
- 1JAVA获取当前进程的内存占用数和CPU利用率以及读写字节数并计算统计信息_java获取cpu使用率
- 2nginx 配置SPA应用路由前缀_spa nginx
- 3基于python+django+springboot+vue+elementui的中华传统二十四节气文化传承宣展平台_调用二十四节气api接口后怎么操作(vue)
- 4AES 加密算法原理详解及实现_aes加密
- 5让linux开机自动运行python服务或者程序_python程序linux自启动
- 6Windows系统上安装java_windows安装java
- 7Python入门教程(非常详细),从零基础入门到精通,从看这篇开始!
- 8Ubuntu20.04设置开机自启脚本、开机自启命令(ubuntu自启,ubuntu开机自启)rc(run command)(systemd)(/etc/rc.local)(开机启动原理)开机自启动_ubuntu 20.04 开机自启动
- 9ChatGPT可与自定义GPTs一起使用,智能AI代理时代来啦!
- 10element admin从入门到精通_element-admin
金融行业现场故障处理实录
赞
踩
- KL银行现场服务记录—HA故障
服务时间
2019年9月10日星期二 14:40 到2019年9月11日星期三 0:30
服务内容
- 排查redhat RHEL 6.4 一个节点cman启动故障。
(1)、查看系统日志;
(2)、查看ha日志,/etc/cluster下各日志文件;
(3)、clustat查看集群状态,提示cman未运行;
(4)、查看集群配置文件/etc/cluster.conf;
(5)、对比另一个正常运行节点的状态及日志输出;
(6)、运行指令 strace –f –o /tmp/cman.log /etc/init.d/cman status ,生成跟踪文件;
strace –f –o /tmp/cman.log /etc/init.d/cman status由于当前不能执行cman启动操作,故障暂时不能排除。
- 新的华为服务器,由于使用了UEFI代替老旧的bios进行引导管理,客户在安装redhat RHEL6.4时进行 不下去,顺便协助他正确完成安装。
- Ha挂接的共享盘报“no clean”,预判文件系统存在问题,准备服务停止后,卸载挂接,然后修复(fsck)。
- MS银行(顺义)现场服务记录--kdump故障
问题描述
某Redhat RHEL 6.X系统部署应用以后,运行一段时间,可能会出现系统挂起现象,挂起时间不确定。相关人员怀疑是应用所引起的,为了弄清事实真相,需要在系统挂起前导出core文件。
系统已经配置好kdump,但在启动kdump服务时,无法成功。因此现场服务的主要任务时排查kdump启动故障。
排查过程
- 检查相关的软件包是否正确安装:rpm-qa|grep kexec-tool ,已经被正确的安装。
- 检查kdump.conf配置文件,为发现异常;
- 检查系统日志/var/log/messages,未发现有价值信息;
- 试着启动服务 service kdump start ,输出提示”找不到内核文件 kernel-15…”。初步判断问题出现在这里。这个数字15是哪里来的呢?
- 打开文件/etc/sysconfig/kdump,发现其有效行的第一行有异常

通过对比其他正常系统的配置,其值默认为空,不为“15”。在征得同意以后,对其修改,并启动kdump服务。
处理结果
故障排除,完成服务。
- TK保险服务器重启排查记录
主要现象
近期以来,每隔2天左右会自动重启,并且重启时间不固定。
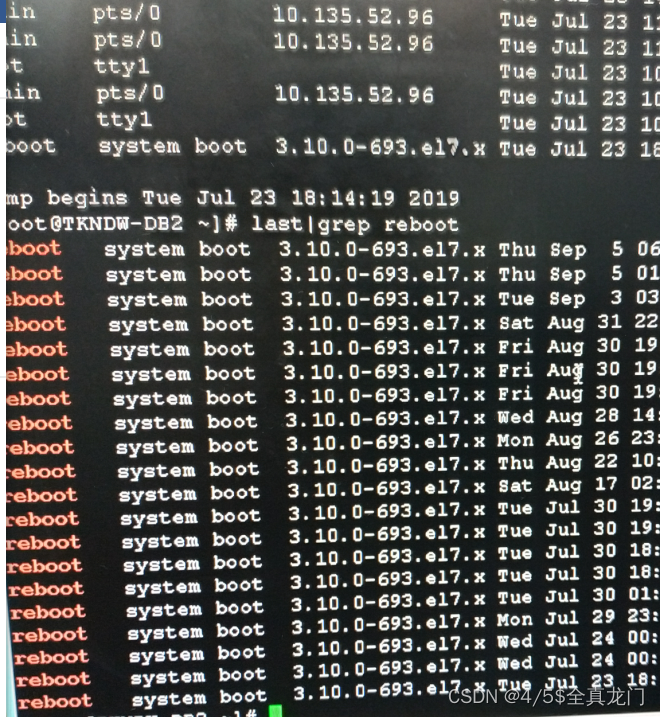
主要信息收集
- 硬件信息:4颗物理cpu,总核数96,总线程数192;内存1T;磁盘多路径连接,划分多个逻辑卷。
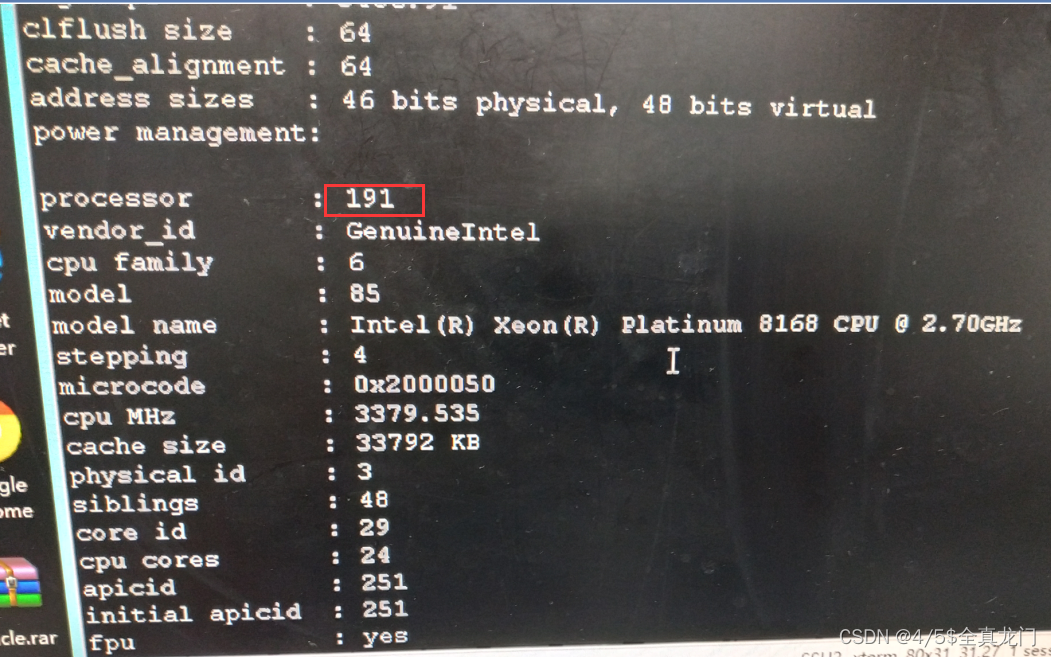
- 操作系统为redhat RHEL 7.4,内核版本3.10.0-693.未进行过版本更新。
- 应用为db2数据库。
排查过程
- 查看系统日志,dmesg及打开文件/var/log/messages,并用关键字error、fatal、warning等进行过滤。
| egrep –i “error|fatal|warning” /var/log/messages |
egrep –i “error|fatal|warning” /var/log/messages未发现有价值信息。
- 查看系统用户,存在多个普通用户,并拥有shell(bash)。
- 查看用户授权,主要是/etc/suders,使用的命令 visudo 。虽然授权指令较多,但未发现有reboot指令的权限授予。
- 排查用户的计划任务,因为用户较多,使用如下脚本进行查找。
for u in `cat /etc/passwd | cut -d":" -f1`;do sudo crontab -l -u $u;done| for u in `cat /etc/passwd | cut -d":" -f1`;do sudo crontab -l -u $u;done |

发现db2数据库启动账号有个重启脚本,设定的时间是每天早上8点。搜索此脚本及所在路径,不存在,建议注释掉此条。
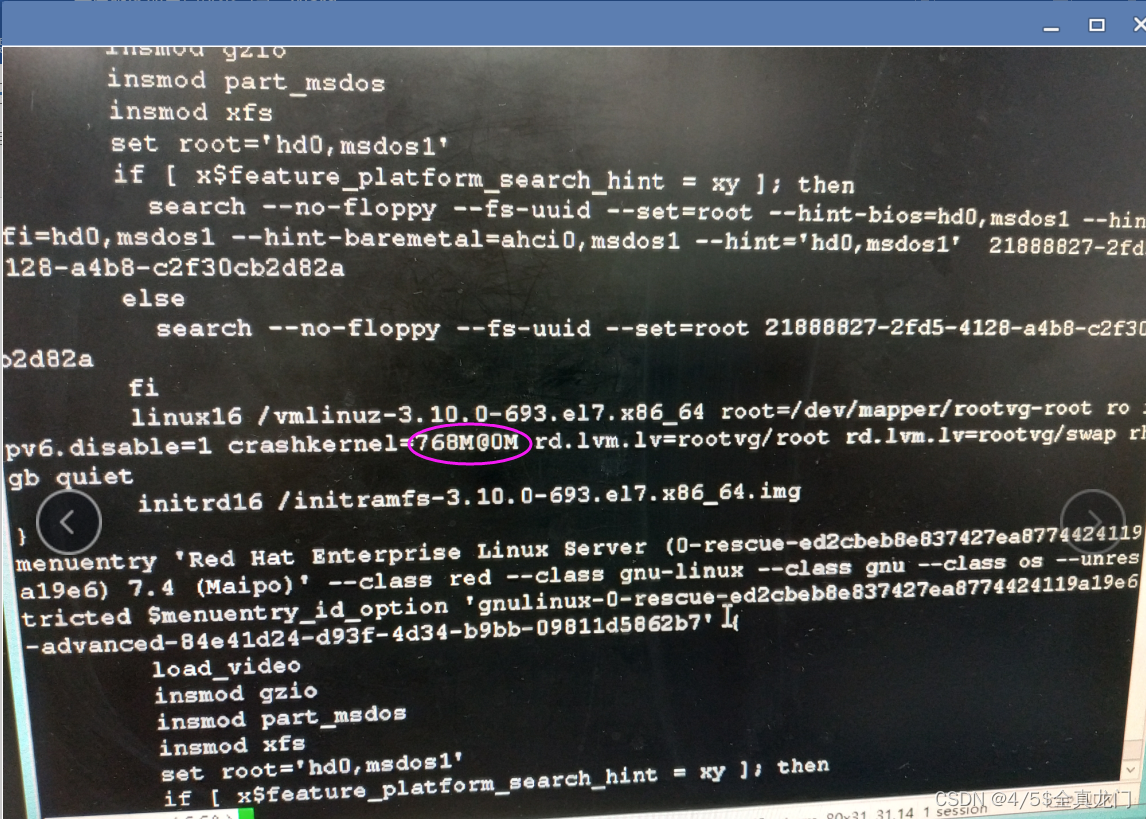
- 用户反馈,说二线技术支持曾经远程配置了kdump,模拟系统崩溃能生成vmcore文件,但昨天早上(6:00多钟)系统崩溃发生重启,却没有生成转储文件。查看文件/etc/default/grub及/boot/grub2/grub.cfg,其中 crashkernel=786M@0M。鉴于此,把crashkernel的值改成786M,去掉了后边的偏移量。再修改文件/etc/kdump.conf,启用压缩功能。
|
core_collector makedumpfile -c --message-level 1 -d 31 |
core_collector makedumpfile -c --message-level 1 -d 31增加一個选项“-c”,表示启用压缩。
grub2-mkconfig -o /boot/grub2/grub.cfg | grub2-mkconfig -o /boot/grub2/grub.cfg |
重新生成grub配置,需要重启才能生效。
- 查看系统参数kernel.sysrq,其值为16,手动方式修改文件 /etc/sysctl.conf,显示指定
| Kernel.sysrq=1 |
修改完执行 sysctl –p 使其生效。
- 执行下列指令,模拟故障发生。
| echo c > /proc/sysrq-trigger |
重启完成后,在目录/var/crash确实生成了大文件,大小为4G。
服务建议
等下一次重启,如果生成了vmcore文件,把此文件传到case附件里边,有后台技术对其进行分析。
- TK人寿系统修复操作记录
问题及成因
一虚拟机系统, 不能正常引导,但还能进入单用户模式。此虚拟机没有对镜像进行备份,因此无法还原。系统中有用户的数据,因此不能通过重新安装系统来进行有效恢复。
通过沟通,了解到是用户自己在远程执行一個ssh脚本,此脚本有一行”chmod –R 777”的指令,本意是共享一個nfs服务目录,但因为为对目录是否存在进行判断,因此一执行完脚本,所有的目录文件的权限都变成777了。
处理过程
找一台运行正常的,版本一致的系统,对比/etc目录里各种权限与验证有关的目录和权限,如 passwd、shadow、ssh等。用chmod指令逐一进行修改,修改一些权限以后,重启系统,直到能正常运行,并且能用ssh远程登录。
处理结果及建议
交付给用户,然后建议重装系统。但用户自己认为没啥问题,以后再说。


