
- 1计算机管理中没有vhd,防患于未然,安全体验Win11很简单
- 2MyBatis常见面试题汇总
- 3Jmeter之HTTP请求详解_jmeter http请求
- 4python爬取微博数据_Python selenium爬取微博数据代码实例
- 5ChatGPT目前的AI一哥
- 6机器学习(四)——多变量回归_多变量调整模型
- 7天天干些鸟事.自己都拿自己没办法.无奈。_色天天
- 8java switch用法_javaswitch用法
- 9安装labelme时遇到的问题及解决方案_building wheel for pyqt5-sip (pyproject.toml) did
- 10模拟a标签实现下载,文件下载通过Blob对象实现_模拟a链接下载
机器学习(四)——多变量回归_多变量调整模型
赞
踩
多功能
之前探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,构成一个含有多个变量的模型,模型中的特征为(x1,x2,…,xn)。

- 符号定义:
n代表特征的数量
x表示输入变量(或者特征),
y表示输出变量(预测的目标变量),
x^(i)表示第 i个训练实例,是特征矩阵中的第i行,是一个向量(vector)。
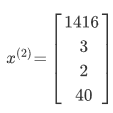
xj^(i)代表特征矩阵中第 i行的第 j个特征,也就是第 i个训练实例的第 j个特征。
支持多变量的假设h表示为:

这个公式中有个n+1个参数和n个变量,为了使得公式能够简化一些,引入x0=1,则公式转化为:
这就是所谓的多元线性回归。(多个特征量或变量来预测y)
多元梯度下降法


多元梯度下降法演练I-特征缩放
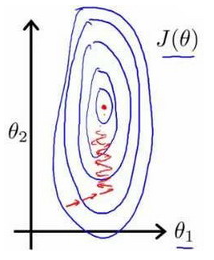
面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,房间数量的值为0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。
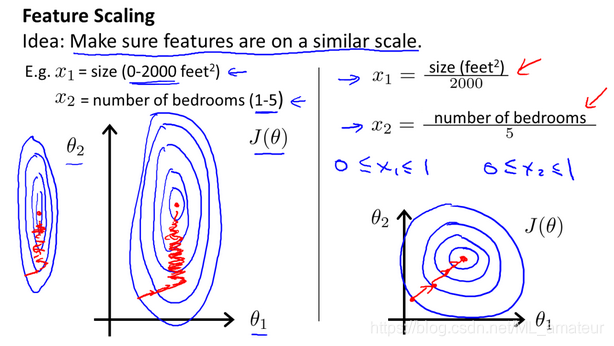
在特征缩放中,有时会进行称为均值归一化的工作。
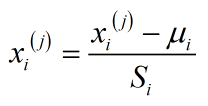
μi是训练集中特征xi(j)的平均值avg(xi);Si是该特征值的范围,表示为max(xi)-min(xi),也可以把它设置为标准差。
特征缩放是为了放梯度下降能够运行的更快一点,可以让迭代的次数更少一点。
多元梯度下降法II—学习率
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。
梯度下降法中需要认真解决的:
(1)如何确保梯度下降能够正确的进行
(2)如何选择学习率α
梯度下降法的正确执行过程:
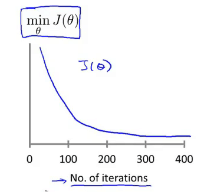
可以通过这样的图像来判断梯度下降是否已经收敛。
自动收敛测试:如果代价函数J(θ)一步迭代后的下降小于一个很小的值ε(例如0.001),这个测试就判断函数已经收敛,但是选择这样的阈值ε是非常困难的。
通过上述图像可以判断如何选择学习率α:
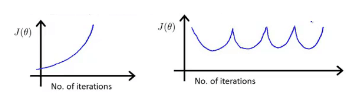
如图,意味着需要选择较小的α。只要选择较小的α,那么每次迭代之后的代价函数J(θ)都会下降。
- 总结:
(1)如果α太小,梯度下降法会收敛缓慢,达到收敛所需的迭代次数会非常高;
(2)如果α太大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试一系列学习率值:…,0.001,0.003,0.01,0.03,0.1,0.3,1,…
特征和多项式回归
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型
或者三次方模型。
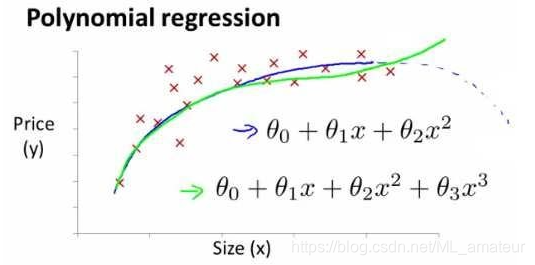
根据函数图形特性,我们还可以使:
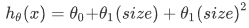
或
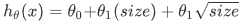
注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
正规方程(区别于迭代方法的直接解法)
到目前为止一直是用的梯度下降法来最小化代价函数,通过多次迭代收敛,找到局部最优值。相反的,正规方程提供了一种求θ的解析解法,可以不需要通过迭代一次性求得解,一步得到最优值。
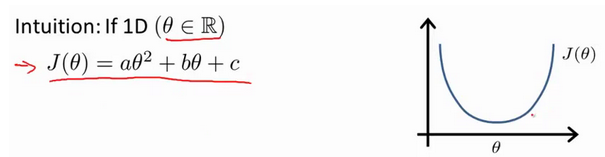
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
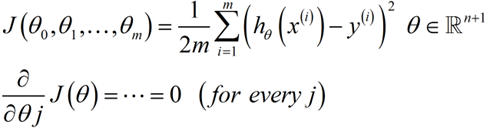
假设我们的训练集特征矩阵为 X(包含了x0=1 ),训练集结果为向量 y,则利用正规方程解出向量
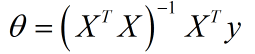
在 Octave 中,正规方程写作:

X’表示X的转置,pinv是用来计算逆矩阵的函数。
梯度下降与正规方程的比较:

如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为0(n^(3)),通常来说当n小于10000 时还是可以接受的。
对于这个特定的线性回归模型,标正规方程法是一个比梯度下降法更快的替代算法。
随着学习算法越来越复杂,例如,分类算法,像逻辑回归算法,我们会看到,实际上对于那些算法,正规方程法并不适用,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。
正规方程的python实现:

正规方程在矩阵不可逆情况下的解决方法

1.看特征值里是否有一些多余的特征,如x1和x2是线性相关的,互为线性函数。
2.当有一些多余的特征时,可以采取减少特征量和使用正规化方式来改善。
在Octave里,有pinv和inv两种方法用来求矩阵的逆,但一个求得是伪逆,另一个求得是逆。即使的X‘X结果是不可逆的,但pinv算法执行的结果是正确的。

