
- 1浅谈前端开发转型鸿蒙移动端开源系统开发:HarmonyOS开发者成长之路_鸿蒙开发前端
- 2DDoS攻击防御和分析_ddos攻击防护系统安全分析
- 3【debug】error: subprocess-exited-with-error
- 4OpenGL ES 3.0 开发(十六):相机预览_谷歌相机gl预览是什么意思
- 5关于 Git 的一些常识和我的一些零言碎语_hexo 撤销提交
- 6计算机网络 应用层
- 7python福建福州购物店铺数据可视化大屏全屏系统设计与实现(django框架)
- 8STM32 HAL库开发——基础篇
- 9【Java定时任务】Timer、Quartz、Spring、LinuxCron对比
- 10Unity学习笔记_01.Unity介绍,下载与安装_unity 53编译器
双非本科准备秋招(5)——力扣回溯法解决链表问题、Collection接口的实现类与源码追踪1
赞
踩
每天记录博客让我有动力保持学习状态,每天不学点东西写写博客都对不起自己,学的时候不认真都不好意思写下来,把每天学的东西再清晰地表达一遍对我来说还是蛮困难和耗时间的,但写完之后感觉自己的思路也清晰了很多,好多有遗忘的知识点又重新想起来了,果然,输出是最好的学习方式。
LeetCode链表
1、206. 反转链表
昨天用的头插法,今天跟着黑马学了下递归,不过没看完,用递归解决问题还是挺抽象的。
我们先看看反转链表的递归代码,再解释一下。
- public ListNode reverseList(ListNode head) {
- if(head == null || head.next == null){
- return head;
- }
- ListNode last = reverseList(head.next);
- head.next.next = head;
- head.next = null;
- return last;
- }
递归就是自己调用自己,那肯定要有一个出口,就是递归的终止条件,当head.next为null时,我们返回的这个节点就是最后一个节点了,为啥要判断head==null呢,因为题目可能给你个空链表,head一开始为null,那head.next不就成了NullPointerException了嘛。
我们用last变量记录每次的返回值,所谓递归,就是先递,然后归,所以“递”伪代码的执行过程应该如下:
- reverseList(1) {
- reverseList(2){
- reverseList(3){
- reverseList(4){
- reverseList(5){
- (head.next == null)
- return head;
- }
-
- }
- }
- }
- }
代码会“递”到最后一层,每次都做调用自己函数之前的代码,因为只有判断退出条件,所以我就省略了之前的。
下面添加了“归”的部分,我只写了第4和第3层。
- reverseList(1) {
- reverseList(2){
- reverseList(3){
- reverseList(4){
- reverseList(5){
- (head.next == null)
- return head;
- }
- head是4 head.next是5
- 是不是要让head.next->head,即head.next.next=head
- 5->4
- 然后last是5,返回last
- }
- head是3,head.next是4
- 4->3
- 然后last是5,返回last
- }
- }
- }

做做这个题大概能窥探到递归的一些巧妙之处,比如last的值在每层中都不变,可以理解为这样的过程:last = (return last = ( return last = 5));再比如每层的局部变量是保留着的,每一层中的head的值都不一样。
当然这只是简单的单层递归,还有复杂的多路递归等等,而且看题解和自己实际去分析新的题目也截然不同,只能多做题目多思考,这样才能有进步。
2、203. 移除链表元素
学会了递归,再做做这个题应该是有思路的,我的思路就来自思考“递”、“归”这两个过程,我们先递到最里面,然后开始归。
比如说我们要删除都等于6的伪代码
- removeElements(head:2, val:6) {
- removeElements(1, 6) {
- removeElements(4, 6) {
- removeElements(6, 6) {
- removeElements(null, 6) {
- return null;
- }
- head的值等于6,所以不返回我自己(head),只需要返回之前结点的。
- return null;
- }
- head的值不等6,返回我自己(head)加上之前的返回结果
- return 4->null;
- }
- return 1->4->null;
- }
- return 2->1->4->null;
- }
具体表现在代码中怎么写呢:
- public ListNode removeElements(ListNode head, int val) {
- if(head == null){
- return null;
- }
- else if(head.val == val){
- return removeElements(head.next, val);
- }
- else{
- head.next = removeElements(head.next, val);
- return head;
- }
- }
这已经算是多路递归了吧,乍看起来还是挺抽象滴。我在伪代码里说的之前结点,其实就是递归调用下一个结点的意思,所谓“之前”就是伪代码中的前面部分,比如head=4之前的代码,其实就是递归调用下一个结点的代码(removeElements(6, 6))对吧
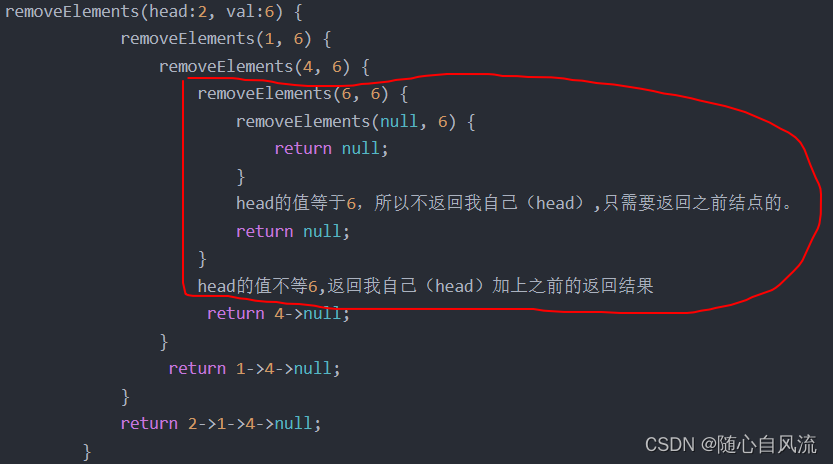
总结:确实挺抽象的。
3、19. 删除链表的倒数第 N 个结点
思路还是思考“递”、“归”这两个过程,因为是删除倒数的,但是链表长度事先又是未知的,所以可以先“递”到最里层,然后开始“归”,“归”的时候维护一个变量,用来记录归到第几层了,这样就能找到倒数第几个元素了。
比如我写个伪代码:
- recursion(sentinel, 2){
- recursion(1, 2){
- recursion(2, 2){
- recursion(3, 2){
- recursion(null, 2){
- return 0;
- }
- }
- 我是倒数第二个元素,删除我!
- }
- }
- }
如果我要删倒数第2个元素,我是不是应该在它的上一层删除,对吧,因为链表删除元素就是用这个元素的上一个元素指向这个元素的下一个元素,所以我们最后一层返回0,这样才能到了倒数第3层是才开始删除倒数第3个元素。
代码如下:
- class Solution {
- public ListNode removeNthFromEnd(ListNode head, int n) {
- ListNode sentinel = new ListNode(-1, head);
- recursion(sentinel, n);
- return sentinel.next;
- }
- private int recursion(ListNode p, int n){
- if(p == null){
- return 0;
- }
- int cnt = recursion(p.next, n);//下一个节点倒数位置
- if(cnt == n){
- p.next = p.next.next;
- }
- return cnt+1;//当前节点倒数位置
- }
- }
还是一样的例子,设置一个sentinel头指针方便操作链表,无需考虑头结点了,当到了第3层时,cnt == n,因为到了第二层时cnt=1,返回了cnt+1,于是第三层的cnt就等于2了。
那就用p->p.next.next,即p.next=p.next.next
4、24. 两两交换链表中的节点
这个我用画图解决的,我先不考虑0个和1个结点的情况,也不考虑奇偶数的情况,然后自己模拟了一次,多模拟几次后总结规律,就做出来啦。
我先定义了两个指针。

第一次,我肯定不能先让2指向1吧,那样链表就断了,3就找不到了,所以先让1指向3,也就是1指向2.next(p1.next = p2.next)

然后再放心地让2指向1(p2.next->p1)

然后我就继续移动p1和p2,看看能不能重复这个过程,p1=p1.next,p2=p1.next
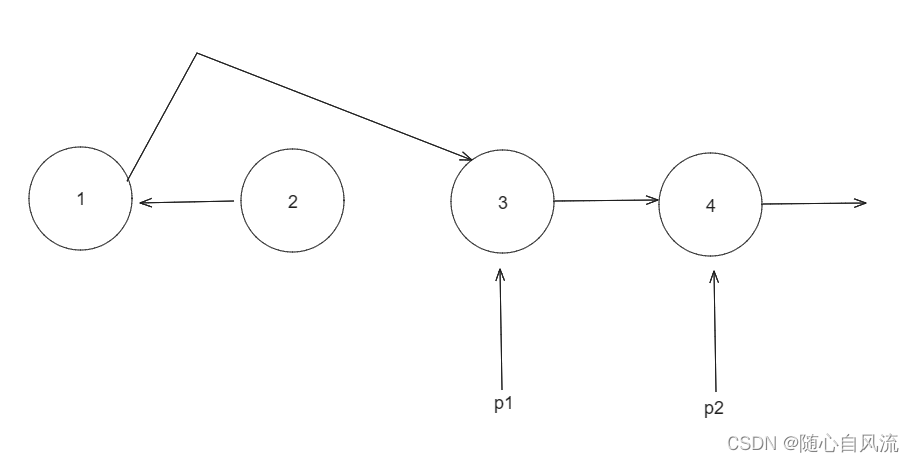
继续执行上述过程

乱套了吧,2->1->3->null,所以,这个过程本身没错,但是少了一步,应该让1先指向4,然后再执行这个过程,那后面的过程肯定也这样,让3指向6,再执行这个过程···
所以我再设置一个变量last用来操作1指向4的这种过程。last一开始指向1,先让它指向4
 然后再转移last,让last=p1
然后再转移last,让last=p1

于是,核心的循环代码就出来了:
注意p1移动后可能为null,p1.next就是空指针异常了。

所以,代码如下,我把0个和1个元素单独判断了
- public ListNode swapPairs(ListNode head) {
- if(head == null || head.next == null){
- // 0个或1个
- return head;
- }
-
- ListNode p1 = head, last = head, p2 = p1.next;
- ListNode ans = p2;
- while(p1 != null && p2 != null){
- last.next = p2;//先连接
- last = p1;//后转移
- p1.next = p2.next;
- p2.next = p1;
- //移动p1和p2
- p1 = p1.next;
- if(p1==null) break;
- p2 = p1.next;
- }
-
- return ans;
- }
Collection学习-day1
集合这些东西,之前从来没怎么深入学过,用的时候网上搜搜使用方法就满足了,这两天系统地学一下,并且深入源码,这是我第一次看源码,知道一些原理和细节后,感觉整个人都升华了。
另外每个jdk版本更新后源码都不一样,我跟着韩顺平老师学的,他的jdk应该是1.8,ArrayList的源码和我的jdk11就有些许区别。
Collection体系图:
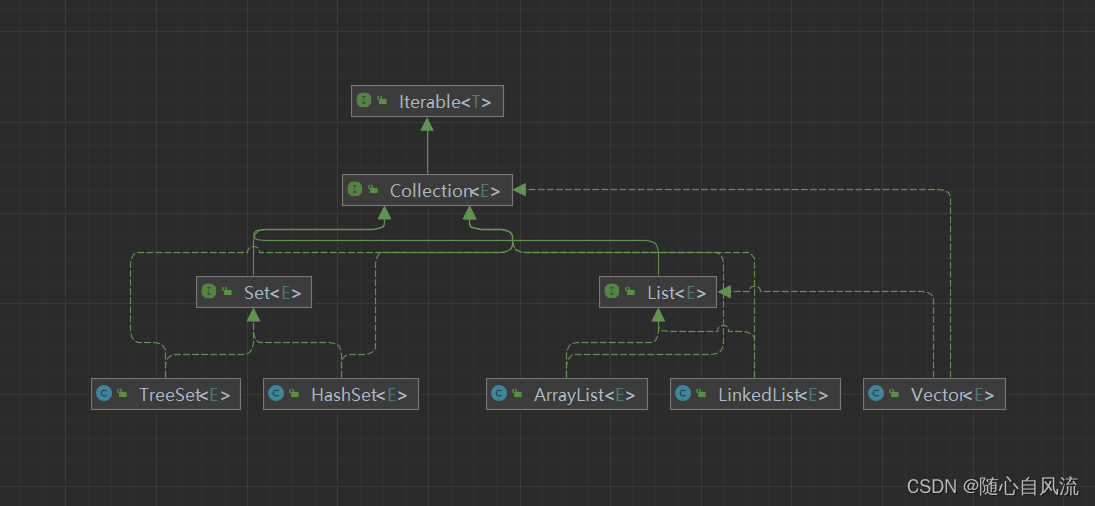
Set和List接口继承了Collection接口,而它们的实现类都间接实现了Collection接口,所以先学习一下Collection接口提供的通用方法,因为接口不能创建对象,所以以ArraryList实现类来演示
- public static void test1(){
- ArrayList list = new ArrayList();
- // add:添加单个元素
- list.add(12);//自动装箱
- list.add(13);
- System.out.println("add: " + list);
- // remove:删除指定元素
- list.remove(new Integer(12));//删除指定元素,直接写12会当成下标
- list.remove(0);//删除指定下标
- System.out.println("remove: " + list);
- // contains:查找元素是否存在
- boolean contains = list.contains(12);
- System.out.println("contains 12: " + contains);
- // size:获取元素个数
- System.out.println("size: " + list.size());
- // isEmpty:判断是否为空
- System.out.println("isEmpty: " + list.isEmpty());
- // clear:清空
- list.add(12);
- list.clear();
- System.out.println("clear: " + list.size());
- // addAll:添加多个元素
- ArrayList list1 = new ArrayList();
- list1.add(true);
- list1.add("嘿嘿嘿");
- list.addAll(list1);
- System.out.println("addAll: " + list);
- // containsAll:查找多个元素是否都存在
- boolean b = list.containsAll(list1);
- System.out.println("containsAll: " + b);
- // removeAll:删除多个元素
- list.removeAll(list1);
- System.out.println("removeAll: " + list1);
- }
-
- 控制台会输出如下信息:
- add: [12, 13]
- remove: []
- contains 12: false
- size: 0
- isEmpty: true
- clear: 0
- addAll: [true, 嘿嘿嘿]
- containsAll: true
- removeAll: [true, 嘿嘿嘿]
三个常用的实现类比较:
ArrayList和LinkedList都是线程不安全的;Vector是线程安全的,因为用了synchronzied。
ArrayList(jdk1.2出现)和Vector(jdk1.0出现)底层结构都是可变数组;LinkedList底层结构是双向链表(JDK1.7之前是双向循环链表,JDK 1.7设置了两个哨兵节点,分别指向头部和尾部,所以不用循环也能快速找到头尾节点,从而正反遍历)
ArrayList调用无参构造时,默认会开辟10个空间,每次扩容1.5倍,如果调用有参构造,那每次扩容扩大入参的1.5倍;Vector同理,默认也是10个空间,但是每次扩容时2倍。
ArrayList的创建与add方法源码:
调用无参构造

打个断点进入ArrayList.java中

无参构造执行,将DEFAULTCAPACITY_EMPTY_ELEMENTDATA赋值给elementData,DEFAULTCAPACITY_EMPTY_ELEMENTDATA其实就是空的Object数组。

add方法

首先进行装箱,调用ValueOf方法将int转为Integer,不是重点,接着下一步

调用add方法,modCount记录加了几次,add继续调用add方法,这里是方法重载。
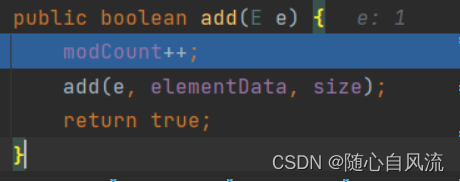
进入到另一个add方法,s是下标,初始值为0,当s==elementtData.length时,说明需要扩容,调用grow方法进行扩容;否则,就把e赋值给当前elementData[s],然后更新size=s+1
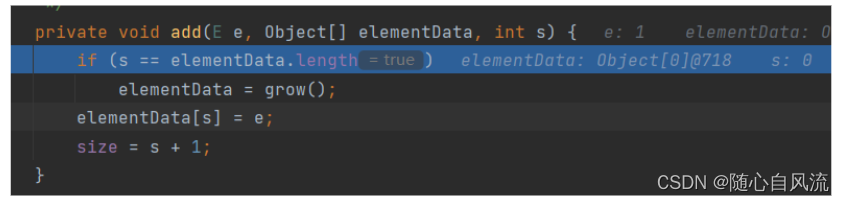
进入grow方法,这里也是方法重载,gorw调用grow的另一个重载方法

进入另一个重载方法,这个minCapacity是size+1,所以minCapacity代表现在需要多大的容量,
然后使用Arrays.copyOf把新的数组拷贝到elementData数组中,copyOf这个方法会保留之前的元素。
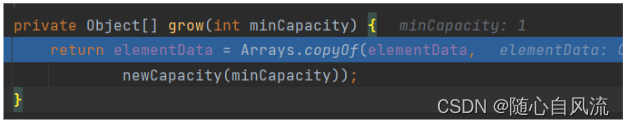
进入newCapacity,这里就是代码的核心啦,它返回int类型的值,代表扩容后数组大小,oldCapacity代表目前数组长度,newCapacity代表扩容后的数组的长度,oldCapacity>>1相当于除以2,再与原来的值相加,所以是1.5倍扩容。
if条件:newCapacity - minCapacity <= 0,minCapacity是目前需要的最小容量,如果当前需要的最小容量都超过扩容后的,就要进入这个分支,比如第一次扩容,newCapacity肯定是0,minCapacity肯定大于0,所以会进入。
进入后第一个if,elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA,就是判断是不是空嘛,是就返回默认值10(DEFAULT_CAPACITY)和minCapacity的最大值。
进入后第二个if,minCapacity溢出了,也就是扩容到int最大值了,那就抛出错误。
如果都不是,说明最小容量minCapacity比新扩容的值大,返回minCapacity就好。
- private int newCapacity(int minCapacity) {
- // overflow-conscious code
- int oldCapacity = elementData.length;
- int newCapacity = oldCapacity + (oldCapacity >> 1);
- if (newCapacity - minCapacity <= 0) {
- if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
- return Math.max(DEFAULT_CAPACITY, minCapacity);
- if (minCapacity < 0) // overflow
- throw new OutOfMemoryError();
- return minCapacity;
- }
- return (newCapacity - MAX_ARRAY_SIZE <= 0)
- ? newCapacity
- : hugeCapacity(minCapacity);
- }
如果都不是这些情况,那就返回newCapacity就好,但是这里很严谨,先判断一下它是不是比MAX_ARRAY_SIZE小,这个值是ArrayList定义的,比最大值小8,因为有些JVM可能会在数组里保留一些其他内容,分配更多可能出问题,了解就行(其实我也不懂,还没学JVM···)。

如果超过了,进入hugeCapacity,也是先判断一下minCapacity溢出没,然后返回扩容后的值。

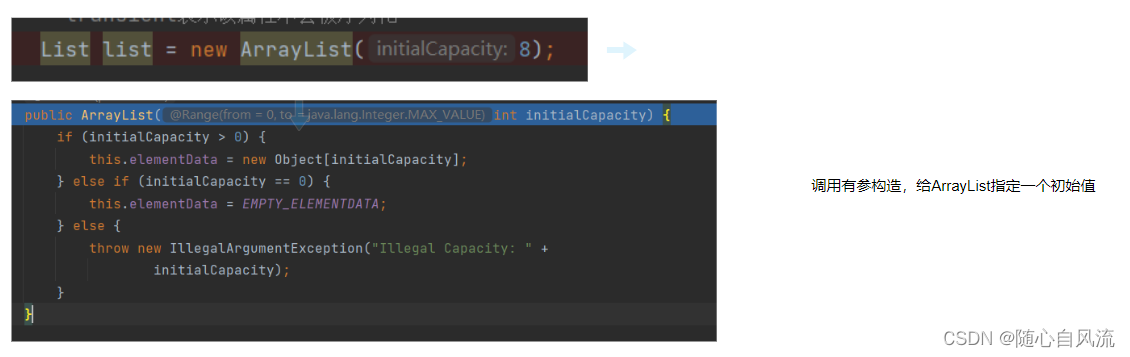
调用无参构造方法
直接贴图啦,其实也没啥难的,判断一下是否合法,合法就赋值,不合法抛异常。
Vector的明天再写吧,HashSet的底层是HashMap,比较复杂了,等明天学完HashMap一起写吧,太晚了,休息休息。



