
- 1JavaScript随机数的方法Math.random()_js math.random()
- 2【计算机网络】概述|分层体系结构|OSI参考模型|TCP/IP参考模型|网络协议、层次、接口
- 3若依项目框架解析_若依框架
- 4破解Hopper Disassembler v3.7.8 for mac的艰难历程_hopper disassembler 安装 “hopper disassembler”意外退出。
- 5c++剑指offer刷题思路_当a为空时提醒,当b为空时怎么办
- 6每年有20万人进军IT行业,为何人才缺口依旧这么大?_每年毕业那么多程序员为什么还不过剩
- 7MSE Nacos 配置变更审计平台使用指南
- 8基于python的聊天室_Python实现文字聊天室
- 9小程序可以通过以下几种方式下发消息_小程序怎么给用户推送消息
- 10使用 FastGPT 和智能微秘书,打造你的超级微信助手!
如何基于HBase构建容纳大规模数据、支撑高并发、毫秒响应、稳定高效的OLTP实时系统_hbase可以用于高并发查询的oltp业务么
赞
踩
前言
本文致力于从架构原理、集群部署、性能优化与使用技巧等方面,阐述在如何基于HBase构建容纳大规模数据、支撑高并发、毫秒响应、稳定高效的OLTP实时系统 。
一、架构原理
1.1 基本架构
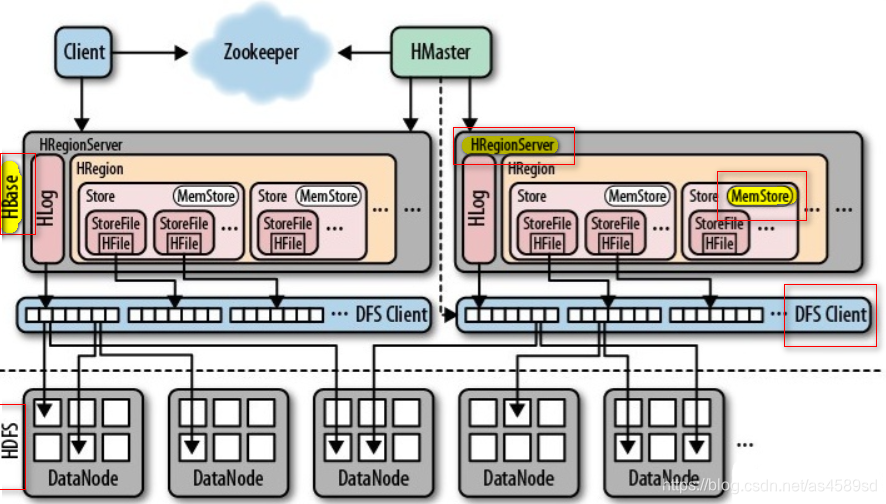
从上层往下可以看到HBase架构中的角色分配为:
Client——>Zookeeper——>HMaster——>RegionServer——>HDFS
Client
Client是执行查询、写入等对HBase表数据进行增删改查的使用方,可以是使用HBase Client API编写的程序,也可以是其他开发好的HBase客户端应用。
Zookeeper
Zookeeper同HDFS一样,HBase使用Zookeeper作为集群协调与管理系统。
在HBase中其主要的功能与职责为:
- 存储整个集群HMaster与RegionServer的运行状态
- 实现HMaster的故障恢复与自动切换
- 为Client提供元数据表的存储信息
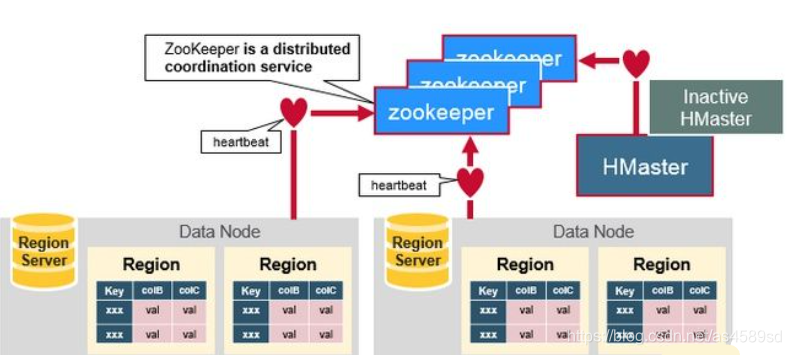
- HMaster、RegionServer启动之后,将会在Zookeeper上注册并创建节点(/hbasae/master 与 /hbase/rs/*),同时 Zookeeper 通过Heartbeat的心跳机制来维护与监控节点状态,一旦节点丢失心跳,则认为该节点宕机或者下线,将清除该节点在Zookeeper中的注册信息。
- 当Zookeeper中任一RegionServer节点状态发生变化时,HMaster都会收到通知,并作出相应处理,例如RegionServer宕机,HMaster重新分配Regions至其他RegionServer,以保证集群整体可用性。
- 当HMaster宕机时(Zookeeper监测到心跳超时),Zookeeper中的 /hbasae/master 节点将会消失,同时Zookeeper通知其他备用HMaster节点,重新创建 /hbasae/master 并转化为active master。
协调过程示意图如下:
除了作为集群中的协调者,Zookeeper还为Client提供了 hbase:meta 表的存储信息。
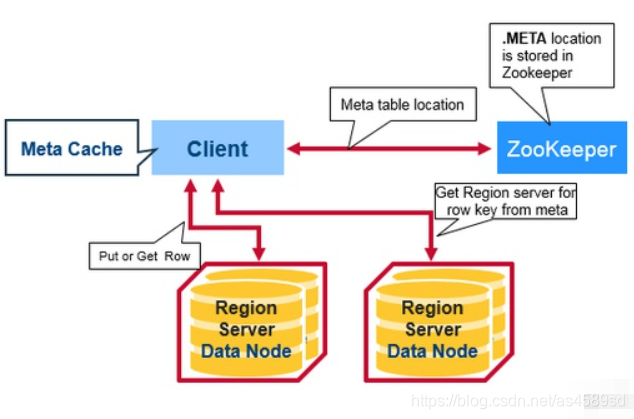
客户端要访问HBase中的数据,只需要知道Zookeeper集群的连接信息,访问步骤如下:
- 客户端将从Zookeeper(/hbase/meta-region-server)获得 hbase:meta 表存储在哪个RegionServer,缓存该位置信息
- 查询该RegionServer上的 hbase:meta 表数据,查找要操作的 rowkey所在的Region存储在哪个RegionServer中,缓存该位置信息
- 在具体的RegionServer上,根据rowkey检索该Region数据
可以看到,客户端操作数据过程并不需要HMaster的参与,通过Zookeeper间接访问RegionServer来操作数据。
第一次请求将会产生3次RPC,之后使用相同的rowkey时,客户端将直接使用缓存下来的位置信息,直接访问RegionServer,直至缓存失效(Region失效、迁移等原因)。
通过Zookeeper的读写流程如下:
hbase:meta 表存储了集群中所有Region的位置信息。
表结构如下:
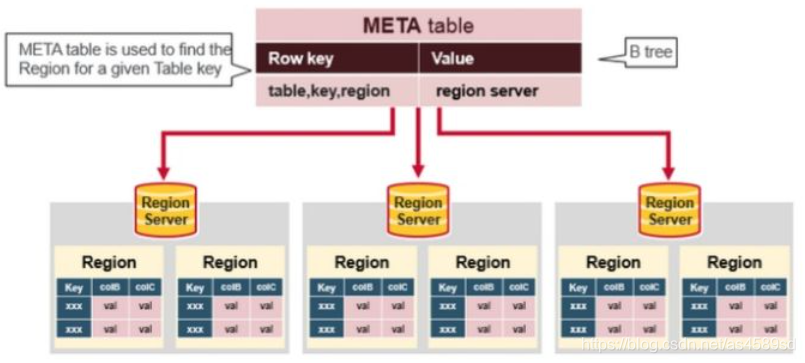
| rowkey规则:${表名},${起始键},${region时间戳}.${encode编码}. |
| 列簇:info |
| 列 |
| state:Region状态,正常情况下为 OPEN |
| serverstartcode:RegionServer启动的13位时间戳 |
| server:所在RegionServer 地址和端口,如cdh85-47:16020 |
| sn:server和serverstartcode组成,如cdh85-47:16020,1549491783878 |
| seqnumDuringOpen:Region在线时长的二进制串 |
| regioninfo:region的详细信息,如:ENCODED、NAME、STARTKEY、ENDKEY等 |
| ENCODED:基于${表名},${起始键},${region时间戳}生成的32位md5字符串, region数据存储在hdfs上时使用的唯一编号,可以从meta表中根据该值定位到hdfs中的具体路径。 rowkey中最后的${encode编码}就是 ENCODED 的值,其是rowkey组成的一部分。 |
| NAME:与ROWKEY值相同 |
| STARTKEY:该region的起始键 |
| ENDKEY:该region的结束键 |
简单总结Zookeeper在HBase集群中的作用如下:
- 对于服务端,是实现集群协调与控制的重要依赖。
- 对于客户端,是查询与操作数据必不可少的一部分。
HMaster
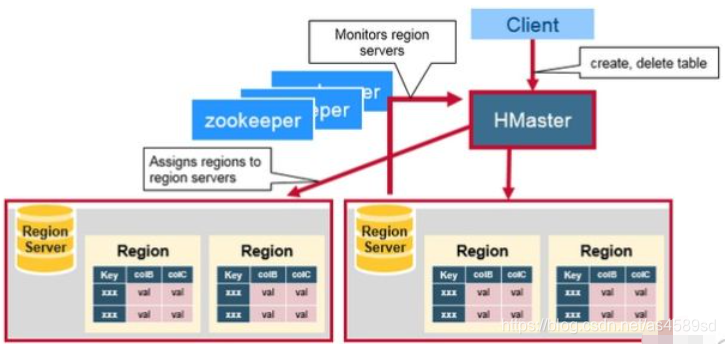
- HBase整体架构中HMaster的功能与职责如下:
- 管理RegionServer,监听其状态,保证集群负载均衡且高可用。
- 管理Region,如新Region的分配、RegionServer宕机时该节点Region的分配与迁移
- 接收客户端的DDL操作,如创建与删除表、列簇等信息
- 权限控制
如我们前面所说的,HMaster 通过 Zookeeper 实现对集群中,各个 RegionServer 的监控与管理,在RegionServer 发生故障时,可以发现节点宕机,并转移 Region 至其他节点,以保证服务的可用性。
但是HBase的故障转移并不是无感知的,相反故障转移过程中,可能会直接影响到线上请求的稳定性,造成段时间内的大量延迟。
在分布式系统的 CAP定理中(Consistency一致性、Availability可用性、Partition tolerance分区容错性),分布式数据库基本特性都会实现P,但是不同的数据库对于A和C各有取舍。
如HBase选择了C,而通过Zookeeper这种方式来辅助实现A(虽然会有一定缺陷),而Cassandra选择了A,通过其他辅助措施实现了C,各有优劣。
对于HBase集群来说,HMaster是一个内部管理者,除了DDL操作并不对外(客户端)开放,因而HMaster的负载是比较低的。
造成HMaster压力大的情况,可能是集群中存在多个(两个或者三个以上)HMaster,备用的Master会定期与Active Master通信,以获取最新的状态信息,以保证故障切换时自身的数据状态是最新的,因而Active Master可能会收到大量来自备用Master的数据请求。
RegionServer
RegionServer在HBase集群中的功能与职责:
- 根据HMaster的region分配请求,存放和管理Region
- 接受客户端的读写请求,检索与写入数据,产生大量IO
- 一个RegionServer中存储并管理者多个Region,是HBase集群中真正 存储数据、接受读写请求 的地方,是HBase架构中最核心、同时也是最复杂的部分。
RegionServer内部结构图如下:
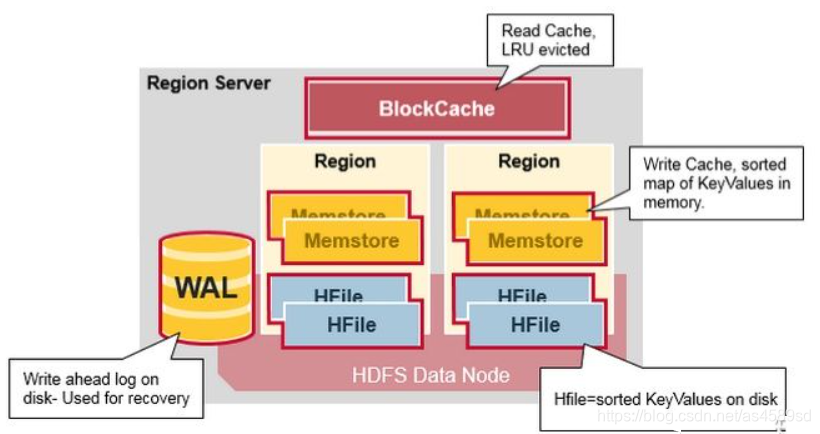
BlockCache
BlockCache为RegionServer中的读缓存,一个RegionServer共用一个BlockCache。
RegionServer处理客户端读请求的过程:
- 在BlockCache中查询是否命中缓存。
- 缓存未命中,则定位到存储该数据的Region。
- 检索Region Memstore中,是否有所需要的数据。
- Memstore中未查得,则检索Hfiles。
- 任一过程查询成功,则将数据返回给客户端,并缓存至BlockCache。
BlockCache有两种实现方式,有不同的应用场景,各有优劣:
- On-Heap的LRUBlockCache
- 优点:直接从Java堆内内存获取,响应速度快。
- 缺陷:容易受GC影响,响应延迟不稳定,特别是在堆内存巨大的情况下。
- 适用于:写多读少型、小内存等场景。
- Off-Heap的BucketCache
- 优点:无GC影响,延迟稳定
- 缺陷:从堆外内存获取数据,性能略差于堆内内存
- 适用于:读多写少型、大内存等场景
我们将在「性能优化」一节中具体讨论如何判断应该使用哪种内存模式。
WAL
全称 Write Ahead Log ,是 RegionServer 中的预写日志。
所有写入数据,默认情况下,都会先写入WAL中,以保证RegionServer宕机重启之后,可以通过WAL来恢复数据,一个RegionServer中共用一个WAL。
RegionServer的写流程如下:
- 将数据写入WAL中
- 根据TableName、Rowkey和ColumnFamily将数据写入对应的Memstore中
- Memstore通过特定算法将内存中的数据刷写成Storefile写入磁盘,并标记WAL sequence值
- Storefile定期合小文件
WAL会通过日志滚动的操作,定期对日志文件进行清理(已写入HFile中的数据可以清除),对应HDFS上的存储路径为 /hbase/WALs/${HRegionServer_Name} 。
Region
一个Table由一个或者多个Region组成,一个Region中可以看成是Table按行切分且有序的数据块,每个Region都有自身的StartKey、EndKey。
一个Region由一个或者多个Store组成,每个Store存储该Table对应Region中一个列簇的数据,相同列簇的列,存储在同一个Store中。
同一个Table的Region,会分布在集群中不同的RegionServer上,以实现读写请求的负载均衡。故,一个RegionServer中,将会存储来自不同Table的N多个Region。
Store、Region与Table的关系可以表述如下:多个Store(列簇)组成Region,多个Region(行数据块)组成完整的Table。
其中,Store由Memstore(内存)、StoreFile(磁盘)两部分组成。
在RegionServer中,Memstore可以看成指定Table、Region、Store的写缓存(正如BlockCache小节中所述,Memstore还承载了一些读缓存的功能),以RowKey、Column Family、Column、Timestamp进行排序。如下图所示:
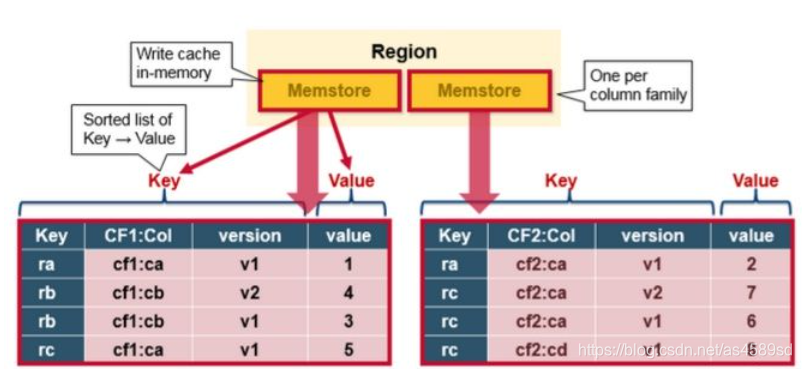
写请求到RegionServer之后,并没有立刻写入磁盘中,而是先写入内存中的Memstore(内存中数据丢失问题,可以通过回放WAL解决)以提升写入性能。
Region中的Memstore,会根据特定算法,将内存中的数据,将会刷写到磁盘,形成Storefile文件,因为数据在Memstore中为已排序,顺序写入磁盘性能高、速度快。
在这种 Log-Structured Merge Tree架构模式下,随机写入HBase拥有相当高的性能。
Memstore刷磁盘形成的StoreFile,以HFile格式,存储HBase的KV数据于HDFS之上。
HDFS
HDFS为HBase提供底层存储系统,通过HDFS的高可用、高可靠等特性,保障了HBase的数据安全、容灾与备份。
1.2写数据 与 Memstore Flush
对于客户端来说,将请求发送到需要写入的RegionServer中,等待RegionServer写入WAL、Memstore之后,即返回写入成功的ack信号。
对于RegionServer来说,写入的数据,还需要经过一系列的处理步骤。
首先我们知道Memstore是在内存中的,将数据放在内存中,可以得到优异的读写性能,但是同样也会带来麻烦:
- 内存中的数据如何防止断电丢失
- 将数据存储于内存中的代价是高昂的,空间总是有限的
对于第一个问题,虽然可以通过WAL机制在重启的时候,进行数据回放,但是对于第二个问题,则必须将内存中的数据持久化到磁盘中。
在不同情况下,RegionServer通过不同级别的刷写策略,对Memstore中的数据进行持久化,根据触发刷写动作的时机,以及影响范围,可以分为不同的几个级别:
- Memstore级别:Region中任意一个MemStore达到了 hbase.hregion.memstore.flush.size 控制的上限(默认128MB),会触发Memstore的flush。
- Region级别:Region中Memstore大小之和达到了 hbase.hregion.memstore.block.multiplier *, hbase.hregion.memstore.flush.size 控制的上限(默认 2 * 128M = 256M),会触发Memstore的flush。
- RegionServer级别:Region Server中所有Region的Memstore大小总和达到了 hbase.regionserver.global.memstore.upperLimit * hbase_heapsize 控制的上限(默认0.4,即RegionServer 40%的JVM内存),将会按Memstore由大到小进行flush,直至总体Memstore内存使用量低于 hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize 控制的下限(默认0.38, 即RegionServer 38%的JVM内存)。
- RegionServer中HLog数量达到上限:将会选取最早的 HLog对应的一个或多个Region进行flush(通过参数hbase.regionserver.maxlogs配置)。
- HBase定期flush:确保Memstore不会长时间没有持久化,默认周期为1小时。为避免所有的MemStore,在同一时间都进行flush导致的问题,定期的flush操作,有20000左右的随机延时。
- 手动执行flush:用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’,分别对一个表或者一个Region进行flush。
Memstore刷写时,会阻塞线上的请求响应,由此可以看到,不同级别的刷写,对线上的请求,会造成不同程度影响的延迟:
- 对于Memstore与Region级别的刷写,速度是比较快的,并不会对线上造成太大影响
- 对于RegionServer级别的刷写,将会阻塞发送到该RegionServer上的所有请求,直至Memstore刷写完毕,会产生较大影响
所以在Memstore的刷写方面,需要尽量避免出现RegionServer级别的刷写动作。
数据在经过Memstore刷写到磁盘时,对应的会写入WAL sequence的相关信息,已经持久化到磁盘的数据,就没有必要通过WAL记录的必要。
RegionServer会根据这个sequence值,对WAL日志进行滚动清理,防止WAL日志数量太多,RegionServer启动时,加载太多数据信息。
同样,在Memstore的刷写策略中,可以看到,为了防止WAL日志数量太多,达到指定阈值之后,将会选择WAL记录中,最早的一个或者多个Region进行刷写。
1.3读数据 与 Bloom Filter
经过前文的了解,我们现在可以知道HBase中一条数据完整的读取操作流程中,Client会和Zookeeper、RegionServer等发生多次交互请求。
基于HBase的架构,一条数据可能存在RegionServer中的三个不同位置:
- 对于刚读取过的数据,将会被缓存到BlockCache中
- 对于刚写入的数据,其存在Memstore中
- 对于之前已经从Memstore刷写到磁盘的,其存在于HFiles中
RegionServer接收到的一条数据查询请求,只需要从以上三个地方,检索到数据即可。
在HBase中的检索顺序依次是:BlockCache -> Memstore -> HFiles。
其中,BlockCache、Memstore都是直接在内存中进行高性能的数据检索。

