
热门标签
热门文章
- 1python socket中实现SSL/TLS认证_python ssl socket
- 2ubuntu20.04 配置pytorch深度学习环境 + SSD目标检测_ubuntu 20.04 pytorch 目标检测 c++
- 3Python游戏开发:最强大脑第一关,数字华容道
- 4粤嵌GEC6818,基于LVGL和mplayer的音视频播放器_基于gec6818音乐播放器
- 52023年Python超详细学习资料,分享给需要的人(新手入门、大学生)_python2023 资源
- 6Ruoyi-vue (若依)项目拉取代码~ 本地部署--运行环境配置_git怎么拉取若依源码
- 7OC语言基础知识
- 8python脚本开机自启_一键开机启动添加(python)_开机启动python脚本
- 9MongoDB详解--使用Java对MongoDB的分页查询,排序查询,比较运算条件查询_java mongocollection find 分页 排序
- 10DRUID连接池的使用
当前位置: article > 正文
python pdf提取数据_python从PDF中提取数据的示例
作者:代码世界探险家 | 2024-01-31 19:07:48
赞
踩
python从pdf提取数据
01
前言
数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据。然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸如“csv”之类的格式,以便用于分析或构建模型。
在本文中,我们将重点讨论如何从pdf文件中提取数据表。类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像。我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分析和构建模型的格式。我们将给出一个实例。
02
示例:使用Python从PDF文件中提取一个表格
a)将表复制到Excel并保存为table_1_raw.csv
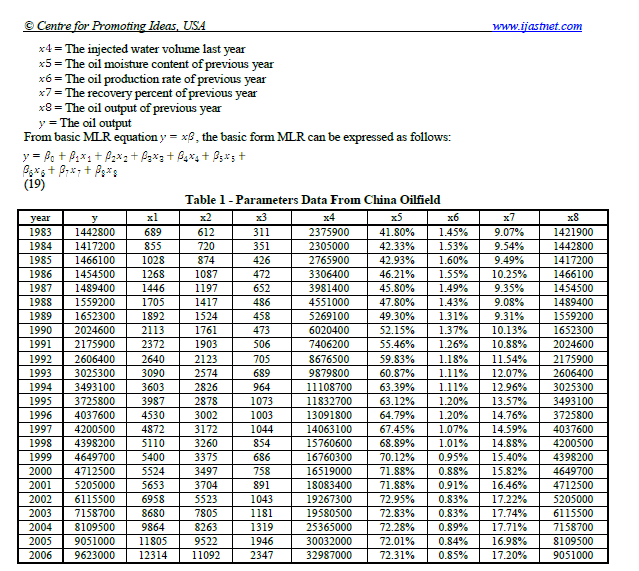
数据以一维格式存储,必须进行重塑、清理和转换。
b)导入必要的库
import pandas as pd
import numpy as np
c)导入原始数据,重新定义数据
df=pd.read_csv("table_1_raw.csv", header=
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/51521?site
推荐阅读

相关标签

