
- 1向着阳光的华为,淬火而行的哪吒
- 2用HTML和Javascript编写一个可在线编辑并存储表格的网页_js table 在线编辑
- 3百度飞桨系列课程:百度架构师手把手带你零基础实践深度学习——21日学习打卡(第二周第三日)_得到两个类别的预测概率,并沿第一个维度级联
- 4经典必读:门控循环单元(GRU)的基本概念与原理
- 5UI和UI有什么不同,是如何协助的_ui不不不
- 6使用CSS自定义属性实现页面的主题切换_--bg-color
- 7Qt图形视图框架三--坐标系统简介_qgraphicsscene 坐标系
- 8Unity编辑器扩展——自定义窗口_unity 自定义编辑窗口
- 9RHEL5中实现对用户家目录/home的迁移
- 10Pygame 基础教程01: Python (Pygame) 游戏开发模块简介与安装_pygame模块
【Python爬虫】基于selenium库爬取京东商品数据——以“七夕”为例_京东图书 selenium
赞
踩
小白学爬虫,费了一番功夫终于成功了哈哈!本文将结合本人踩雷经历,分享给各位学友~
一、导包
- import time
- import csv
- from selenium import webdriver
二、创建csv文件
用写入方式打开名为data的csv文件,并确定将要提取的五项数据。
- f = open('data.csv',mode = 'w',encoding ='utf-8',newline = '')
- #将表头信息写入文件
- csv_writer = csv.DictWriter(f,fieldnames = ['标题','价格','评论','店名','详情页'])
- csv_writer.writeheader()
三、搜索商品页并加载数据
- #实例化浏览器对象
- driver = webdriver.Edge('C:\Windows\SystemApps\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\msedgedriver.exe')
- #访问京东网址
- driver.get('https://www.jd.com/')
- #定位搜索框,并输入查找内容‘七夕’
- driver.find_element_by_id('key').send_keys('七夕')
- #点击搜索按钮
- driver.find_element_by_class_name('button').click()
- #等待界面数据加载
- driver.implicitly_wait(10)
-
- #有些网页是鼠标一边下移一边加载,该函数使页面数据全部加载
- def drop_down():
- for x in range(1,12,2):
- time.sleep(1)
- j = x / 9
- # document.documetnElement,scrollTop 指定滚动条的位置
- # document.documentElement.scrollHeight 获取浏览器页面的最大高度
- js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
- driver.execute_script(js)

上面第一行代码值得一提,driver = webdriver.Edge()括号内为Edge浏览器驱动程序地址,需要在Edge浏览器设置中查找Edge浏览器版本,并下载对应版本的驱动程序,具体操作如下:
1.在设置中找到Edge浏览器对应版本
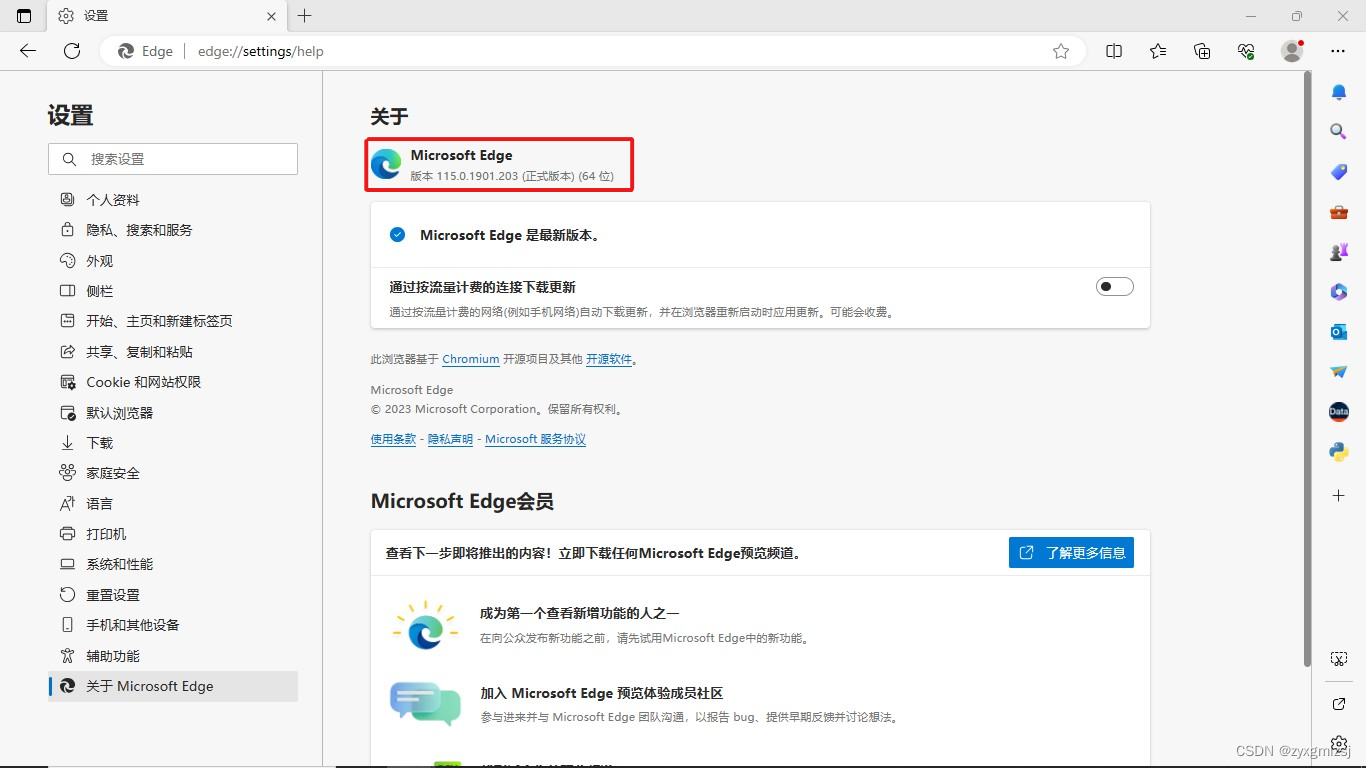
2.下载驱动程序
驱动路径来源(读者需自行替换):
Step1:根据官网提供网址 Microsoft Edge WebDriver - Microsoft Edge Developer
找到和自己Edge浏览器版本一致的驱动程序。这里等待时间稍微有点长,请耐心等待。
Step2:将安装包解压到不包含中文的路径下,获得msedgedriver.exe文件
Step3:将完整路径填入到driver = webdriver.Edge()括号内,注意路径需包含\msedgedriver.exe
第三行代码定位搜索框的流程也介绍一下:
首先,打开京东,在空白处右击,单击“检查”,弹出框图如下
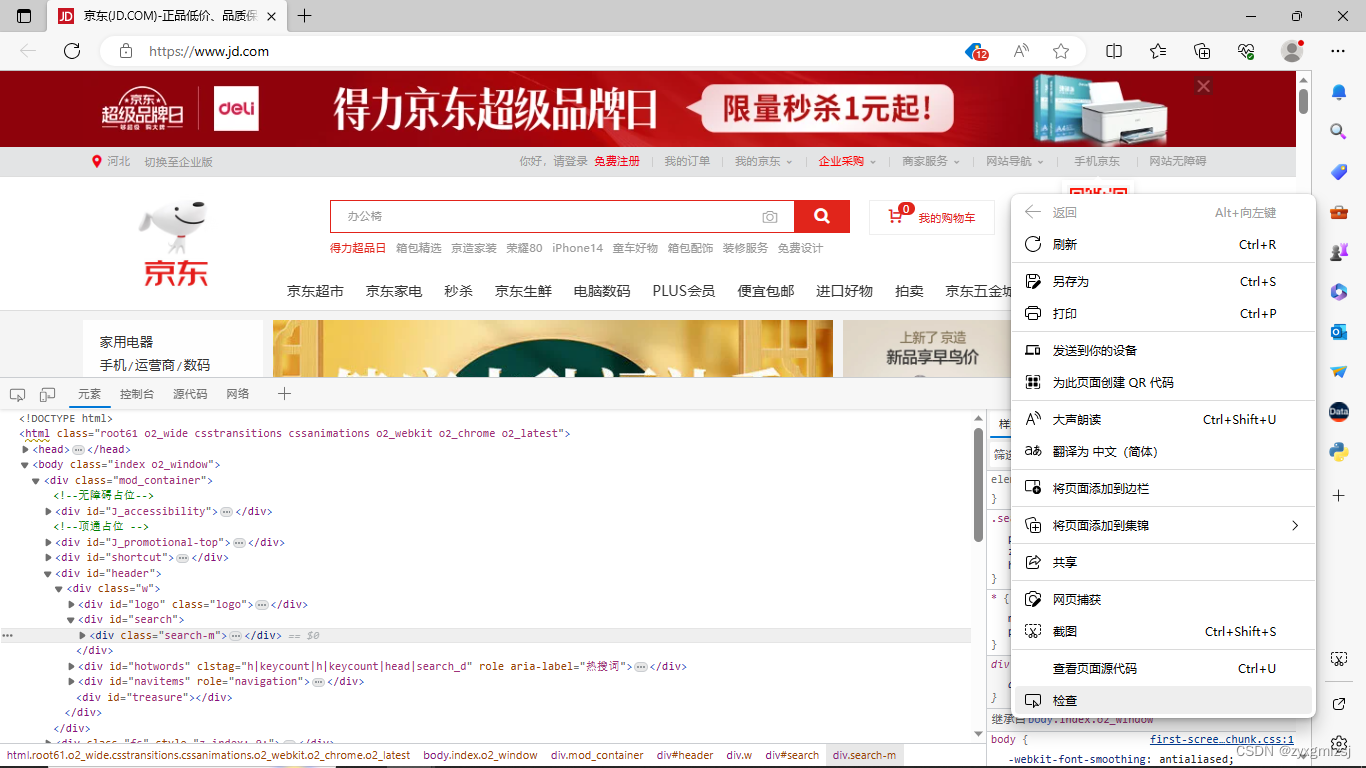
单击弹出框框左上角的标识,并将鼠标放在搜索框中,再单击一下固定位置,找到对应代码。

找到其中的id为‘key’,可根据该项特征定位搜索框。第四行代码定位搜索按钮采取相同方式定位,不同的是搜索按钮根据类名定位,找到class = “……”中的内容即可。
四、获取多页数据并逐行写入csv文件
- #提取第1~7页的内容
- for page in range(1,7):
- #调用函数
- drop_down()
- #获取所有商品对应标签(列表),注意此处是elements而不是element
- lis = driver.find_elements_by_css_selector('.gl-item')
- #print(lis)
- #将列表元素一个个拿出来
- for li in lis:
- title = li.find_element_by_css_selector('.p-name em').text.replace('\n','')
- price = li.find_element_by_css_selector('.p-price strong i').text
- comment = li.find_element_by_css_selector('.p-commit strong').text
- shop = li.find_element_by_css_selector('.p-shop span a').text
- link = li.find_element_by_css_selector('.p-img a').get_attribute('href')
-
- dit = {
- '标题':title,
- '价格':price,
- '评论':comment,
- '店名':shop,
- '详情页':link
- }
- #写入csv
- csv_writer.writerow(dit)
- #及时刷新缓冲区
- f.flush()
- print(dit)
- #点击下一页按钮
- driver.find_element_by_class_name('pn-next').click()
发现出现了find_element_by_css_selector('……'),那省略号的内容又该在哪儿找呢?我们以代码lis = driver.find_elements_by_css_selector('.gl-item')为例说明一下。
在首页搜索“七夕”,得到商品页。
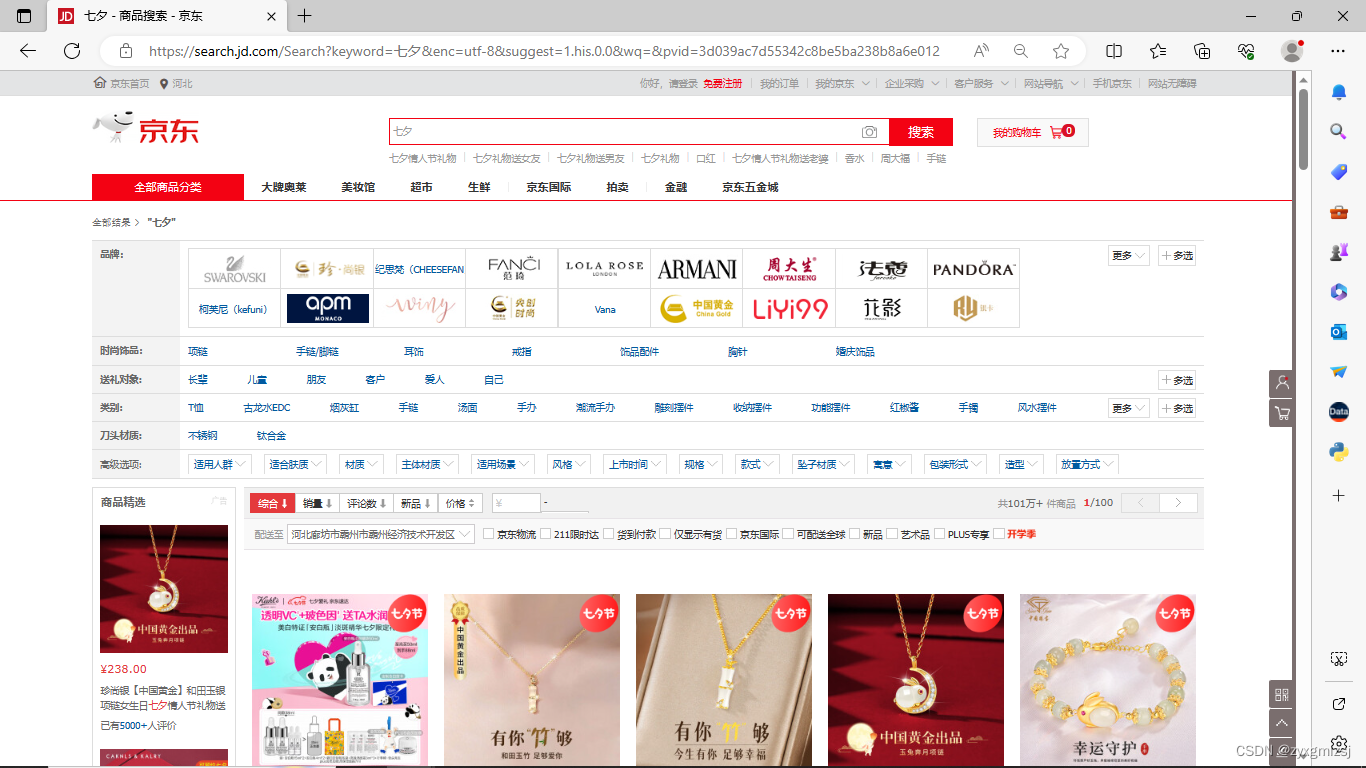
同样右击,单击“检查”,单击弹出框左上角标识,把鼠标移动到商品上(要全部框选),单击一下固定代码位置 ,再查看右侧框中选项。

虽然含有 .goods-list-v2 和 .gl-item 两项,然而,.gl-item足以标记所有商品,故省略号仅填.gl-item即可。
五、代码汇总
- import time
- import csv
- from selenium import webdriver
-
-
- f = open('data.csv',mode = 'w',encoding ='utf-8',newline = '')
- #将表头信息写入文件
- csv_writer = csv.DictWriter(f,fieldnames = ['标题','价格','评论','店名','详情页'])
- csv_writer.writeheader()
-
- #实例化浏览器对象(第一句需要修改,具体方法见上文)
- driver = webdriver.Edge('C:\Windows\SystemApps\Microsoft.MicrosoftEdge_8wekyb3d8bbwe\msedgedriver.exe')
- #访问京东网址
- driver.get('https://www.jd.com/')
- #定位搜索框,并输入查找内容‘七夕’
- driver.find_element_by_id('key').send_keys('七夕')
- #点击搜索按钮
- driver.find_element_by_class_name('button').click()
- #等待界面数据加载
- driver.implicitly_wait(10)
-
- #有些网页是鼠标一边下移一边加载,该函数使页面数据全部加载
- def drop_down():
- for x in range(1,12,2):
- time.sleep(1)
- j = x / 9
- # document.documetnElement,scrollTop 指定滚动条的位置
- # document.documentElement.scrollHeight 获取浏览器页面的最大高度
- js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
- driver.execute_script(js)
-
- #提取第1~7页的内容
- for page in range(1,7):
- #调用函数
- drop_down()
- #获取所有商品对应标签(列表),注意此处是elements而不是element
- lis = driver.find_elements_by_css_selector('.gl-item')
- #print(lis)
- #将列表元素一个个拿出来
- for li in lis:
- title = li.find_element_by_css_selector('.p-name em').text.replace('\n','')
- price = li.find_element_by_css_selector('.p-price strong i').text
- comment = li.find_element_by_css_selector('.p-commit strong').text
- shop = li.find_element_by_css_selector('.p-shop span a').text
- link = li.find_element_by_css_selector('.p-img a').get_attribute('href')
-
- dit = {
- '标题':title,
- '价格':price,
- '评论':comment,
- '店名':shop,
- '详情页':link
- }
- #写入csv
- csv_writer.writerow(dit)
- #及时刷新缓冲区
- f.flush()
- print(dit)
- #点击下一页按钮
- driver.find_element_by_class_name('pn-next').click()
感谢读者大大读到此处~学习辛苦啦!



