
热门标签
热门文章
- 1深入剖析—【服务器硬件】与【Nginx配置】:从基础到实战_nginx服务器对内存的要求
- 2oracle硬盘亮黄灯,RH2288H V3服务器硬盘亮黄灯故障处理案例
- 3使用SpringBoot进行微服务熔断与降级
- 4字节跳动简历冷却期_【字节跳动招聘】简历这样写,才不会被秒拒
- 5Oracle超级详细的安装教程及遇到的问题解决方案【完整版】_pdps16.0安装
- 6数据结构(四)二叉树基础知识归纳_在树的结构中,谁有且仅有一个父节点
- 7ElasticSearch基础:从倒排索引说起,快速认知ES_es中的索引和倒排索引有什么关系
- 8微软浏览器连不上网络
- 9Android 开发必备 - Java知识点总结_学习安卓编程要java的哪些知识点
- 10网页原型设计_网站原型是以下哪层设计的结
当前位置: article > 正文
NLTK词性标注、命名实体识别、依存句法分析调用_nltk命名实体识别
作者:黑客灵魂 | 2024-06-25 23:41:55
赞
踩
nltk命名实体识别
首先,肯定还是先下载nltk
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple此时,如果坚持运行nltk一般是会出现报错的
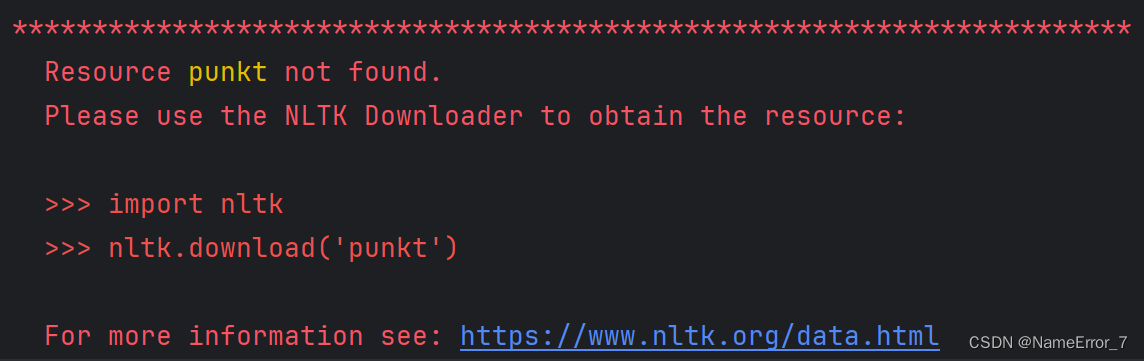 这是因为光在pip下载nltk还不足以支持其具体功能的运行,需要再下载对应资源,本图报错中就提醒我们下载punkt。
这是因为光在pip下载nltk还不足以支持其具体功能的运行,需要再下载对应资源,本图报错中就提醒我们下载punkt。
然而,按照报错提示去下载总是会因为网络问题而要么非常慢,要么下不了的,所以建议去nltk官网NLTK Data进行下载,会慢一点,但多半能成功。
下载完对应资源之后,将对应资源解压放到报错中返回的路径中的任意一个就可以了(注意:你的电脑本身可能不带有nltk_data文件夹,此时只要自己创建一个,然后把资源放进去就可以了)
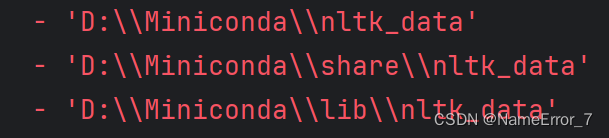
其中,请注意各资源需要放在nltk_data不同的子文件夹下,本文所要用到的各子文件夹的资源有:
chunkers/maxent_ne_chunker、corpora/treebank、corpora/words、taggers/averaged_perceptron_tagger、tokenizers/punkt(一般来说子文件夹也是需要自己创建的)
然后就可以开始调试具体代码了。
命名实体识别代码如下:
- import nltk
- sentence = """Replace with your own sentence here."""
- tokens = nltk.word_tokenize(sentence)
- tagged = nltk.pos_tag(tokens)
- entities = nltk.chunk.ne_chunk(tagged)
- print(entities)
依存句法分析代码如下:
- import nltk
- sentence = 'He is a student'
- words = nltk.word_tokenize(sentence)
- sent_tag = nltk.pos_tag(words)
- grammar = 'NP: {<DT>?<JJ>*<NN>}'
- cp = nltk.RegexpParser(grammar)
- result = cp.parse(sent_tag)
- print(result)
- result.draw()
这里其实我还没搞懂具体语法结构应该怎么写,也就是grammar应该怎么赋值,所以建议写和这里sentence一样的语法结构的句子以保证返回结果能够理想
词性标注代码如下:
- from nltk.tokenize import word_tokenize
- from nltk.tag import pos_tag
- sentence = "Replace with your sentence here."
- tokens = word_tokenize(sentence)
- tagged = pos_tag(tokens)
- print(tagged)
具体要用到的nltk_data数据包我稍后试试能不能直接上传csdn
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/757760
推荐阅读

相关标签

