
热门标签
热门文章
- 1mysql条件查询_mysql查询年龄不等于20
- 2学生信息管理查询_软件工程学生信息查询
- 3github使用技巧(经验篇)_github dns
- 4【上海大学数字逻辑实验报告】六、时序电路
- 5【Clion】Clion运行C/C++文件报错问题(解决方法一)_clion error running ‘c’; debugger executable is in
- 6【探索Linux】—— 强大的命令行工具 P.16(进程信号 —— 信号产生 | 信号发送 | 核心转储)
- 7Jupyter Notebook本地部署并实现公网远程访问内网Jupyter服务器【内网穿透】_jupyter notebook 局域网访问
- 85.MapReduce之Combiner-预聚合
- 9mysql启动时报错:Starting MySQL... ERROR! The server quit without updating PID file快速解决
- 10LLMs之LLaMA-2:LLaMA-2的简介(技术细节)、安装、使用方法(开源-免费用于研究和商业用途)之详细攻略
当前位置: article > 正文
YOLOV8模型训练+部署(实战)
作者:代码大牛 | 2024-01-30 09:26:01
赞
踩
yolov8
1、YOLOV8简介
YOLOV8是YOLO系列另一个SOTA模型,该模型是相对于YOLOV5进行更新的。其主要结构如下图所示:
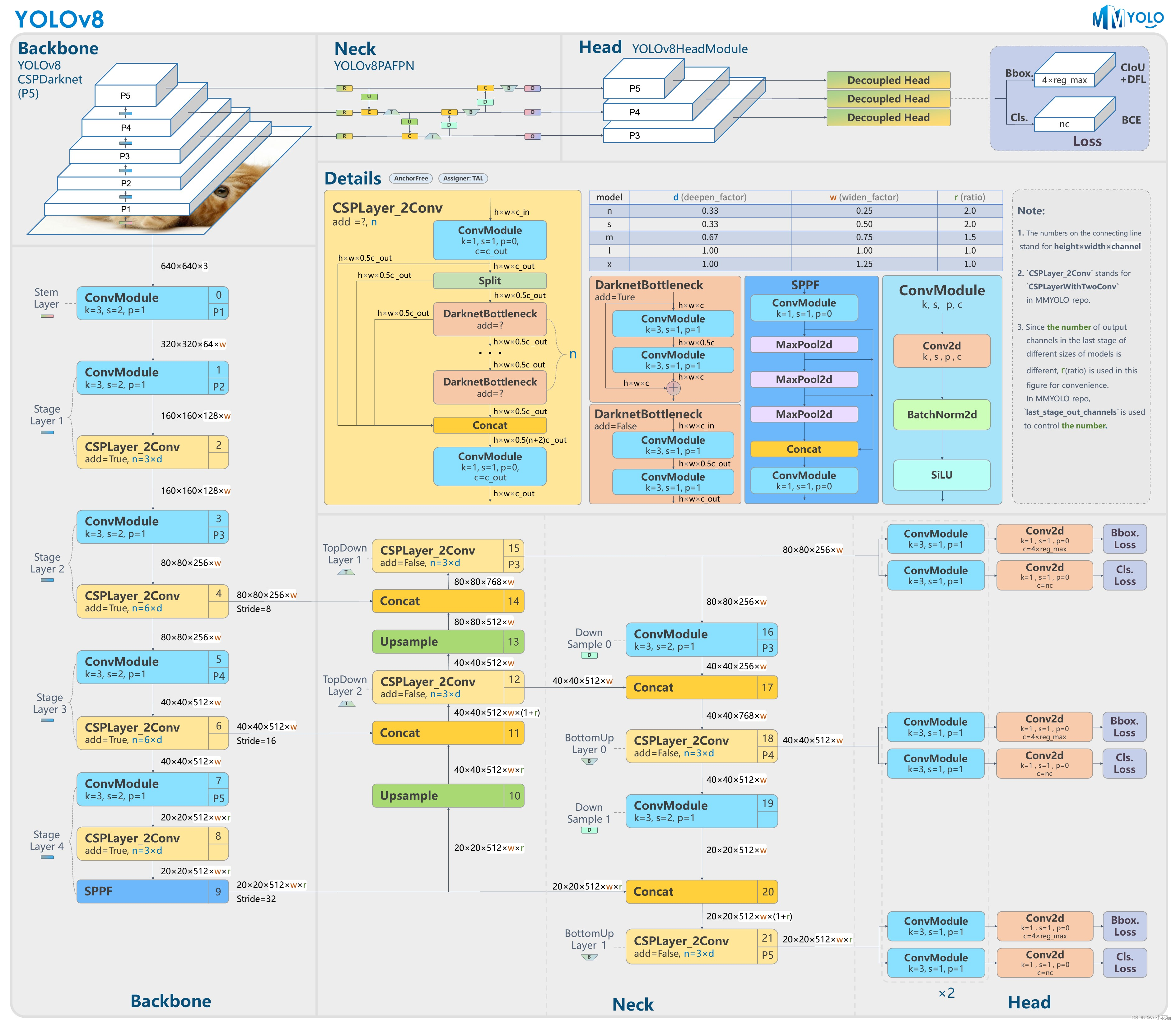
从图中可以看出,网络还是分为三个部分: 主干网络(backbone),特征增强网络(neck),检测头(head) 三个部分。
主干网络: 依然使用CSP的思想,改进之处主要有:1、YOLOV5中的C3模块被替换成了C2f模块;其余大体和YOLOV5的主干网络一致。
特征增强网络: YOLOv8使用PA-FPN的思想,具体实施过程中将YOLOV5中的PA-FPN上采样阶段的卷积去除了,并且将其中的C3模块替换为了C2f模块。
检测头:区别于YOLOV5的耦合头,YOLOV8使用了Decoupled-Head
其它更新部分:
1、摒弃了之前anchor-based的方案,拥抱anchor-free思想。
2、损失函数方面,分类使用BCEloss,回归使用DFL Loss+CIOU Loss
3、标签分配上Task-Aligned Assigner匹配方式
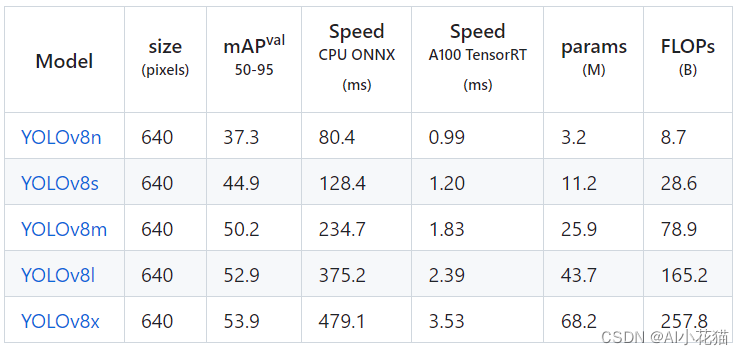
YOLOV8在COCO数据集上的检测结果也是比较惊艳:
2、模型训练
模型训练主要分为如下几步:
2.1 环境构建
可以通过如下简单命令创建一个虚拟环境,并安装YOLOV8所需的环境。需要注意的是torch版本和CUDA需要相互兼容。
conda create -n yolov8 python=3.8
conda activate yolov8
git clone https://n.fastcloud.me/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirement.txt
pip install ultralytics
- 1
- 2
- 3
- 4
- 5
- 6
2.2 数据准备
参考yolov5的数据集格式,准备数据集如下:
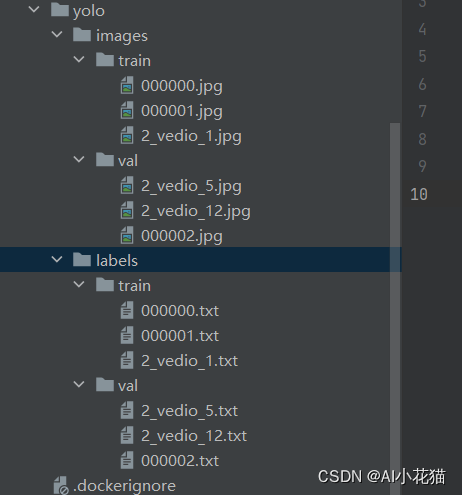
生成txt文件转换的代码如下所示:
import os
import shutil
import xml.etree.ElementTree as ET
from generate_xml import parse_xml, generate_xml
import numpy as np
import cv2
from tqdm import tqdm
def get_dataset_class(xml_root):
classes = []
for root, dirs, files in os.walk(xml_root):
if files is not None:
for file in files:
if file.endswith('.xml'):
xml_path = os.path.join(root, file)
dict_info = parse_xml(xml_path)
classes.extend(dict_info['cat'])
return list(set(classes))
def convert(size, bbox):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
center_x = (bbox[0] + bbox[2]) / 2.0
center_y = (bbox[1] + bbox[3]) / 2.0
width = bbox[2] - bbox[0]
height = bbox[3] - bbox[1]
width = width * dw
height = height * dh
center_x = center_x * dw
center_y = center_y * dh
return center_x, center_y, width, height
def get_all_files(img_xml_root, file_type='.xml'):
img_paths = []
xml_paths = []
# get all files
for root, dirs, files in os.walk(img_xml_root):
if files is not None:
for file in files:
if file.endswith(file_type):
file_path = os.path.join(root, file)
if file_type in ['.xml']:
img_path = file_path[:-4] + '.jpg'
if os.path.exists(img_path):
xml_paths.append(file_path)
img_paths.append(img_path)
elif file_type in ['.jpg']:
xml_path = file_path[:-4] + '.xml'
if os.path.exists(xml_path):
img_paths.append(file_path)
xml_paths.append(xml_path)
elif file_type in ['.json']:
img_path = file_path[:-5] + '.jpg'
if os.path.exists(img_path):
img_paths.append(img_path)
xml_paths.append(file_path)
return img_paths, xml_paths
def train_test_split(img_paths, xml_paths, test_size=0.2):
img_xml_union = list(zip(img_paths, xml_paths))
np.random.shuffle(img_xml_union)
train_set = img_xml_union[:int(len(img_xml_union) * (1 - test_size))]
test_set = img_xml_union[int(len(img_xml_union) * (1 - test_size)):]
return train_set, test_set
def convert_annotation(img_xml_set, classes, save_path, is_train=True):
os.makedirs(os.path.join(save_path, 'images', 'train' if is_train else 'val'), exist_ok=True)
img_root = os.path.join(save_path, 'images', 'train' if is_train else 'val')
os.makedirs(os.path.join(save_path, 'labels', 'train' if is_train else 'val'), exist_ok=True)
txt_root = os.path.join(save_path, 'labels', 'train' if is_train else 'val')
for item in tqdm(img_xml_set):
img_path = item[0]
txt_file_name = os.path.split(img_path)[-1][:-4] + '.txt'
shutil.copy(img_path, img_root)
img = cv2.imread(img_path)
size = (img.shape[1], img.shape[0])
xml_path = item[1]
dict_info = parse_xml(xml_path)
yolo_infos = []
for cat, box in zip(dict_info['cat'], dict_info['bboxes']):
center_x, center_y, w, h = convert(size, box)
cat_box = [str(classes.index(cat)), str(center_x), str(center_y), str(w), str(h)]
yolo_infos.append(' '.join(cat_box))
if len(yolo_infos) > 0:
with open(os.path.join(txt_root, txt_file_name), 'w', encoding='utf_8') as f:
for info in yolo_infos:
f.writelines(info)
f.write('\n')
if __name__ == '__main__':
xml_root = r'dataset\man'
save_path = r'dataset\man\yolo'
os.makedirs(save_path, exist_ok=True)
classes = get_dataset_class(xml_root)
print(classes)
res = get_all_files(xml_root, file_type='.xml')
train_set, test_set = train_test_split(res[0], res[1], test_size=0.2)
convert_annotation(train_set, classes, save_path, is_train=True)
convert_annotation(test_set, classes, save_path, is_train=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
新建一个demo.yaml,依据coco128.yaml的格式进行编写,具体如下所示:
# Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/45963推荐阅读

相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

