01 17:02:32] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 84.71% [10/01 17:02:32] ppdet.engine INFO: Total sample number: 200, averge FPS: 36.10603852107679 [10/01 17:02:32] ppdet.engine INFO: Best test bbox ap is 0.847. [10/01 17:02:38] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyoloe_plus_crn_l_80e_coco-Copy1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
!visualdl --logdir PaddleDetection/vdl_dir/scalar这种是打不开的,因为用的是别人的服务器- 要使用直接用AI Stadio 上左侧的可视化窗口就行
- 很多参数用–xx来写是不行的,–help里面列出的都是train.py文件本身加的一些参数,可以用–来更改。train.py之外的参数,需要前面加-o来改,比如-o weight=‘path’,output_dir=‘path’,log_iter/snapshot_epoch/lr等等。这样直接在跑的时候改参数就行,不用每次都改yaml文件。
2.6 推理测试集
--draw_threshold:可视化时分数的阈值,默认大于0.5的box会显示出来keep_top_k表示设置输出目标的最大数量,默认值为100,用户可以根据自己的实际情况进行设定。- 推理默认只输出图片,以前设置
--save_txt=True会输出txt文件存储bbox,新版本--save_txt没了,改成了--save_results=True,存储bbox为json文件。 - 保存的模型太多了,最佳模型在
ppyoloes_plus_80e文件夹,其它都删了
!python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco-Copy1.yml \
--infer_dir=../VOCdevkit/test/images \
--output_dir=infer_output/ \
-o weights=output/ppyoloe_l_plus_80e/best_model.pdparams \
--draw_threshold=0.3 \
--save_results=True
- 1
- 2
- 3
- 4
- 5
- 6
from PIL import Image
image_test='infer_output/1406.jpg'
image = Image.open(image_test)
image.show()
- 1
- 2
- 3
- 4
- 5

- 注意:测试集使用bs=8可以明显加快推理速度,但是生成的json文件,bbox/labels/score都是一个batch的数据,不是一张图片,处理起来更麻烦。
- 比如之前bs=1,生成的json文件,每个类别是400items对应400张图,每个item是300个元素值,貌似是一张图预测300个目标
- bs=8时,item=50,每个item数量不一样,因为有的批不满8张图(推测)
2.7 根据格式提交结果
import glob import os import json import pandas as pd class Result(object): def __init__(self): self.imagesPath = '/home/aistudio/work/VOCdevkit/test/images' self.bboxPath = '/home/aistudio/work/PaddleDetection/infer_output3/bbox.json' self.submissionPath = '/home/aistudio/work/submission.csv' def run(self): images = self.get_image_ids() bbox = self.get_bbox() results = [] for i in range(400): image_id = images[i] for j in range(len(bbox['bbox'][i])): bbox_ = [round(i,4) for i in bbox['bbox'][i][j]] item = [ image_id, bbox_, int(bbox['label'][i][j]), round(bbox['score'][i][j],2) ] results.append(item) submit = pd.DataFrame(results, columns=['image_id', 'bbox','category_id','confidence']) submit[['image_id', 'bbox','category_id','confidence']].to_csv(self.submissionPath, index=False) def get_image_ids(self): idx=[] for image in os.listdir(self.imagesPath): if image.split('.')[1]=='jpg': idx.append(image.split('.')[0]) idx.sort() return idx def get_bbox(self): with open(self.bboxPath, 'r', encoding='utf-8') as bbox: bbox = json.load(bbox) return bbox resultObj = Result() resultObj.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
最后生成的csv文件,是每张图包含300个检测目标,筛选其中scroe>0.3的作为最终结果一共1302个检测框)。最终得分41.32分。
import pandas as pd
df=pd.read_csv('../submission.csv')
df_demo=df.loc[df.confidence>0.3]
df_demo.to_csv('submission.csv',index=None) # paddledatection文件夹下
df_demo
- 1
- 2
- 3
- 4
- 5
image_id bbox category_id confidence
0 1400 [5.4677, 0.3653, 199.2925, 61.0883] 0 0.54
1 1400 [2.2173, 71.8166, 195.2088, 131.9529] 0 0.47
2 1400 [0.6983, 26.4009, 200.0532, 131.7431] 0 0.44
3 1400 [21.8238, 151.2348, 187.4655, 199.7138] 0 0.32
343 1401 [128.7988, 43.0498, 181.4566, 196.0749] 1 0.89
... ... ... ... ...
119029 1797 [10.5545, 124.7763, 121.6406, 187.9] 0 0.33
119030 1797 [136.0446, 89.9455, 199.4311, 198.8453] 0 0.32
119031 1797 [12.9682, 91.6822, 199.3519, 193.211] 0 0.31
119393 1798 [0.2173, 0.4157, 199.9586, 160.8067] 2 0.83
119626 1799 [5.0449, 107.328, 198.9616, 185.1402] 0 0.39
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
三、yolov5训练(37.746分)
3.1 导入相关库
import numpy as np
from tqdm.notebook import tqdm
tqdm.pandas()
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
import glob
import shutil
import sys
sys.path.append('../input/paddleirondetection')
from joblib import Parallel, delayed
from IPython.display import display
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.2 数据预处理
3.2.1 将数据集移动到work下的dataset文件夹
- 此时路径为输出文件夹根目录,即
/kaggle/working - 新建dataset文件夹,将原训练集图片移动到dataset下,重命名为images
- 原xml标注文件移动到dataset下,重命名为Annotations
- 测试集移动到dataset
!mkdir dataset
!cp -r ../input/paddleirondetection/test/test dataset
!cp -r ../input/paddleirondetection/train/train/IMAGES dataset # 直接在
!cp -r ../input/paddleirondetection/train/train/ANNOTATIONS dataset
!mv ./dataset/ANNOTATIONS ./dataset/Annotations
!mv ./dataset/IMAGES ./dataset/images
!ls dataset/images
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.2 用pandas处理图片名和xml文件名
# 遍历图片和标注文件夹,将所有文件后缀正确的文件添加到列表中 import os import pandas as pd ls_xml,ls_image=[],[] for xml in os.listdir('../input/paddleirondetection/train/train/ANNOTATIONS'): if xml.split('.')[1]=='xml': ls_xml.append(xml) for image in os.listdir('../input/paddleirondetection/train/train/IMAGES'): if image.split('.')[1]=='jpg': ls_image.append(image) df=pd.DataFrame(ls_image,columns=['image']) df.sort_values('image',inplace=True) df=df.reset_index(drop=True) s=pd.Series(ls_xml).sort_values().reset_index(drop=True) df['xml']=s df.head(3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
image xml
0 0.jpg 0.xml
1 1.jpg 1.xml
2 10.jpg 10.xml
- 1
- 2
- 3
- 4
写入label_list.txt文件,echo -e表示碰到转义符('\n’等)按对应特殊字符处理。(这个是以前VOC数据集用的,可忽略)
!echo -e "crazing\ninclusion\npitted_surface\nscratches\npatches\nrolled-in_scale" > dataset/label_list.txt
!cat dataset/label_list.txt
- 1
- 2
crazing
inclusion
pitted_surface
scratches
patches
rolled-in_scale
- 1
- 2
- 3
- 4
- 5
- 6
3.2.3 生成yolov5格式的标注文件
- rootpath是Annotations的上一个目录
- main函数中的list可以从目录读取,也可以从df读取
- list=df.xml.values
- list=os.listdir(xmlpath)
- voc格式数据集标注框是以
[xmin,ymin,xmax,ymax]表示 - 最终在dataset/labels文件夹下,生成的txt标注文件格式是:
cls,[x_center,y_center,w,h],且是归一化之后的结果。(将x_center和标注框宽度w除以图像宽度,将y_center与标注框高度h除以图像高度。这样xywh的值域都是[0,1])
5 0.6075 0.14250000000000002 0.775 0.165
5 0.505 0.6825 0.79 0.525
- 1
- 2
以下转换代码来自github上的objectDetectionDatasets项目:
#!pip install mmcv import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join classes = ['crazing','inclusion','pitted_surface','scratches','patches','rolled-in_scale'] def convert(size, box): dw = 1./(size[0]) dh = 1./(size[1]) x = (box[0] + box[1])/2.0 - 1 y = (box[2] + box[3])/2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh if w>=1: w=0.99 if h>=1: h=0.99 return (x,y,w,h) def convert_annotation(rootpath,xmlname): xmlpath = rootpath + '/Annotations' xmlfile = os.path.join(xmlpath,xmlname) with open(xmlfile, "r", encoding='UTF-8') as in_file: txtname = xmlname[:-4]+'.txt' # 生成对应的txt文件名 print(txtname) txtpath = rootpath + '/labels' # 生成的.txt文件会被保存在worktxt目录下 if not os.path.exists(txtpath): os.makedirs(txtpath) txtfile = os.path.join(txtpath,txtname) with open(txtfile, "w+" ,encoding='UTF-8') as out_file: tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) out_file.truncate() for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult)==1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') rootpath='dataset' xmlpath=rootpath+'/Annotations' list=df.xml.values for i in range(0,len(list)) : path = os.path.join(xmlpath,list[i]) # 判断Annotations下是否是xml文件或XML文件 if ('.xml' in path)or('.XML' in path): convert_annotation(rootpath,list[i]) print('done', i) else: print('not xml file',i)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
!cat dataset/labels/0.txt
- 1
5 0.6075 0.14250000000000002 0.775 0.165
5 0.505 0.6825 0.79 0.525
- 1
- 2
!ls ../dataset
- 1
Annotations images label_list.txt labels test
- 1
3.3 使用yolov5进行训练
3.3.1 安装yolov5
安装完之后路径是working/yolov5
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
from yolov5 import utils
display = utils.notebook_init() # check
- 1
- 2
- 3
- 4
- 5
YOLOv5 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/52172Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

