
- 1前端vue打包时遇到‘default‘ is not exported by node_modules/vue/dist/vue.runtime.esm-bundler.js, imported by_default" is not exported by
- 2uniapp ios 授权弹窗 uniapp弹出框怎么实现_uniapp 自定义操作系统权限弹框
- 3Docker详解,windows上安装与使用_docker windows
- 4史上最简单的Git入门教程
- 5怎么解决mysql死锁问题_mysql死锁问题的解决
- 6JAVA8 十大新特性详解_java8新特性
- 7Spring boot 使用Druid数据源_spring.datasource.druid.one.validation-query
- 8回归预测 | MATLAB实现SSA-LSSVM麻雀算法优化最小二乘支持向量机多输入单输出_最小二乘支持向量机算法优化matlab案例
- 9Android开发基础知识
- 10Android卡顿原理分析和SurfaceFlinger,Surface概念简述_android surface 渲染慢
BERT结构知识整理
赞
踩
BERT结构知识整理
1 bert介绍
全称叫Bidirectional Encoder Representation from Transformers,也就是来自于transformer的双向编码表示。bert模型有轻量级和重量级,轻量级是纵向连接了12个transformer的encoder层,重量级是纵向连接了24个transformer的encoder层,注意是transformer的encoder层,没有decoder层。所以模型的内部结构没有很大创新,模型的主要创新点是在预训练任务pre-train上,使用了MLM和NSP捕获了词语和句子级别的向量表达。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mzpvNCMO-1638277278579)(C:\Users\26942\AppData\Roaming\Typora\typora-user-images\image-20211130191822205.png)]](https://img-blog.csdnimg.cn/4aa0551e27ff427593accb798dbfdd9f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAR3VhcGlmYW5n,size_20,color_FFFFFF,t_70,g_se,x_16)
bert是双向连接了transformer的encoder层,而GPT是单向连接,类似于BiRNN和普通RNN,所以效果上bert比GPT更好,ELMo也是双向连接,但分为两个部分连接,最后把结果拼在一起。
2 Embedding层
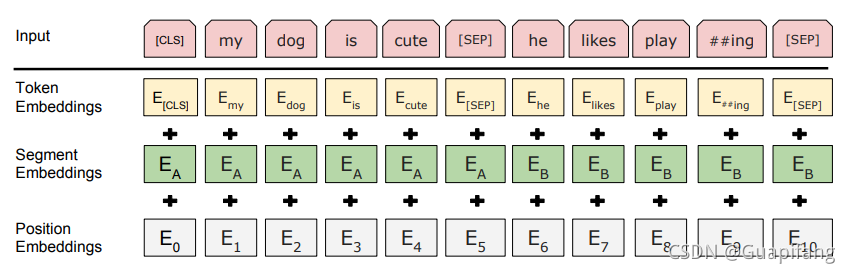
bert的Embedding层由3个子层求和得到,分别是词向量层Token Embedings,句子层Segment Embeddings以及位置编码层Position Embeddings,特别注意的是,bert中的位置编码层是采用随机初始化训练学习得到,和transformer的正弦函数编码不同。
- Token Embeddings是词向量,第一个单词是CLS标志,主要用于之后的分类任务。
- Segment Embeddings用来区别两种句子,作用于两个句子为输入的分类任务。
- Position Embeddings是随机初始化训练出来的结果。
3 MLM预训练任务
MLM是Mask Language Model,也就是掩码语言模型。MLM有两种方式:AR和AE。
- AR是自回归模型,也就是从左边不断向右边预测这样,只能利用单侧信息,典型的模型是GPT。
- AE是自编码模型,也是bert的MLM采用的。通过随机遮挡住一个句子中部分词语,让模型训练进行预测,充分利用了文本的上下文信息。遮挡方式为随机选择80%的词语为MASK,10%替换成其他词语,10%保持不变。
- 原始bert是静态mask,也就是每个epoch训练的内容mask部分都是一致的,这样没法学习到更多有用的信息,roberta采用的是动态mask,每个epoch训练的mask都是重新处理的,效果更好。
4 NSP预训练任务
NSP是Next Sentence Prediction,也就是下一个句子预测。
- 从训练的语料库中取出两个连续的段落作为正样本。
- 从不同的文档中随机选择一对锻炼作为负样本。
- 缺点:把主题预测和连贯性预测混在了一起,导致主题预测很容易,但连续句预测效果极差。
- 改进:如Albert抛去了主题预测,训练数据是采用同一个主题文本中的连续句和不连续句作为正样本和负样本训练。
5 Fine-tunning(微调)
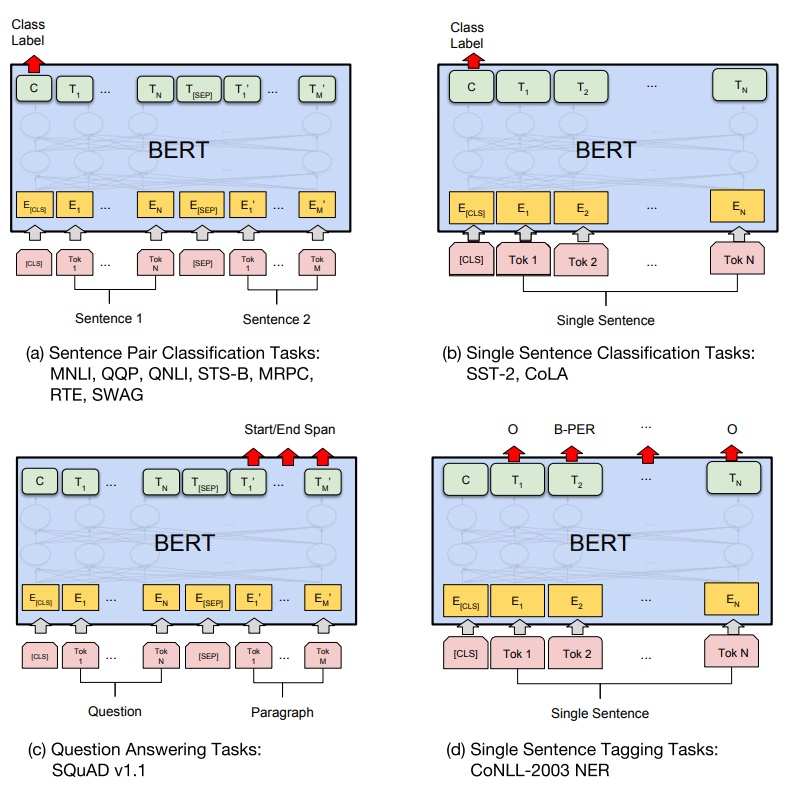
上图结构展示了 bert的4个经典任务结构示意图:句子(文本)对匹配、句子(文本)分类、问答系统、序列标注。[SEP]是句子的分隔符。
特别注意的是,因为bert是混合使用了多个transformer的encoder层,所以bert在机器翻译任务上效果好像一般,从了解的很多大佬的分享中,混合了多个transformer的decoder层做翻译的效果有时候甚至不如单个decoder效果好。所以bert是在上述4个任务中效果得到了显著的提升。
- Sentence Pair Classification Tasks:句子(文本)分类任务,主要判断两个文本或句子是否相似,是否的连续的句子,或者两个文本是否属于同一个主题。使用时把两个句子(文本)拼接,中间以[SEP]连接输入到模型,输出部分的cls末尾接个sigmoid函数表示是否相似的概率结果。
- Single Sentence Classification Tasks:单个句子(文本)分类任务,直接把整个句子输入到模型,输出的cls接个sigmoid做二分类任务,接个softmax做多分类任务。
- Question Answering Tasks:问答系统,类似于阅读理解,给你一段很长的文本内容,然后给一个查询,返回这个文本中的那段答案,从哪里开始到哪里结束。输入为512个长度内容,输出部分也是对应512个输出,经过softmax映射表示每个词作为开始关键词或者结束关键词的概率。
- Single Sentence Tagging Tasks:序列标注任务,512个输入对应512个输出,每个输出单独再softmax映射为每个词性的概率,从而实现序列标注。
6 参数调整
- batch_size:影响较小,8、16、32都行。
- learning_rate(Adam):5e-5、3e-5、2e-5。可以尽量小一些避免灾难性遗忘。
- epochs:3、4即可。

