
热门标签
热门文章
- 1Dockerfile ADD指令 语法解析_docker --chown
- 2R语言学习笔记(一)R语言的基本操作与函数_r语言清屏
- 3R语言访问数据框某一列的特定元素_r语言显示某一列
- 4Python | 蓝桥杯系列文章总结+经典例题重做_蓝桥杯题目python语言
- 5【南卡樱桃|读书笔记《学习高手》】_学习高手第一章内容摘抄
- 6Flash钓鱼_xn--8mr243bblog9b.top
- 7nacos学习二,SpringCloud整合nacos、feign、gateway_nacos gateway feign 整合
- 8(三)Intel SGX AESM Service是什么?_aesm_service.exe
- 9D*路径搜索算法原理解析及Python实现_focussed d*
- 10链表——24. 两两交换链表中的节点
当前位置: article > 正文
爬虫工作量由小到大的思维转变---<第三十三章 Scrapy Redis 23年8月5日后会遇到的bug)>
作者:算法优化者 | 2024-01-29 13:30:47
赞
踩
爬虫工作量由小到大的思维转变---<第三十三章 Scrapy Redis 23年8月5日后会遇到的bug)>
前言:
收到回复评论说,按照我之前文章写的:
爬虫工作量由小到大的思维转变---<第三十一章 Scrapy Redis 初启动/conn说明书)>-CSDN博客
在启动scrapy-redis后,往redis丢入url网址的时候遇到:
TypeError: ExecutionEngine.crawl() got an unexpected keyword argument 'spider
整得人都崩溃了....
好嘛,来解决这个问题!
正文:
代码
-
- __author__ = '大河之J天上来'
-
-
- from scrapy import cmdline
- from scrapy_redis.spiders import RedisSpider
-
- class DahezhijianSpider(RedisSpider):
- name = "Dahezhijian"
-
- redis_key = 'da:he'
-
- def parse(self, response):
- print(response.text)
-
-
-
-
- if __name__ == '__main__':
- cmdline.execute(['scrapy','crawl','Dahezhijian'])
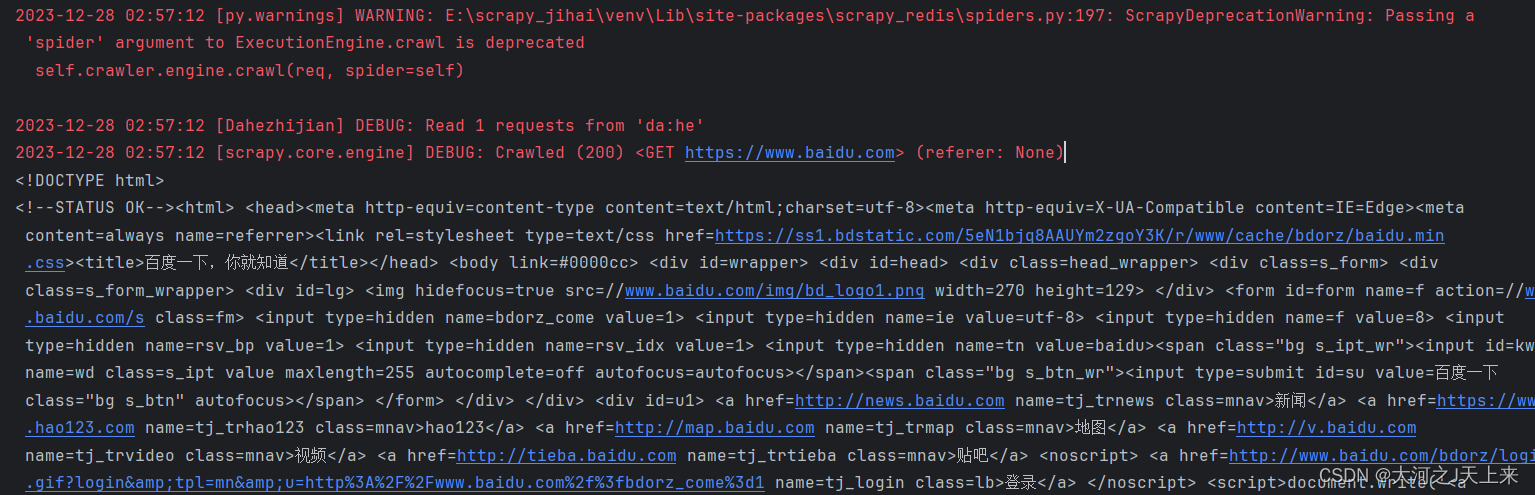
还原问题(截图):
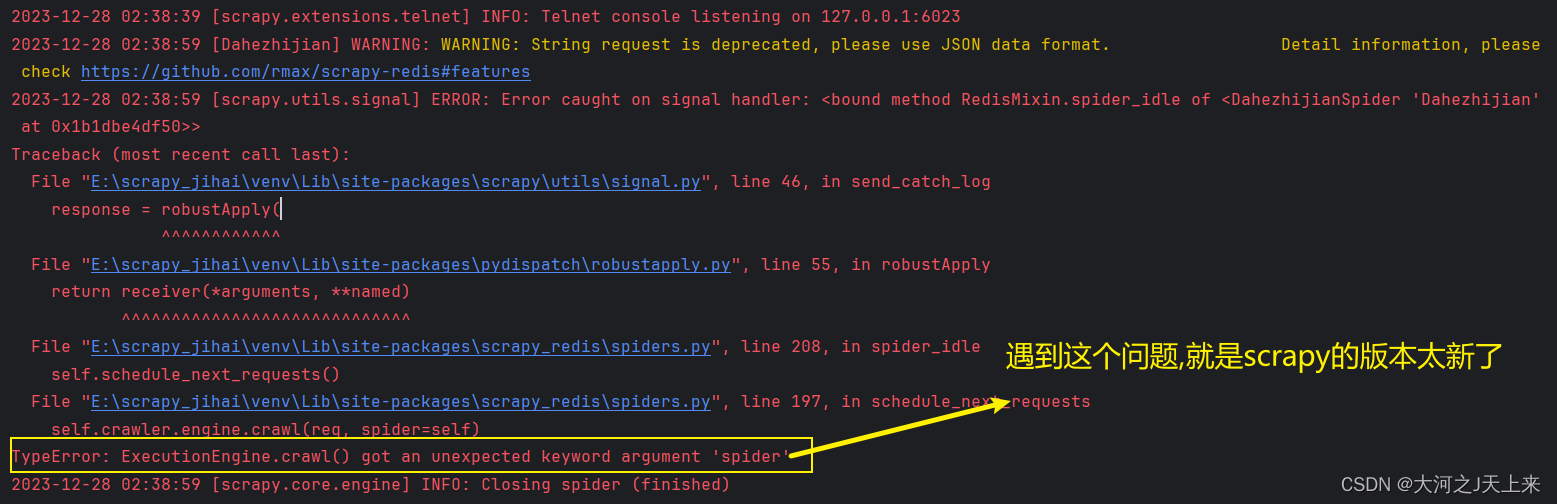
问题追溯:
1.查看版本:
我用的版本是:
也就是2023年12月28日的最新版~ 也会遇到这个问题!!!
2.追踪更新:
scrapy的最新版是2023.9.18 (真特么会挑日子! 918,我才看到! 以后我都不用这版本了...)

而scrapy_redis的最新版是:(2022年7月26日)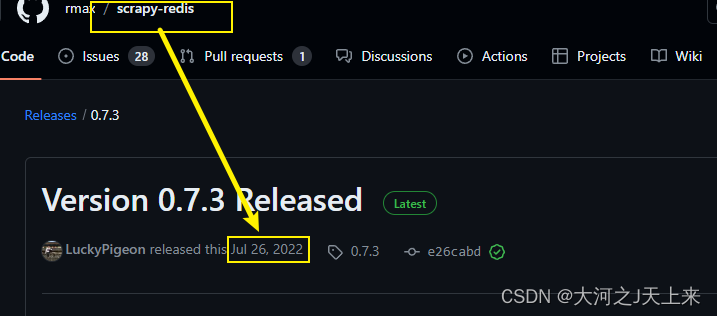
----相差了1年零2个月,我估计明年1到2月 redis要更新了的..
3.莫问别人,先管自己:
我帮大家测试过了,>=2.10.0现在都不兼容scrapy_redis;
直接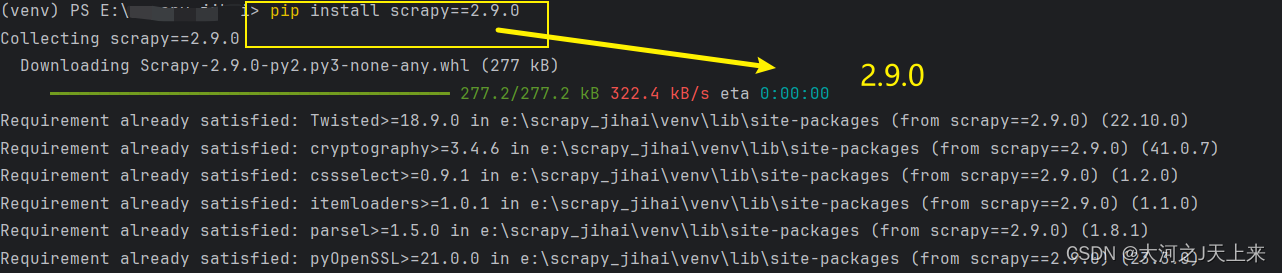
4.最终搭配:
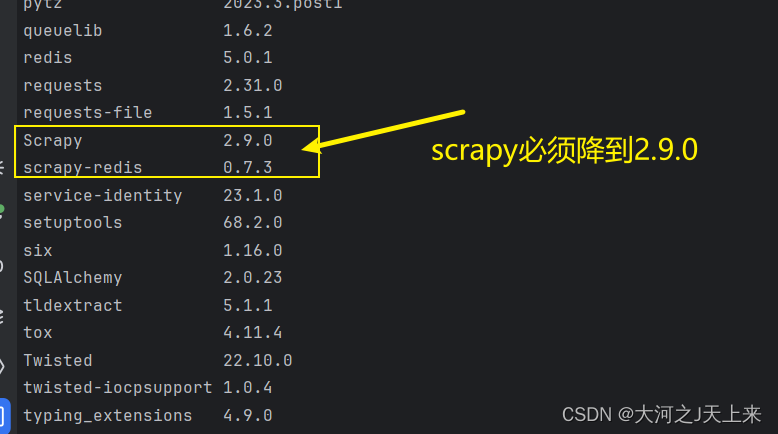
成功!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/43108
推荐阅读


相关标签

