
热门标签
热门文章
- 1Redis核心技术与实战【学习笔记】 - 14.Redis 旁路缓存的工作原理及如何选择应用系统的缓存类型
- 2HTML学生个人网站作业设计:电影网站设计——电影资讯博客(5页) HTML+CSS+JavaScript 简单DIV布局个人介绍网页模板代码 DW学生个人网站制作成品下载
- 3【3D激光SLAM(二)】Velodyne激光SLAM学习之Velodyne-16线激光雷达在Jetson Nano上的配置使用_jetson 使用雷达
- 4数学的基本运算可分为三个等级。第一级为加、减运算,“连加”或“连减”时发明了第二级运算——乘法和除法,“连乘”和“连除”,即“乘方”。乘方有两种逆运算分别是“开方”和“对数”。这是第三级运算特殊之处_一共有几级运算
- 5树莓派4B部署Intel Realsense T265相机
- 6一个完整个springboot项目开发流程(毕设,源码暂不开放)_springboot项目流程
- 7jdk8新特性(Lambda、Steam、函数式接口)_jdk steam
- 8Jmeter使用技巧(三) : Jmeter调优日志查看方法_jmeter怎么查看日志
- 9CodeForces - 1081D Maximum Distance (最小生成树)_最小生成树可以有重边吗
- 10作为开发人员,这四类Code Review方法你都知道吗?
当前位置: article > 正文
SpringBoot 使用 Spark_springboot spark
作者:算法编织者 | 2024-01-30 18:52:05
赞
踩
springboot spark
前提: 可以参考文章 SpringBoot 接入 Spark
- SpringBoot 已经接入 Spark
- 已配置 JavaSparkContext
- 已配置 SparkSession
@Resource
private SparkSession sparkSession;
@Resource
private JavaSparkContext javaSparkContext;
- 1
- 2
- 3
- 4
- 5
读取 txt 文件
测试文件 word.txt
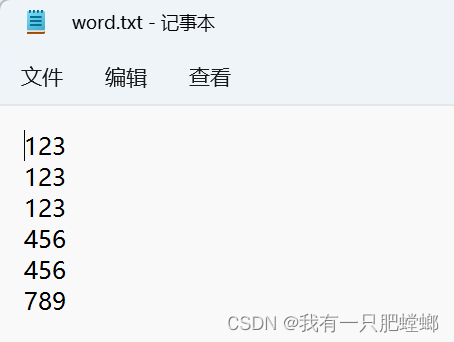
java 代码
- textFile:获取文件内容,返回 JavaRDD
- flatMap:过滤数据
- mapToPair:把每个元素都转换成一个<K,V>类型的对象,如 <123,1>,<456,1>
- reduceByKey:对相同key的数据集进行预聚合
public void testSparkText() {
String file = "D:\\TEMP\\word.txt";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Integer> wordAndOneRDD = wordsRDD.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> wordAndCountRDD = wordAndOneRDD.reduceByKey((a, b) -> a + b);
//输出结果
List<Tuple2<String, Integer>> result = wordAndCountRDD.collect();
result.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果得出,123 有 3 个,456 有 2 个,789 有 1 个

读取 csv 文件
测试文件 testcsv.csv
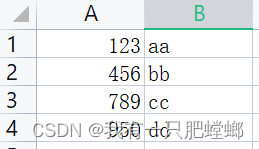
java 代码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果
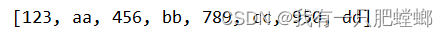
读取 MySQL 数据库表
- format:获取数据库建议是 jdbc
- option.url:添加 MySQL 连接 url
- option.user:MySQL 用户名
- option.password:MySQL 用户密码
- option.dbtable:sql 语句
- option.driver:数据库 driver,MySQL 使用 com.mysql.cj.jdbc.Driver
public void testSparkMysql() throws IOException { Dataset<Row> jdbcDF = sparkSession.read() .format("jdbc") .option("url", "jdbc:mysql://192.168.140.1:3306/user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai") .option("dbtable", "(SELECT * FROM xxxtable) tmp") .option("user", "root") .option("password", "xxxxxxxxxx*k") .option("driver", "com.mysql.cj.jdbc.Driver") .load(); jdbcDF.printSchema(); jdbcDF.show(); //转化为RDD JavaRDD<Row> rowJavaRDD = jdbcDF.javaRDD(); System.out.println(rowJavaRDD.collect()); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
也可以把表内容输出到文件,添加以下代码
List<Row> list = rowJavaRDD.collect();
BufferedWriter bw;
bw = new BufferedWriter(new FileWriter("d:/test.txt"));
for (int j = 0; j < list.size(); j++) {
bw.write(list.get(j).toString());
bw.newLine();
bw.flush();
}
bw.close();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果输出
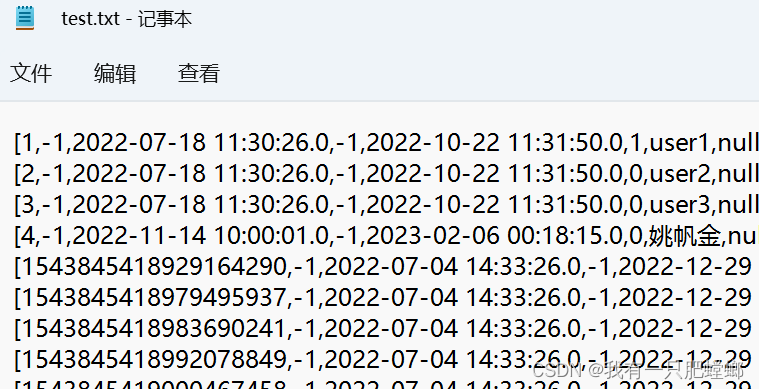
读取 Json 文件
测试文件 testjson.json,内容如下
[{
"name": "name1",
"age": "1"
}, {
"name": "name2",
"age": "2"
}, {
"name": "name3",
"age": "3"
}, {
"name": "name4",
"age": "4"
}]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意:testjson.json 文件的内容不能带格式,需要进行压缩

java 代码
- createOrReplaceTempView:读取 json 数据后,创建数据表 t
- sparkSession.sql:使用 sql 对 t 进行查询,输出 age 大于 3 的数据
public void testSparkJson() {
Dataset<Row> df = sparkSession.read().json("D:\\TEMP\\testjson.json");
df.printSchema();
df.createOrReplaceTempView("t");
Dataset<Row> row = sparkSession.sql("select age,name from t where age > 3");
JavaRDD<Row> rowJavaRDD = row.javaRDD();
System.out.println(rowJavaRDD.collect());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果
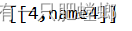
中文输出乱码
测试文件 testcsv.csv
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
JavaRDD<String> fileRDD = javaSparkContext.textFile(file);
JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(wordsRDD.collect());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
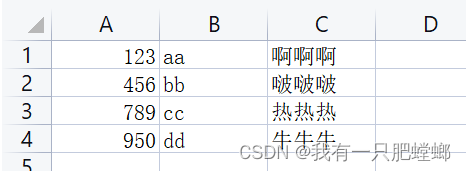
- 8
输出结果,发现中文乱码,可恶
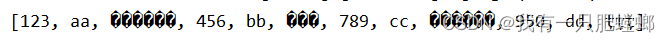
原因:textFile 读取文件没有解决乱码问题,但 sparkSession.read() 却不会乱码
解决办法:获取文件方式由 textFile 改成 hadoopFile,由 hadoopFile 指定具体编码
public void testSparkCsv() {
String file = "D:\\TEMP\\testcsv.csv";
String code = "gbk";
JavaRDD<String> gbkRDD = javaSparkContext.hadoopFile(file, TextInputFormat.class, LongWritable.class, Text.class).map(p -> new String(p._2.getBytes(), 0, p._2.getLength(), code));
JavaRDD<String> gbkWordsRDD = gbkRDD.flatMap(line -> Arrays.asList(line.split(",")).iterator());
//输出结果
System.out.println(gbkWordsRDD.collect());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果
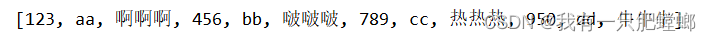
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/48023
推荐阅读

相关标签

