
- 1Jetson nano 之 ROS入门 - - 深度学习环境配置
- 2python猜数字游戏编程 使用if语句_python实现猜数字游戏
- 32020大学生就业报告:IT行业人才缺口巨大,好就业_计算机将会是下一个“夕阳”专业,现在加入it行业
- 4Python全栈(四)高级编程技巧之10.Python多任务-协程
- 5将本地项目上传到远程Git服务器 步骤_讲项目remote 到git
- 6人工智能:深度学习算法及应用——简单理解CNN卷积神经网络并python实现(带源码)_python卷积神经网络cnn的训练算法
- 7UCOSII进入HardFault_Handler()_uscos hardfault
- 8使用 FastGPT 和智能微秘书,打造你的超级微信助手!
- 9高并发处理
- 10unity 和安卓互相交互_unitypatch 和 patchandrun
c++剑指offer刷题思路_当a为空时提醒,当b为空时怎么办
赞
踩
数组中重复数字--03
1、set
2、交换索引
交换当前值和其下标值
- int i = 0;
- while(i < n) {
- if(num[i] == i) i++;continue; //是自己一样i++
- if(num[i] == num[num[i]]) return num[i]; //是第二个地方一样,则return
- swap(num[i], num[num[i]]);//不断swap
- }
二维数组查找--04
1、二分查找
- auto it = lower_bound(num.bedin(), num.end(), target);
-
- if(it != end && *it == target) return;
2、z字查找
由于列和行都递增,如果在matrix[0] [0]开始查找,则向下和向右都是增
则从第一行最后一列开始查找,如果值大了,则向左;如果值小了,则向下
替换空格--05
1、额外空间 str
2、先resize(),然后从后向前填充
从尾到头打印链表--06
1、反转数组
2、反转链表
3、栈
两个栈模拟队列--09
删除后,outstack不用返回instack
添加元素只添加入instack就行,因为outstack肯定是instack的倒序
当删除元素时,outstack没有元素,才向outstack添加元素
※旋转数组的最小数字--11
二分法
1、当mid < right时,说明最小值在[left, mid]区间
2、当mid > right时,说明最小值在[mid + 1, right]区间
3、当mid == right时,由于mid和right相等,因此直接去掉right(right的值有mid代替)
所以right -= 1;更新mid
最后return num[left]; //因为最后只找到一个数,相等时right -1超出范围
注:mid = left + (right - left)/2,而mid = (right + left)/2会超出范围,用减法而不是加法
※矩阵中的路径--12
1、主函数中for循环调用回溯,确定起点位置
2、回溯参数有:visit数组剪枝操作,起点位置(i, j),单词比较位置(0)
3、终止条件,当board[i] [j] != word[k]直接返回false;否则当 k == size - 1时,说明比较到最后一个元素并且相等返回true
4、回溯逻辑:
如果不满足终止条件,更新visit为true
先确定方向数组:10,-10,01,0-1;
然后开始遍历方向数组,更新起点位置并判断超不超出范围,并且visit为false时,回溯
当回溯为true则说明找到单词,立刻更新res并break;
当回溯为false,说明错误,会继续遍历for循环
当for循环结束运行,说明还没找到下一个单词元素,这时需要更新visit为false
1、终止条件;
visit[i][j] = true;
2、递归逻辑
-
- for(auto& dir : direction) {
- 更新起点;
- 判断超出边界
- 判断visit数组
- 都满足则回溯 bool flag = backtracking();
- if(flag) res = true; break;//找到单词立刻return
- }
- //visit = false;说明在(i,j)处没找到下一个单词,则(i, j)不满足条件
- return res;
剪绳子--14
1、dp
i个数可以拆分:1、 j 和 i - j 两段 2、j 和 再拆分 i - j 多段,取最大值
- for(int i = 2;i <= n; i++) {
- int res = 0;
- for(int j = 1; j < i; j++) { //从1开始拆分
- res= max(res, max(j * (i - j), j * dp[i - j]))//拆成两段或多段
- }
- dp[i] = res;
- }
2、数论
把数拆成最多个3好
如果余1,则要n-1个3和一个4;如果余2则要n个3和一个2
数值的整数次方--16
二分法回溯
1、终止条件 :if(n == 0) return 1.0;
2、递归逻辑:int res = backtracking(x, n / 2);
3、return n % 2 == 1 ? res * res * x : res * res
判断n是奇数还是偶数,奇数的话分为res和res和自身,偶数分为res和res
打印从1开始到最大的位数n--17
为了解决大数overflow问题,用字符串解决
1、递归遍历所有的数
- if(start == end) save();return;
- for(int i = 0; i <= 9; i++) {
- s[start] = i + '0';
- backtracking(start + 1, end); //从00 - 09,10-19 .... 90 - 99;
- }
2、去掉首位0,将字符串保存到数组中
- save() {
- int ptr = 0;
- while(ptr < size && s[ptr] == '0') ptr++; //直到ptr不等于0
- if(ptr < size) res.emplace_back(stoi(s.substr(ptr))); //如果是00,则不保存
- }
正则表达式匹配--19
1、如果p[j] == '.',则可以和s[i]匹配成功
2、如果p[j] == '*',如果p[j - 1] == s[i]时, 则去掉s的最后一个字符依旧能匹配成功,因为说明可以匹配多个;或者也是匹配0个(如ab, abb *)
dp[i] [j] = dp[i - 1] [j] | dp[i] [j - 2] ,
如果p[j - 1] != s[i]时,说明*需要取0,
则dp[i] [j] = dp[i] [j - 2];
3、如果p[j] != '*' 或 '.',则如果s[i] == s[j],dp[i] [j] = dp[i-1] [j-1]
- for(int i = 0; i <= m; i++) {
- for(int j = 1; j <= n; j++) {
- if(p[j - 1] == '*') {
- dp[i][j] |= dp[i][j - 2];
- if(match(i, j-1)) dp[i][j] |= dp[i-1][j]; //注一定用|=
- }
- else {
- if(match(i, j)) dp[i][j] = dp[i-1][j-1];
- }
- }
- }
注:只有vector<int> 才有|=
表示数值的字符串--20
使用自动机
enums STATE {....};
enums CharType {....};
然后创建哈希表,并写入状态转移关系
unordered_map<STATE, unordered_map<CharType, STATE>> transfer
先初始化状态 STATE st = BEGIN
在for循环中查找
if(transfer[st].find(chr) == transfer[st].end()) return false; //说明格式错误,转移不成功
else st = transfer[st] [chr] ; //成功转移,更新状态
最后return st == END || st == INT || st == SMALL || st == point || st == EXP_INT; //如果最后是这几个状态,则成功
树的子结构--26
1、递归B
当B为空时,说明匹配完成,return true;
当A为空时,或者A值不等于B值,说明匹配不完成,return false;
然后递归 return (A->left, B->left) && (A->right, B->right);
2、main中递归A
如果A为空或者B为空,说明匹配不上,return false;
遍历A的头节点递归 return backtracking(A, B) || main(A->left, B) || main(A->right, B);
对称的二叉树--28
因为必须全部遍历判断,所以终止条件是找到空节点才返回,或找到不相同立即返回
而找到相同不返回,继续遍历,直到遍历到空节点
※顺时针打印矩阵--29
有一个visit数组,判断边没遍历过
通过for循环打印矩阵,一共打印total个数字
然后定义方向数组 int direction[4] [2] = { {0 , 1}, {1, 0}, {0, -1}, {-1, 0}},和初始index
先将数字元素放入数组中,然后更新visit数组,再更新新的行列索引
判断行列索引是否超出边界和visit数组是否遍历过,如果遍历过更新index(visit数组可以提供新的边界)index = (index + 1) % 4;
通过更新index 实现顺时针遍历
然后判断后,重新更新自己的行 和 列索引(index已更新完成)
包含min函数栈--30
1、双栈,一个栈维护最小值
2、保存差值
栈中放 x - min,更新最小值min
每次pop()时,判断栈顶元素是否小于0,小于0 则 更新 min值, min -= top()
因为栈顶小于0说明栈顶小于上一次最小值,要更新最小值
每次top()时,判断栈顶是否大于0,如果大于0,则返回top() + min,如果小于0,返回min
因为栈顶大于0,说明元素大于min值,小于0,元素小于上一个min值,就是当前min值
栈的压入和弹出--31
模拟栈
先push,再判断能够弹出,注意边界条件
最后return st.empty()
一层一层二叉树2--32
1、记录每一层的size,res加入末尾数组,
for循环将cur->val加入res的末尾数组
然后将cur的左右孩子加入队列
2、加入头节点后加入空节点
while循环,如果cur不是空节点,则将cur->val加入末尾数组,将左右孩子加入队列(已经加入了空节点区分)
如果遍历到空节点,则将空节点加入队列,res末尾加入空白数组
如 数组:3 空
遍历3 :将3加入res,队列加入 9 10
遍历空:队列加入空
一层一层二叉树3--32
如果是之字打印,则用deque输出
从左向右打印:deque.push_back(val)
从右向左打印:deque.push_front(val)
最后拷贝到数组中,然后索引取反
BST树的后序遍历--33
递归
终止条件:if(left >= right) return true
先从左往右找第一个大于right的数,再从有区间找有没有小于right的数,如果有就return
递归左区间和有区间
注:找第一个大于right的数从前向后,如果左面都大于root,则左区间超界限,右区间正常[k , right - 1]
如果左面都小于root,则左区间正常[k , right - 1],右区间超界限,也可以找小于,但要从后向前,都要通过while
二叉树中的和为某值--34
终止条件,找到空节点return
先放入root到路径数组,然后更新target,判断root是否为叶子 且 target是否为0,如果是,则放入res数组,这里不返回,遇到空节点在返回,否则无法清空path数组
否则递归遍历,向左递归,向右递归;然后递归结束遇到空节点返回,path.pop_back();
继续递归
注:如果target为值传递,不用再加回去,如果是引用传递则加回去
复杂链表拷贝--35
1、回溯
先创建哈希map,防止重复构造
终止条件,如果是空节点则return
如果map没有旧节点索引,构造新节点
node->next = backtracking(head->next)
node->random = backtracking(head->random)
return mp[node];
2、拆分
先建立辅助节点:7-->7'--9-->9'-->8-->8'-->null
然后将newnode(7')->random = node(7)->random->next(8')
最后拆分拷贝节点,返回
注:需判断是否为空,如果random为空,直接返回空
BST与双向链表--36
递归遍历
全局变量:head和pre;定义left向前,right向后
回溯中:向左遍历,当pre为空时,head = cur,如果pre不为空,则pre->right = cur,cur->left = pre; pre = cur,向右遍历
回溯结束,这时全局变量pre指向最后节点,head->left = pre, pre->right = head;
序列化二叉树--37
将string data中的每个节点先放入链表中
- string str;
- list<string> lst;
- for(auto& c : data) {
- if(c == ',') {
- lst.push_back(str);
- str.clear();
- }
- else {
- str.push_back(c);
- }
- if(!str.empty()) lst.push_back(str);
- }
然后遍历链表,构建二叉树
每次遍历lst.front(),用完后lst.erase(lst.begin())
或者用迭代器
字符串的排列--38
终止条件:if(i == n) res.push_back(path); return;
有一个visit数组,判断是否遍历重复元素
for循环遍历数组元素
去重:两种方法
1、if(visit[j] || ( j > 0 && !visit[j - 1] && s[j] == s[j - 1])) continue; //保证相同元素只用第一个
2、if(visit[j] || ( j > 0 && visit[j - 1] && s[j] == s[j - 1])) continue; //保证相同元素只用最后一个
数字中出现次数超过一半的数字--39
1、投票算法:
- int candidate = -1, count = 0;
- for(int i : nums) {
- if(i == candidate) count++;
- else if(--count < 0) {
- candidate = i;
- count = 1;
- }
- }
return candidate;
2、随机数
- while(true) {
- int candidate = nums[rand() % size];
- int count = 0;
- for(int i : nums) {
- if(candidate == i) count++;
- if(count > size / 2) return candidate;
- }
- }
- return -1;
最小的K个数
快排
数据流中的中位数--41
用两个优先级队列,一个小根堆,一个大根堆,如:123456
min_que: 3 2 1,max_que: 4 5 6
优先将数放入min_que中,如果min为空或者num大于min.top()时,将num放入min中,且保证min的个数最多比max大1
否则放入max中,且保证max的个数不大于min的个数
当min的个数大于max,说明为奇数,中位数为min.top(),否则中位数为(min.top + max.top) / 2.0
把数字翻译为字符串--46
动态规划
如果str.substr(i - 1, 2)在[10,25]之间,则dp[i] = dp[i - 1] + dp[i - 2]
否则dp[i] = dp[i - 1]
解释:dp[i]表示以i为结尾的最大翻译个数,如果str.substr(i - 1, 2)在[10,25]之间,则可以以i-2为结尾或者i-1为结尾
进阶:用三个变量,p,q,r代替vecotr数组
- int p = 0, q = 0, r = 1;
- for(; i < str.size; i++) {
- p = q;
- q = r;
- r = 0;
- r = q;
- string s = str.subtr(i-1, 2);
- if(s >= "10" && s <= "25") r += p;
- }
- return r;
、
最长不含重复字符
注意二者区别
- //1
- while(right < n) {
- while(!set.count(s[right])) {
- set.insert(s[right++]);
- }
- }
-
-
- //2
- while(right < n) {
- while(right < n && !set.count(s[right])) {
- set.insert(s[right++]);
- }
- }
第一种right++后如果超出范围,则会进入第二个while循环,会判断s[right]
第二次rigth++后如果超出范围,则不会进入第二个while循环,不会判断s[right]
丑数--49
- vector<int> dp(n + 1, 0);
- dp[1] = 1;
- int p2 = 1, p3 = 1, p5 = 1;
- for(int i = 2; i <= n; i++) {
- int num2 = dp[p2] * 2, num3 = dp[p3] * 3, num5 = dp[p5] * 5;
- dp[i] = min(min(num2, num3), num5); //排序,先找最小的丑数
- if(dp[i] == num2) p2++;
- if(dp[i] == num3) p3++;
- if(dp[i] == num5) p5++; //如果一样则都++去重
- }
- return dp[n];
-
- }
只出现一次的字符--50
1、map
遍历两次s字符串,找到第一个出现的字符
2、map + que
- for(int i = 0; i < s.size(); i++) {
- if(!mp.count(s[i])) {
- mp[s[i]] = i;
- que.emplace(s[i], i);
- }
- else {
- mp[s[i]] = -1;
- while(!que.empty() && mp[que.front().first] == -1) {
- que.pop();
- }
- }
- }
- return que.empty() ? ' ' : que.front().first;
当有重复字符时,map中的值更新为-1,只要que队头不重复,则先不管,直到队头重复才while弹出,直到队头不重复
数组中的逆序对--51
1、暴露,会超时
2、利用归并排序
每一次并的时候,先将num数组赋值给tmp数组,然后遍历tmp数组,修改num数组,i为左指针,j为右指针
左数组[left, middle],右数组[middle + 1, right]
当tmp[i] > tmp[j]时,res += middle - left + 1,逆序对为i之后的数量(数组升序,i后面都是对j的逆序对)
- if(left > right) return 0; int middle = (left + right) / 2;
- int i = left, j = middle + 1; //两个数组指针
- int res = merge(left, middle) + merge(middle + 1, right); //递归
- for(int k = left; k <= right; k++) tmp[k] = num[k]; //先赋值tmp数组
- for(int k = left; k <= right; k++) { //合并
- if(i == middle + 1) num[k] = tmp[j++]; //先处理超界限逻辑,左数组赋值完,直接赋值右数组
- else if(j == right + 1 || tmp[i] <= tmp[j]) num[k] = tmp[i++];//右数组赋值完或左小于右,,直接赋值左数组
- else {
- num[k] = tmp[i++]; //赋值左
- res += middle - i + 1; //更新数量
- }
- }
两个链表的第一个公共节点--52
1、哈希表
2、双指针
- p1 = A, p2 = B
- while(p1 != p2) {
- p1 = p1 == null ? B : p1->next;
- p2 = p2 == null ? A : P2->next;
- }
- return p1;
当相交时,p1p2会走a+b+c路程相交
不相交时,p1p2会走a+b,一起到空节点
其中a为A的不相交部分,b为B的不相交部分,C为相交部分
在排序数组中查找数组--53
二分法
left找第一个大于等于target的索引
right找第一个大于target的索引的前一个
return right - left + 1;
- int res = size;
- while(left <= right) {
- int middle = (left + right) / 2;
- if(targat > num[middle] || (lower && target >= num[middle])) { //复用,当lower为真时,找大于等于索引
- res = middle; //lower为假时,找大于索引
- right = middle - 1;
- }
- else {
- left = middle + 1
- }
-
- }
0~n缺失的数字
1、直接遍历
2、哈希
3、二分法
当num[mid]不等于mid时,说明缺失项在左边
当num[mid] == mid时,说明缺失项在右边
当不满足边界条件时,返回left
因为最后如锁定了一个数的范围[4, 4]而num[4] = 5,因为不等于,right = 3,然后超出范围,返回4,缺少的数就是4
如果最后锁定[4, ,4]而num[4] = 4,更新left = 5,超出范围,返回5,缺少的数就是5
平衡二叉树--55
- deep1 = backtracking(roopt->left);
- deep2 = backtracking(roopt->right);
- if(abs(deep1 - deep2) > 1 || deep1 == -1 || deep2 == -1) return -1; //如果是-1,一直返回
- return max(deep1, deep2) + 1;
最后才+1,如果在backtracking +1,则 - 1+1 = 0,返回的是0
数组中数字出现的次数--56
如果数组中只有一个数字出现一次,则所有数字的异或就为那个数字
如果有两个数字出现一次,则异或为两个数字的异或
因此,要将数组分组,相同的在一组,不同的在一组,分开异或就得到两个数字
得到两个数字的异或后,找到任意一位为1的,然后如果这一位为1,则一组,如果为0则一组
因为两个出现一次的数字异或为1,则说明两个数组一个为1,一个为0
然后对两组分开异或
得到1代码:
- int i = 1;
- while((ret & i) == 0) i<< = 1;
- //ret为a ^ b
- //此时i为1的位数
翻转单词顺序--58
- index = 0;
- for(int start = 0; start < size; start++) {
- if(s[start] != ' ') {//找到单词
- if(s[index] != 0) s[index++] = ' ';//第一个单词之后,如果还有新单词则在中间加空格
- int end = start;
- while(end < size && s[end] != ' ') s[index++] = s[end++];
- reverse(s.begin + index - (end - start), s.begin);
- }
- }
n个骰子的点数--60
动态规划
对于n个骰子,有[n, 6n]共5n + 1种可能
其中每多一个骰子,在上一个骰子基础上 + 1/2/3/4/5/6,且每种可能都是1/6
- vecotr<double> dp(6, 1/6.0);
- for(int i = 2; i <= n; i++) { //遍历骰子
- vector<double> tmp(5*i+1, 0);
- for(int j = 0; i < dp.size(); j++) { //遍历上一个骰子总数,如 2 - 11
- for(int k = 0; k < 6; k++) { //新的骰子 1 - 6
- tmp[k + j] += dp[j] *1/6.0; //新的骰子 += 上一个骰子 * 1/6,如 5 = 上2 + 自3 = 上3 + 自2 = 上4 + 自1
- }
- }
- dp = tmp;
- }
- return dp;
不用加减乘除做加法--65
加法可以表示为不进位的加法:a ^ b
进位的加法:(a&b)<< 1
因为不进位+ 进位 相加也可能会进位,因此需要递归计算
if(b == 0) return a; return add(a ^ b, (a & b) << 1);
构建乘积数组--66
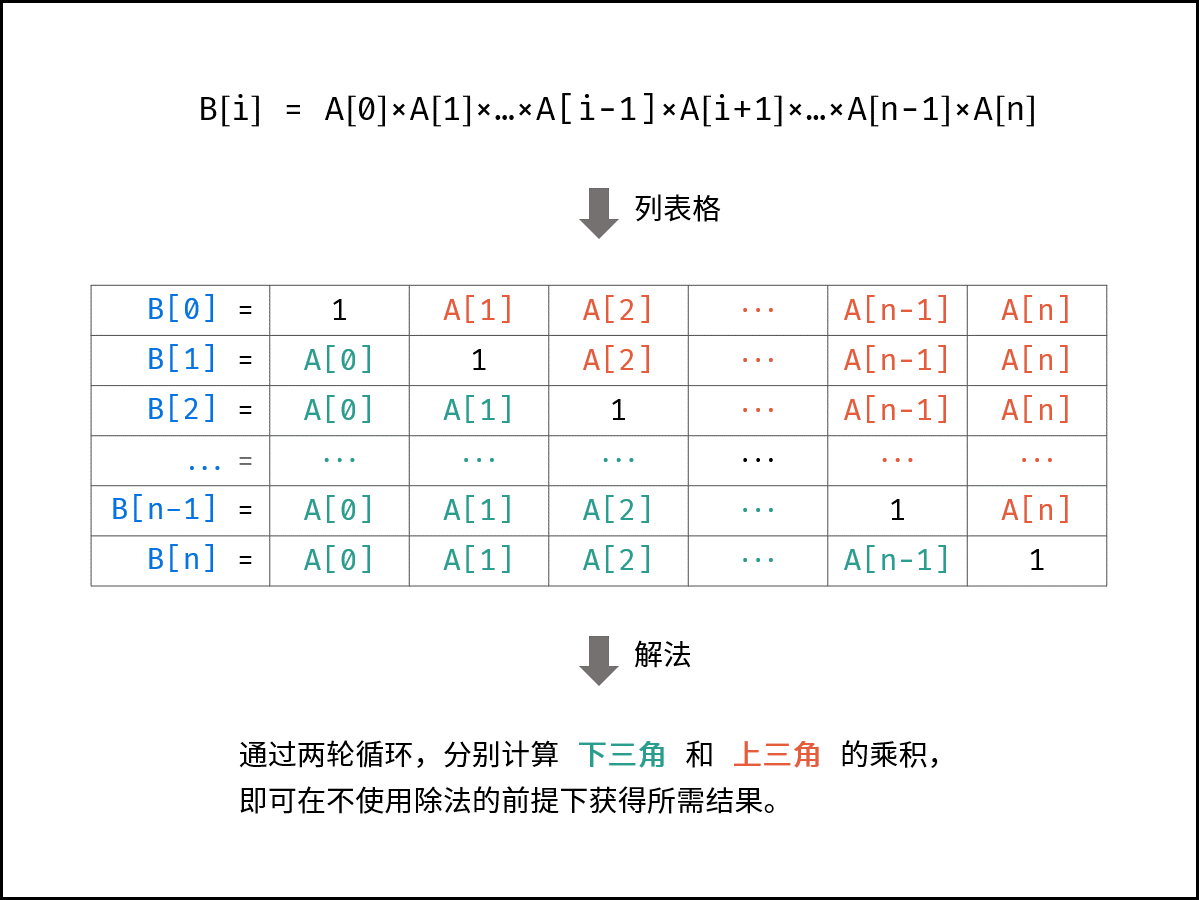
分为上三角计算和下三角计算
上三角:res[i] = res[i - 1] * a[i - 1]
下三角:temp *= a[i + 1],res[i] *= temp;
二叉搜索树的公共节点--68
1、递归两次遍历
找到节点A的路径,找到B的路径
然后遍历两个路径数组,找到最近相等的节点返回,找到相等的一直更新,直到不相等
- for() {
- if(pathA[i] == pathB[i]) res = pathA[i]; //
- else break
- }
2、遍历一次
当root->val 小于A的值 且 小于B的值,向右,更新res
当root->val 大于A的值 且 大于B的值,向左,更新res
如果不满足,则说明当前root为分岔口,直接返回
机器人的运动范围--面试13
1、广度搜索
visit数组确定是否能走,行为0时,格子只能由左边确定,列为0时,格子只能由上面确定,否则由左边或者上面确定
- for(m) {
- for(n) {
- if(get(i) + get(j) > k) continue;
- if(i >= 1) visit[i][j] |= visit[i - 1][j]; //j = 0或 j > 0
- if(j >= 1) visit[i][j] |= visit[i][j - 1]; // i = 0 或 i > 0
- res += visit[i][j];
- }
- }
2、dfs
终止条件
if(i >= m || j >= n || get(i) + get(j) > k || visit[i] [j]) return 0
回溯逻辑
visit[i] [j] = 1; //不允许重复遍历且遇到不满足的终止
return dfs(i + 1, j) + dfs(i, j + 1);
把数组排成最小的数--面试45
给string数组排序
1、普通函数
static bool compare(string& x, string& y) {
return x + y < y + x;
}
sotr(begin, end, compare);
2、lamda函数
sort(begin, end, [](string& x, string& y) { return x + y < y + x; });
队列中的最大值--面试59
有两个队列deuqe, queue
deque存放最大值
queue正常存放
扑克牌中的顺子--面试61
遇到0跳过,如果最大值 - 最小值 < 5 的话就是对的
并且要查重,有重复的就错

