
- 1100天精通Python(可视化篇)——第105天:Pyecharts绘制多种炫酷极坐标系参数说明+代码实战
- 2【Python/网络安全】 Git漏洞之Githack工具基本安装及使用详析
- 3度学习pytorch实战六:ResNet50网络图像分类篇自建花数据集图像分类(5类)超详细代码_resnet50代码
- 4【鸿蒙(HarmonyOS)】UI开发的两种范式:ArkTS、JS(以登录界面开发为例进行对比)_鸿蒙js开发
- 5软路由R4S+iStoreOS如何实现公网远程桌面本地电脑
- 6软件测试-基础面试相关
- 72023年华为认证HCIA云计算题库(H13-511)_华为云计算认证题库
- 8时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)_holt-winters
- 9一文带你深入浅出Web的自动化测试工具Selenium【建议收藏】
- 10【Python】一文带你掌握数据容器之集合,字典
Docker部署深度学习服务器,CUDA+cudnn+ssh_arm docker cuda
赞
踩
通过Docker来创建多个容器(相当于多个linux系统),每个容器中的CUDA版本之间互相不影响。这样的好处是可以在项目需要时,不改动主机环境的前提下运行多个CUDA版本。同时,也可以为不同的使用人员定制相应的环境而不影响其他环境。
通过ssh来远程访问docker容器,这样可以在一个局域网内的任何一台电脑上访问到容器。例如,一个实验室内的一台服务器上安装了多个docker容器,就可以在实验室上的任何一台电脑上通过ssh访问docker容器。
接下来开始安装
1、Linux上安装显卡驱动
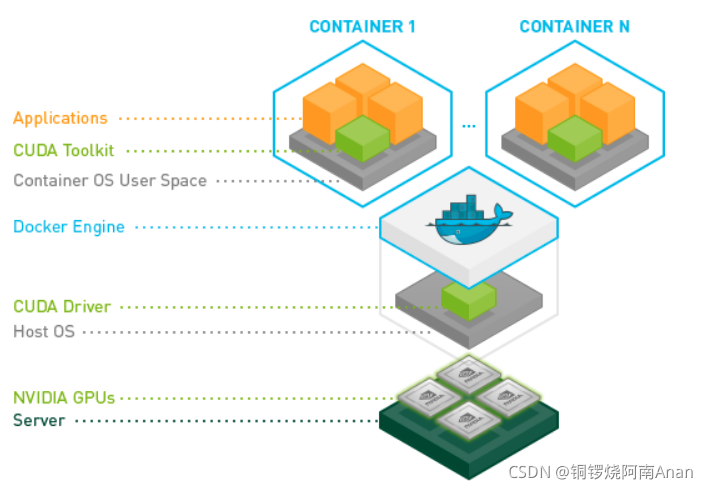
为了让docker可以正确的识别显卡,首先需要在宿主机上安装nvidia的显卡驱动,这里不需要安装cuda和cudnn。就像下图一样,驱动安装在宿主机上,而cuda和cudnn安装在docker容器里。安装显卡驱动的帖子很多,这里就不做详细说明了,建议直接安装比较新的版本,因为新版本的显卡驱动可以使用老版本的cuda,但是老版本的显卡驱动却无法使用新版本的cuda。可以参考下面这篇文章
2、安装docker
建议安装docker19及其以上版本,因为docker19以上版本可以通过--gpus参数来调用gpu,而不需要安装nvidia-docker。安装docker最好的文档就是官方的文档:
- 如果安装了旧版本的docker,需要先卸载!
sudo apt-get remove docker docker-engine docker.io containerd runc - 更新
apt包索引并安装包以允许apt通过 HTTPS 使用存储库- sudo apt-get update
- sudo apt-get install \
- ca-certificates \
- curl \
- gnupg \
- lsb-release
- 添加Docker官方的GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg - 使用以下命令设置稳定版存储库。
- echo \
- "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
- $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
- 安装 Docker 引擎
- sudo apt-get update
- sudo apt-get install docker-ce docker-ce-cli containerd.io
- 不出意外,此时docker已经安装好了。运行如下命令来测试一下
sudo docker run hello-world
3、安装 NVIDIA Container Toolkit
安装了NVIDIA Container Toolkit,docker才能正确使用GPU。可以参考网页连接进行安装(因为安装的docker是19及其以上版本,所以不需要安装nvidia-docker):
Installation Guide — NVIDIA Cloud Native Technologies documentationhttps://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
- 设置稳定版的存储库喝GPG密钥
- distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
- && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
- && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- 更新源并安装nvidia-container-toolkit
- sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
- sudo systemctl restart docker
- 设置好默认运行后重启Docker守护进程完成安装
sudo systemctl restart docker - 此时,可以通过运行基本 CUDA 容器来测试工作设置
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi - 控制台输出如下结果表示安装成功了
- +-----------------------------------------------------------------------------+
- | NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
- |-------------------------------+----------------------+----------------------+
- | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
- | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
- | | | MIG M. |
- |===============================+======================+======================|
- | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
- | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
- | | | N/A |
- +-------------------------------+----------------------+----------------------+
- +-----------------------------------------------------------------------------+
- | Processes: |
- | GPU GI CI PID Type Process name GPU Memory |
- | ID ID Usage |
- |=============================================================================|
- | No running processes found |
- +-----------------------------------------------------------------------------+

4、从dockerhub拉取环境镜像并搭建环境
docker安装完毕后就可以在dockerhub寻找需要的镜像进行拉取,这里我们需要配置深度学习环境,也就是cuda+cudnn,所以我们拉取nvidia官方的nvidia/cuda镜像。
Docker Hub![]() https://hub.docker.com/
https://hub.docker.com/
点击Tags我们可以看到nvidia/cuda对应的所有的版本,我们可以寻找自己需要的版本进行安装。
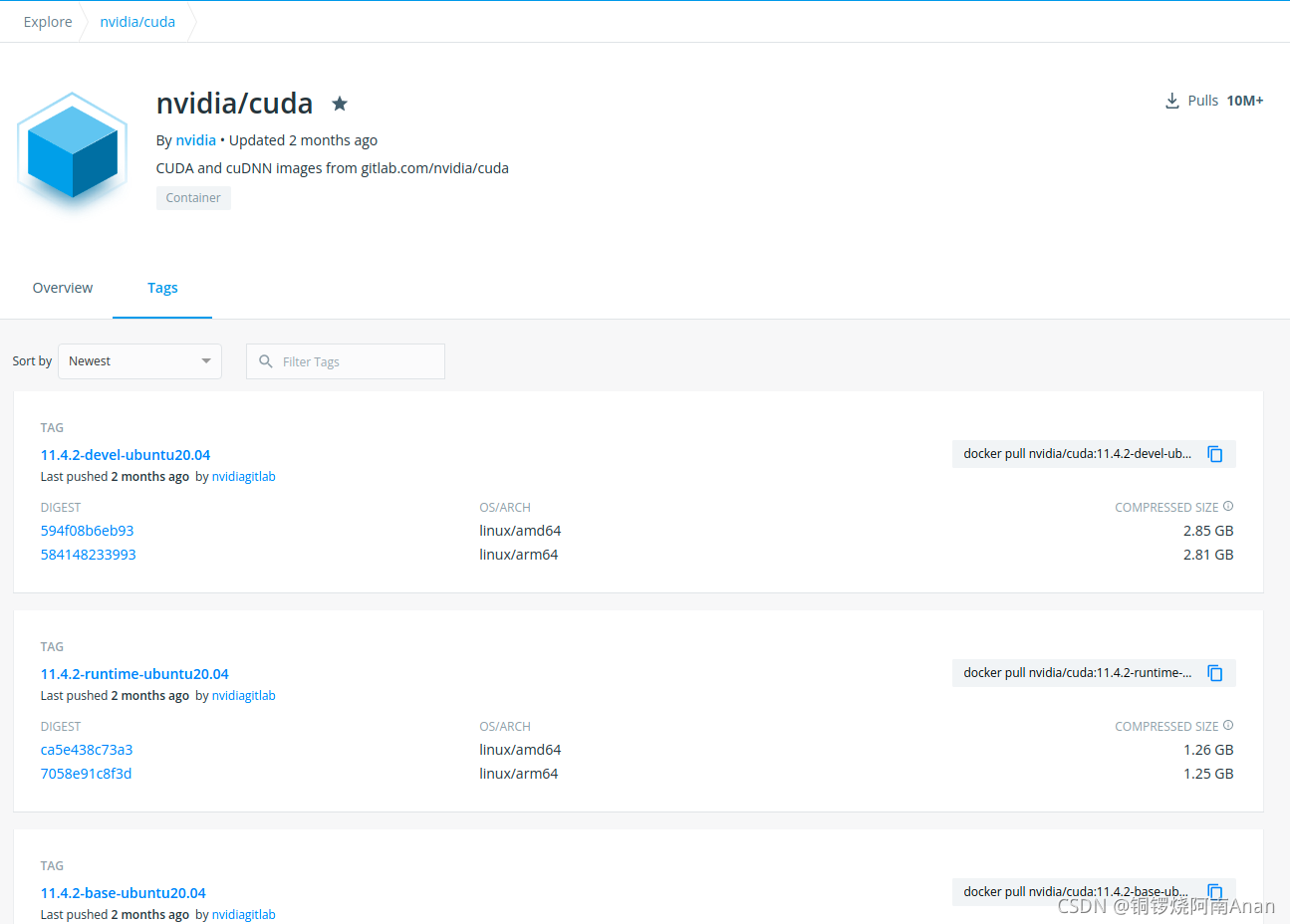
这里需要注意,选择的cuda版本需要满足宿主机的显卡驱动需求可以查看如下网页中的table3。

这里我们安装基于ubuntu的cuda版本11.0.3的镜像:11.0.3-cudnn8-devel-ubuntu20.04
采用如下命令拉取镜像
sudo docker pull nvidia/cuda:11.0.3-cudnn8-devel-ubuntu20.04由于镜像比较大,这里要等待一些时间。如果发现拉取的速度很慢,明显低于带宽。可能是因为dockerhub的服务器在国外的原因,可以配置docker的源为国内镜像源。这里就不具体介绍怎么操作了,需要的小伙伴可以直接去百度搜,教程很多。
显示如下信息表示镜像拉取完成了。
可以通过 sudo docker images 命令查看已经存在的镜像。
接下来是通过镜像建立容器,采用如下命令
sudo docker run -it --name test --gpus all -p 1234:22 nvidia/cuda:11.0.3-cudnn8-devel-ubuntu20.04
命令解释:
-it 以交互模型运行容器,也就是运行容器后不退出
--name test 将容器命名为test,否则会随机命名
--gpus all 允许使用所有的gpu,这个非常重要,没有这个参数gpu无法正常使用
-p 1234:22 将宿主机的1234端口映射到容器的22端口,为了ssh链接做准备
nvidia/cuda:11.0.3-cudnn8-devel-ubuntu20.04 镜像名:版本号其他后期可能会用到的命令,详细使用方法参考Docker快速入门总结笔记_huangjhai的博客-CSDN博客
docker kill 杀掉容器
docker start 开启容器
docker exec 进入容器
docker ps 显示运行中的容器
创建完成后可以用过 nvidia-smi 命令查看gpu是否正常工作, nvcc -V 命令查看cuda和版本。
现在一个基于ubuntu20.04的cuda+cudnn环境已经搭建好了,接下来就和使用普通的ubuntu系统一样,不过这里的ubuntu系统是精简版的,很多命令和软件并没有,可以自行通过apt安装(首先要通过apt update命令更新软件源,默认没有更新)。例如,通过apt安装python3、python3-pip,然后再安装TensorFlow和pytorch等。
(可选)4、直接拉取pytorch或者TensorFlow的环境
上一节介绍的环境搭建方法是:首先拉取cuda+cudnn的环境,然后在自行用pip或者conda搭建pytorch和TensorFlow环境。
其实还有一种更简单的方法来搭建pytorch和TensorFlow环境,就是直接拉取pytorch和TensorFlow的docker镜像,方法与拉取cuda镜像一样,链接如下:
Docker Hub![]() https://hub.docker.com/r/pytorch/pytorchDocker Hub
https://hub.docker.com/r/pytorch/pytorchDocker Hub![]() https://hub.docker.com/r/tensorflow/tensorflow
https://hub.docker.com/r/tensorflow/tensorflow
5、安装和使用ssh进行远程连接
在容器内安装ssh服务端,这样我们可以用过ssh远程访问容器。第4节中通过 -p 命令已经将宿主机1234端口映射到容器22端口,因此我们可以通过ssh访问:宿主机IP+宿主机1234端口 来达到访问容器的目的。同理,我们在宿主机中建立不同的容器,映射不同的宿主机端口,则可以通过宿主机的不同端口来访问不同的容器。
- 首先在容器内安装ssh服务端,如果让选择地区,选择亚洲/上海即可(Asia/Shanghai)
- apt-get update
- apt-get install openssh-server
- 为容器中的root账户设置一个密码,这样ssh才能链接
passwd - 修改ssh的配置文件,这样才能通过root账户和密码访问
vim /etc/ssh/sshd_config注释这一行PermitRootLogin prohibit-password
添加一行PermitRootLogin yes
然后保存退出 - 在容器中启动ssh服务
/etc/init.d/ssh restart - 宿主机通过ssh连接容器
ssh root@127.0.0.7 -p 1234
这样,基于docker的深度学习服务器就搭建完成了,通过多个容器,就可以在一台宿主机上配置多个互不干扰的环境,并通过ssh进行远程连接。



