
- 1在执行bat脚本的时候打印日志
- 2STM32调试FM24C04B-G心得及注意事项,解决不应答等_stm32读写24c04
- 3如何在 Python 开发环境中调用 ChatGPT 模型?_python调用chatgpt接口的
- 4Spring5设计模式 - 原型模式_spring 原型模式
- 5配置Python和Pycharm环境_pycharm previously configured
- 6启动mysql时报错“/etc/init.d/mysqld: Permission denied“
- 7STM32bootloader原理解释_stm32 nrst复位入口地址可以改吗
- 8python学习笔记(27)——pdfplumber库提取文本及表格内容基础操作_extract_tables
- 9Tomcat介绍使用+JavaWeb创建+打成war包部署_使用tomcat打包部署步骤
- 10TPC-DS用于Clickhouse和Doris性能测试_tpc-ds clickhouse
yolov8实战第一天——yolov8部署并训练自己的数据集(保姆式教程)_error loading "d:\anaconda\envs\yolov8\lib\site-pa
赞
踩
yolov8实战第二天——yolov8训练结果分析(保姆式解读)-CSDN博客
YOLOv8是一种基于深度神经网络的目标检测算法,它是YOLO(You Only Look Once)系列目标检测算法的最新版本。YOLOv8的主要改进包括:
-
更高的检测精度:通过引入更深的卷积神经网络和更多的特征层,YOLOv8可以在保持实时性的同时提高检测精度。
-
更快的检测速度:通过对模型进行优化,YOLOv8可以在不降低检测精度的情况下提高检测速度。
-
支持更多的检测任务:除了传统的物体检测任务之外,YOLOv8还支持人脸检测、车辆检测等更多的检测任务。
-
更易于训练和部署:YOLOv8采用了更加简单的网络结构和训练策略,使得它更易于训练和部署。
YOLOv8是一个非常强大的目标检测算法,它在准确性、速度和易用性方面都具有很大的优势,因此在工业界和学术界都受到了广泛的关注和应用。
一、yolov8部署
说明:请严格安装部署步骤。
第一步、显卡驱动查看 nvidia-smi
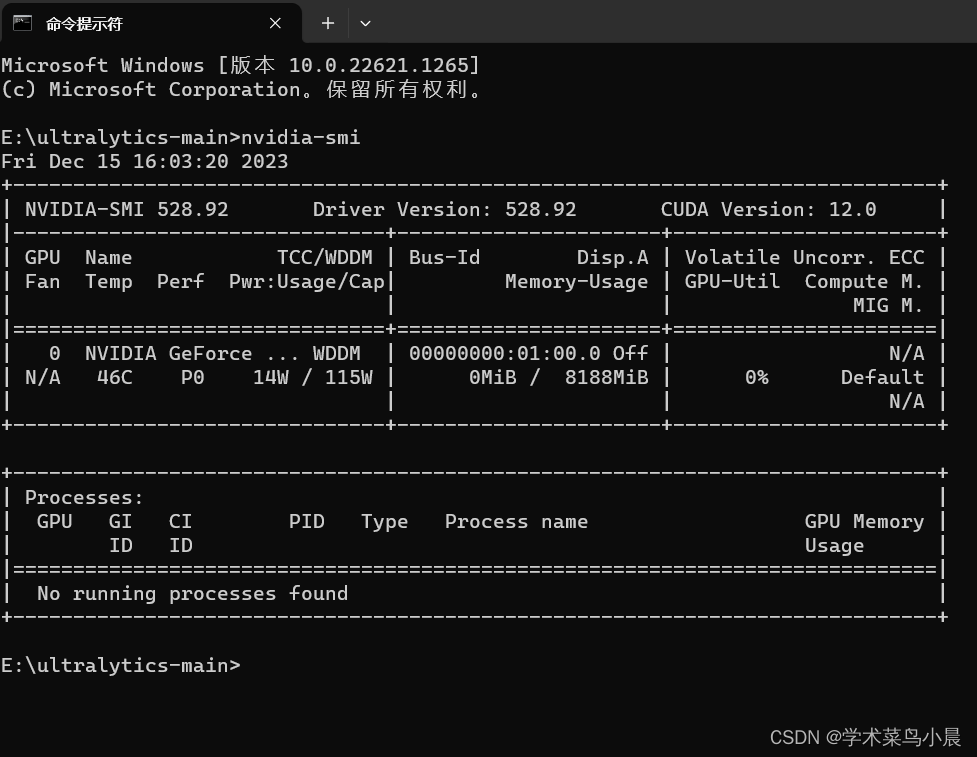
第二步、yolo8代码下载
https://github.com/ultralytics/ultralytics
第三步、cuda及cudnn安装
- https://developer.nvidia.com/cuda-toolkit-archive
-
- https://developer.nvidia.com/rdp/cudnn-archive
第四步、安装anaconda
https://www.anaconda.com/download环境变量设置(安装在哪里就找那个路径):
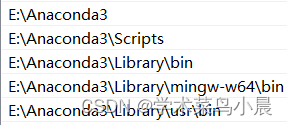
第五步、创建python环境
conda create -n yolo python==3.11 conda环境操作指南:
- 查看现有环境 conda env list
-
- 激活失败 conda init cmd.exe
-
- 删除环境 conda env remove -n yolo
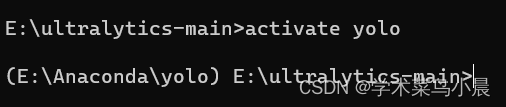
第六步、激活环境
一定要选择命令提示符。
activate yolo以后每次使用都要激活该环境。
第七步、安装pytorch
https://pytorch.org/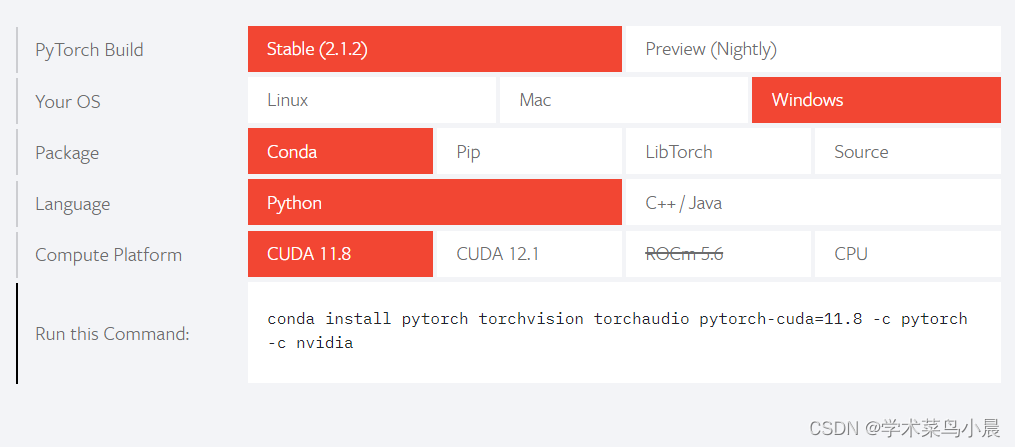
我是cuda12.0,所以安装cuda11.8版本。
- conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
- 或:
- pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
第八步、安装库
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
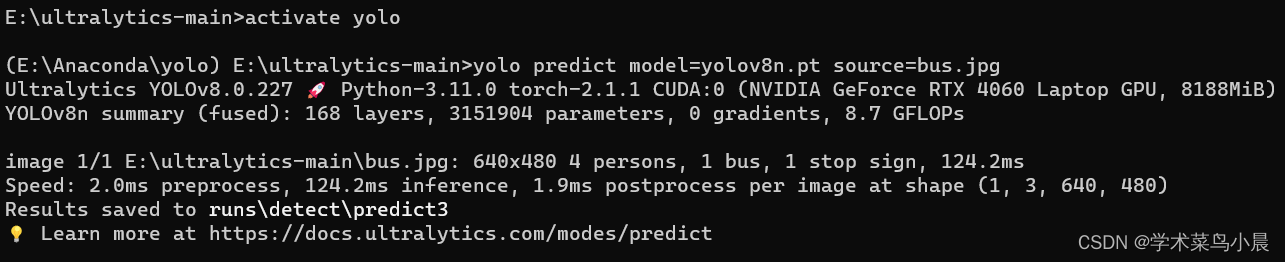
第九步、推理检测
yolo predict model=yolov8n.pt source=bus.jpg图片名自己设置,自动下载模型yolov8n.pt,结果在runs文件夹中。

第十步、训练
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01自动训练下载数据集datasets,报错:
- OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "E:\Anaconda3\envs\yolov8\lib\site-packages\torch\lib\nvfuser_codegen.dll" or one of its dependencies.
- Traceback (most recent call last):
- File "<string>", line 1, in <module>
- File "E:\Anaconda3\envs\yolov8\lib\multiprocessing\spawn.py", line 116, in spawn_main
- exitcode = _main(fd, parent_sentinel)
- File "E:\Anaconda3\envs\yolov8\lib\multiprocessing\spawn.py", line 126, in _main
- self = reduction.pickle.load(from_parent)
- File "E:\Anaconda3\envs\yolov8\lib\site-packages\torch\__init__.py", line 128, in <module>
- raise err
- OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "E:\Anaconda3\envs\yolov8\lib\site-packages\torch\lib\nvfuser_codegen.dll" or one of its dependencies.
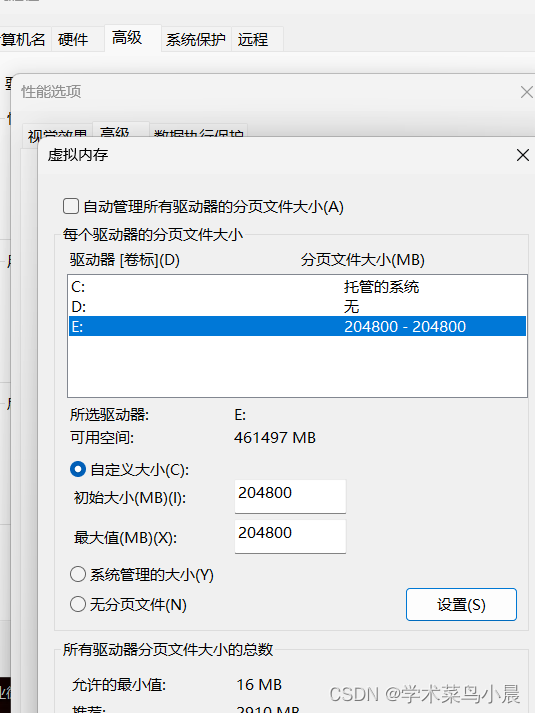
设置安装anaconda所在盘的虚拟内存。
二、yolov8训练自己的数据集
第一步、数据准备
在yolov8中建立datasets文件夹,然后建立数据集文件夹mydata。
mydata中是imges图片文件和label标注后的Annotations xml文件夹和imageSets。
其中使用makeTxt.py,给数据分类trian val test。
- import os
- import random
-
- trainval_percent = 0.1
- train_percent = 0.9
- xmlfilepath = './Annotations'
- txtsavepath = './ImageSets'
- total_xml = os.listdir(xmlfilepath)
-
- num = len(total_xml)
- list = range(num)
- tv = int(num * trainval_percent)
- tr = int(tv * train_percent)
- trainval = random.sample(list, tv)
- train = random.sample(trainval, tr)
-
- ftrainval = open('./ImageSets/trainval.txt', 'w')
- ftest = open('./ImageSets/test.txt', 'w')
- ftrain = open('./ImageSets/train.txt', 'w')
- fval = open('./ImageSets/val.txt', 'w')
-
- for i in list:
- name = total_xml[i][:-4] + '\n'
- if i in trainval:
- ftrainval.write(name)
- if i in train:
- ftest.write(name)
- else:
- fval.write(name)
- else:
- ftrain.write(name)
-
- ftrainval.close()
- ftrain.close()
- fval.close()
- ftest.close()
运行后ImageSets文件夹生成四个txt。
再使用voc_label.py,将数据转换成label格式。修改自己的类,逗号隔开,我训练的就一个“老鼠”类。
- import xml.etree.ElementTree as ET
- import pickle
- import os
- from os import listdir, getcwd
- from os.path import join
-
- sets=[('train'), ('test'),('val')]
-
- classes = ["mouse"]
-
-
- def convert(size, box):
- dw = 1./(size[0])
- dh = 1./(size[1])
- x = (box[0] + box[1])/2.0 - 1
- y = (box[2] + box[3])/2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x*dw
- w = w*dw
- y = y*dh
- h = h*dh
- return (x,y,w,h)
-
- def convert_annotation(image_id):
- in_file = open('Annotations/%s.xml'%(image_id))
- out_file = open('labels/%s.txt'%( image_id), 'w')
- tree=ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
-
- for obj in root.iter('object'):
- # difficult = obj.find('difficult').text
- cls = obj.find('name').text
- # if cls not in classes or int(difficult)==1:
-
- if cls not in classes:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
- bb = convert((w,h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
- wd = getcwd()
-
- for image_set in sets:
- if not os.path.exists('labels/'):
- os.makedirs('labels/')
- image_ids = open('ImageSets/%s.txt'%(image_set)).read().strip().split()
- list_file = open('%s.txt'%(image_set), 'w')
- for image_id in image_ids:
- list_file.write('%s/images/%s.jpg\n'%(wd,image_id))
- convert_annotation(image_id)
- list_file.close()
-
- #os.system("cat 2008_train.txt > train.txt")
- #os.system("cat 2008_train.txt 2008_val.txt > train.txt")
- #os.system("cat 2008_train.txt 2008_val.txt 2008_test.txt> train.txt")
-
- #os.system("cat 2014_train.txt 2014_val.txt 2012_train.txt 2012_val.txt > train.txt")
- #os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
运行后生成labels文件夹和三个txt。
至此数据准备工作完成,开始训练。
第二步、训练
建立一个yaml文件
shu.yaml
- train: E:/ultralytics-main/datasets/mydata/train.txt
- val: E:/ultralytics-main/datasets/mydata/val.txt
-
-
- # Classes
- names:
- 0: mouse
训练指令:
yolo train data=shu.yaml model=yolov8n.pt epochs=100 lr0=0.01

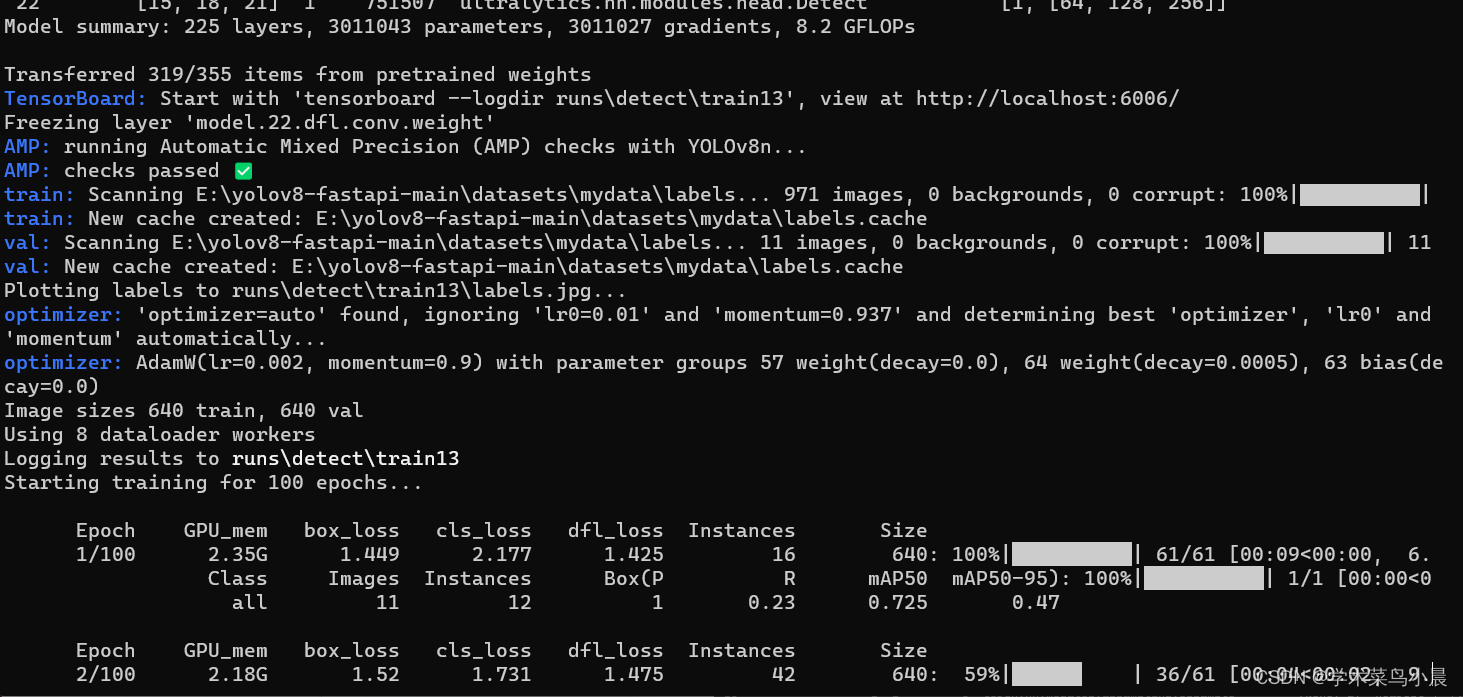
至此训练完成。 在runs中生成训练结果和训练模型。
训练结果分析:yolov8实战第二天——yolov8训练结果分析(保姆式解读)-CSDN博客
第三步、测试
使用训练后的模型进行测试。
测试指令:
yolo predict model=runs/detect/train12/weights/best.pt source=datasets/mydata/images/mouse-4-6-0004.jpg


