
热门标签
热门文章
- 1百趣代谢组学文献分享:茶褐素可促进胆固醇降解_茶褐素 溶解脂肪 实验
- 2Java面试干货:关于数组查找的几个常用实现算法_.java有序数组查找
- 3RocketMQ与Kafka对比_jetmq
- 4Win11+WSL2+Ubuntu-20.04+GPU+TensorFlow+Jupyter_在win11上配置wsl2和ubuntu22.04和gpu驱动
- 5SpringCloud-Eureka(一)_eureka 安装
- 6腾讯面试官:说说Android的UI刷新机制?,211本硕如何通过字节跳动、百度、美团Android面试
- 7STM32使用HAL库点亮流水灯_hal库点灯
- 8【Rust日报】2021-01-15 Nightly的Reference已上线Const Generics的文档
- 9有哪些Linux可以替代centerOS的_替代centos
- 10清北复交人浙南 计算机交叉学科项目大盘点!_计算机本科加法学硕士清华
当前位置: article > 正文
python爬取新闻存入数据库_python爬取数据存入数据库
作者:黑客灵魂 | 2024-07-30 04:44:17
赞
踩
python爬取新闻保存在数据库
昨天本来写了一篇关于python爬取的文章,结果没通过,正好今天一起吧。用python同时实现爬取,和存入数据库,算是复习一下前面操作数据库的知识。

1、准备工作
既然是爬取,那自然要连接到爬取的页面,所以需要requests库。而爬取完成之后,还需要解析网页,因而也要导入BeautifulSoup库。
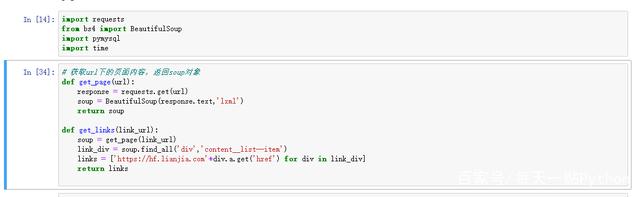
因为后面要将数据存入数据库,所以这里也一并引入了pymysql库,而这个time库呢,主要就是用来间隔时间,不然太快爬取需要爬取的页面,可能会崩溃,后面代码会提到。
注:在用到推导式的时候,我拼接了一个字符串,这是因为爬取的页面地址是相对路径,后面会报错,所以拼接了一串连接头,变成绝对路径了。
2、继续下一步
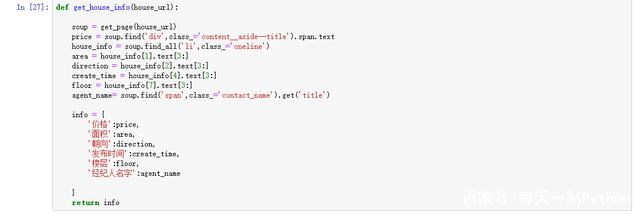
这段代码,主要就是根据标签来获取需要的信息。
3、数据库的基本操作
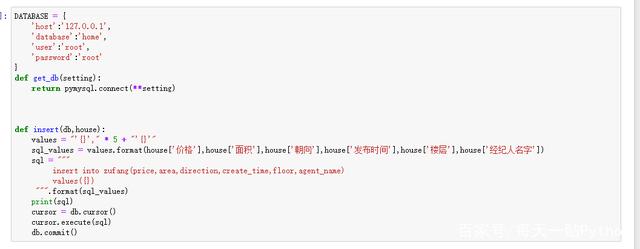
这里算是对前面写过的数据库的复习,因为插入的字段可能有点多,所以采用了三引号。
4、开始爬取
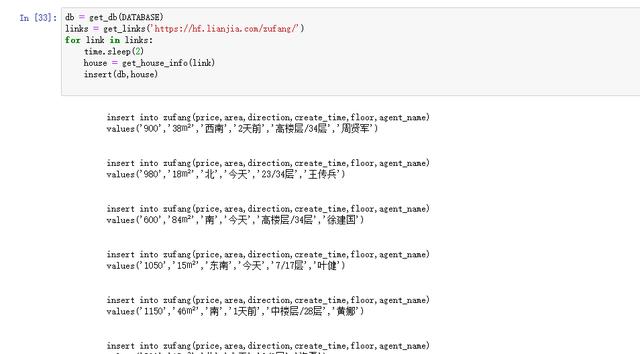
这里只截取了一部分爬取的信息,前边提到的time库用到了,在这段代码主要就是间隔2秒获取一下信息。
5、命令行和navicat的数据显示
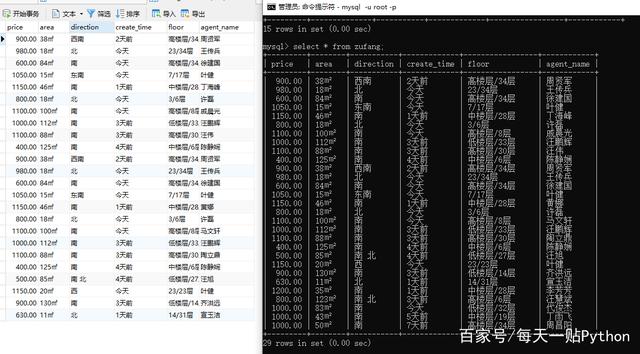
当然因为提前中断了爬取的代码命令,所以插入数据库的只有这么多数据。
以上代码都可以直接输入执行,没有任何错误,大家可以实际操作一遍,这样对python的爬取和数据库的操作会更熟练一点。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/902008
推荐阅读
- b站视频下载 ...
赞
踩
相关标签

