
- 1【C语言】魔方阵的实现(最全)_魔方阵c语言程序设计
- 2很好的推荐书籍
- 3【工具使用】——MSF使用_MSF中kiwi(mimikatz)模块的使用_load kiwi
- 4单片机能运行操作系统吗?_单片机操作系统
- 556. 合并区间 - 力扣(LeetCode)
- 6Golang:监听binlog日志_golang监听binlog
- 7【全文】狼叔:如何正确的学习Node.js
- 8常用经典SQL语句大全完整版--详解+实例
- 9【Copilot】登录报错 Extension activation failed: “No auth flow succeeded.“(VSCode)
- 10因果推断7--深度因果模型综述(个人笔记)
Flink Kafka connector详解
赞
踩
在Flink中提供了特殊的Connectors从kafka中读写数据,它基于Kafka Consumer API以及Producer API封装了自己的一套API来连接kafka,即可读取kafka中的数据流,也可以对接数据流到kafka中,基于kafka的partition机制,实现了并行化数据切片。下面让我们来看看它的主要API以及使用。
Flink kafka consumer
使用kafka-connector还需要导入单独的依赖包,它对应着不同版本的kafka,下面这张表是kafka-connector的不同版本的AP以及区别。

Flink kafka Consumer的API类继承图如下:
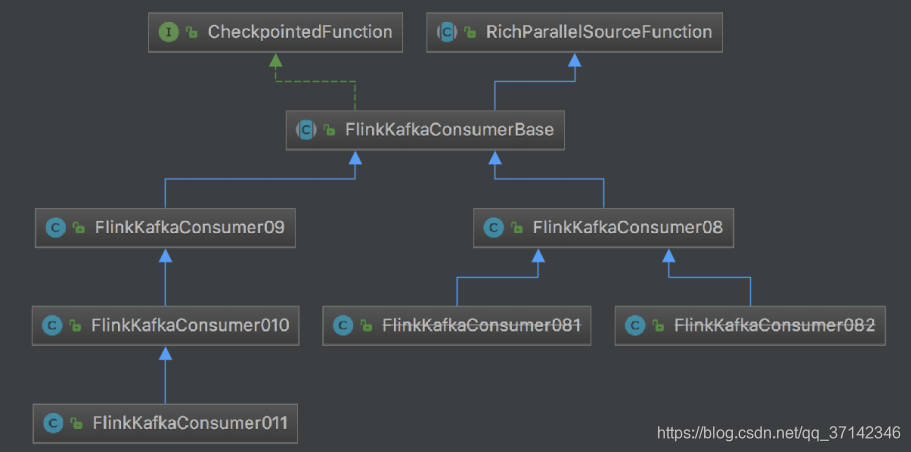
在其中一个版本的API为例,我们看一下其构造函数:
FlinkKafkaConsumer010(String topic, DeserializationSchema<T> valueDeserializer, Properties props)
FlinkKafkaConsumer010(String topic, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, DeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(Pattern subscriptionPattern, KeyedDeserializationSchema<T> deserializer, Properties props)
- 1
- 2
- 3
- 4
- 5
这里主要有三个构造参数:
- 要消费的topic(topic name / topic names/正表达式)
- DeserializationSchema / KeyedDeserializationSchema(反序列化Kafka中的数据)
- Kafka consumer的属性,其中三个属性必须提供:bootstrap.servers (逗号分隔的Kafka broker列表) 、 zookeeper.connect (逗号分隔的Zookeeper server列表) (仅Kafka 0.8需要) 、group.id(consumer group id)
当我们从kafka中消费数据的时候,就需要反序列化操作,因此Flink提供了反序列化操作的接口DeserializationSchema/KeyedDeserializationSchema,后者的区别是带有key,以下是几种常用的反序列化schema:
- SimpleStringSchema
- JSONDeserializationSchema / JSONKeyValueDeserializationSchema
- TypeInformationSerializationSchema/ TypeInformationKeyValueSerializationSchema(适合读写均是flink的场景)
- AvroDeserializationSchema
代码示例如下:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
// only required for Kafka 0.8
properties.setProperty("zookeeper.connect", "localhost:2181");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer08<>("topic", new SimpleStringSchema(), properties));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Flink kafka consumer的消费模式设置
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<>(...);
myConsumer.setStartFromEarliest(); // start from the earliest record possible
myConsumer.setStartFromLatest(); // start from the latest record
myConsumer.setStartFromTimestamp(...); // start from specified epoch timestamp (milliseconds)
myConsumer.setStartFromGroupOffsets(); // the default behaviour
DataStream<String> stream = env.addSource(myConsumer);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- setStartFromEarliest:从队头开始,最早的记录,内部的Consumer提交到Kafka/zk中的偏移量将被忽略。
- setStartFromLatest:从队尾开始,最新的记录,内部的Consumer提交到Kafka/zk中的偏移量将被忽略。
- setStartFromGroupOffsets():默认值,从当前消费组记录的偏移量开始,接着上次的偏移量消费,以Consumer提交到Kafka/zk中的偏移量最为起始位置开始消费,group.id设置在consumer的properties里;如果没找到记录的偏移量,则使用consumer的properties的auto.offset.reset设置的策略。
- setStartFromSpecificOffsets(Map<TopicPartition, Long>的参数):从指定的具体位置开始消费
- setStartFromTimestamp(long):从指定的时间戳开始消费,对于每个分区,时间戳大于或等于指定时间戳的记录将用作起始位置。如果一个分区的最新记录早于时间戳,那么只需要从最新记录中读取该分区。在此模式下,Kafka/zk中提交的偏移量将被忽略。
如何保证其容错性呢?
我们可以通过checkpoint的方式来保证,如果Flink启用了检查点,Flink Kafka Consumer将会周期性的checkpoint其Kafka偏移量到快照。如果作业失败,Flink将流程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新消费Kafka中的记录。
Flink Kafka Consumer offset提交行为:
- 禁用Checkpoint:Flink Kafka Consumer依赖于内部使用的Kafka客户端的自动定期偏移提交功能。因此,要禁用或启用偏移量提交,只需将enable.auto.commit(或auto.commit.enable for Kafka 0.8) / auto.commit.interval.ms设置设置到Kafka客户端的Properties。
- Checkpoint时会保存Offset到snapshot,当一次Checkpoint完成时,Flink Kafka Consumer将snapshot中的偏移量提交给kafka/zookeeper。这确保Kafka Consumer中提交的偏移量与检查点状态中的偏移量一致。用户可以通过调用Flink Kafka Consumer setCommitOffsetsOnCheckpoints(boolean)方法来禁用或启用偏移提交到kafka/zookeeper (默认情况下,行为为true)。 在此场景中,Properties中的自动定期偏移量提交设置将被完全忽略。
Flink还支持动态分区的发现,即当我们需要扩充集群或者缩减集群规模的时候,kafka的partition可能会发现改变,我们并不需要重启Flink就可以保证数据被完整消费以及负载均衡,并且保证消费的exactly-once语义。
默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用:properties.setProperty(“flink.partition-discovery.interval-millis”, “30000”)。
Flink kafka producer
Flink kafka producer API的类继承关系图如下:
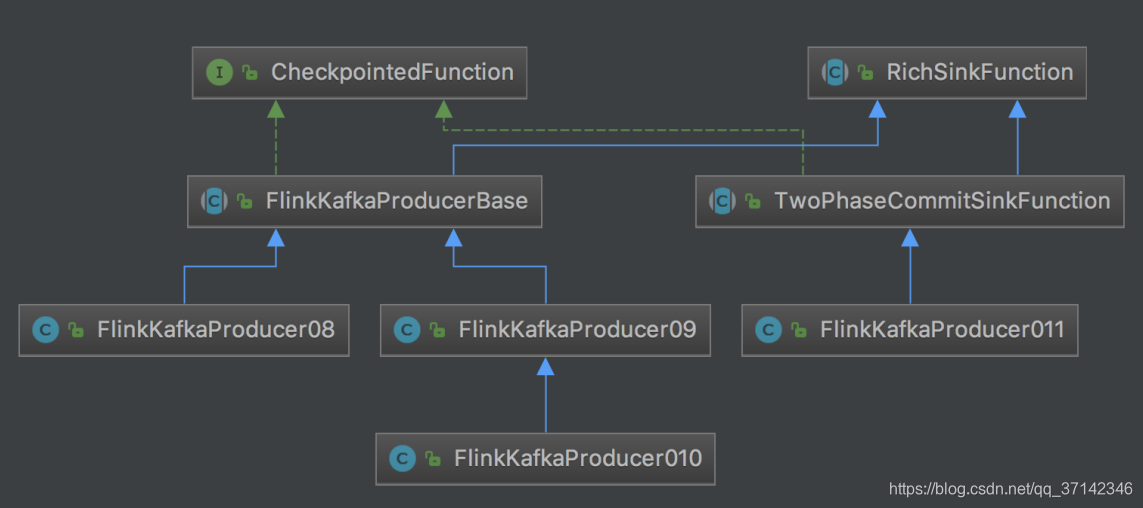
其主要构造函数如下:
FlinkKafkaProducer010(String brokerList, String topicId, SerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, SerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String brokerList, String topicId, KeyedSerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, KeyedSerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String topicId,SerializationSchema<T> serializationSchema,Properties producerConfig,@Nullable
FlinkKafkaPartitioner<T> customPartitioner)
FlinkKafkaProducer010(String topicId,KeyedSerializationSchema<T> serializationSchema,Properties
producerConfig,@Nullable FlinkKafkaPartitioner<T> customPartitioner)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其构造函数的参数与上面consumer的类似,这里不再赘述。这里简单介绍一下FlinkKafkaPartitioner,默认的是FlinkFixedPartitioner,即每个subtask的数据写到同一个Kafka partition中。我们还可以自定义分区器,继承FlinkKafkaPartitioner(partitioner的状态在job失败时会丢失,不会checkpoint)。
FlinkKafkaProducer的容错性保证:
Kafka 0.8:
at most once(有可能丢数据)
Kafka 0.9/0.1:
- 启动checkpoint时默认保证at-least-once(有可能重复);
- setLogFailuresOnly(boolean) 默认是false (false保证at-least-once) 往kafka发送数据失败了是否打日志:False:不打日志,直接抛异常,导致应用重启(at-least-once),True:打日志(丢数据);
- setFlushOnCheckpoint(boolean) 默认是true (true 保证at_least_once),Flink checkpoint时是否等待正在写往kafka的数据返回ack。
Kafka 0.11:
- 必须启动checkpoint
- 可以通过构造参数选择容错性语意:Semantic.NONE:可能丢失也可能重复;Semantic.AT_LEAST_ONCE:(默认值),不会丢失,但可能重复;Semantic.EXACTLY_ONCE:使用Kafka事务提供exactly-once语义




