
热门标签
热门文章
- 1mysql-Util
- 2Python的五种常见算法,一文解读,清晰易懂~_python 算法
- 3.NET_web前端框架_layui_栅格布局
- 4【LeetCode每日一题】——623.在二叉树中增加一行
- 5Linux(centos7)部署hadoop集群,腾讯T2大牛亲自教你_centos7 部署hadoop
- 6MySQL索引的性能优化
- 7vscode配置eslint,实现文件保存使用eslint格式化,问题1.扩展名‘eslint‘被配置为格式化程序,但它无法格式化’JavaScript‘文件。2.eslint命令无法执行_vscode eslint
- 8flink中文文档-快速开始 安装部署_flink 中文
- 9Java 实体转Json Json转实体 String转Json Sting转JSONObject Sting转JSONArray_java 实体类转json
- 10【数据结构】二叉树(二)遍历
当前位置: article > 正文
基于lstm与cnn的文本分类_lstm-cnn文本分类
作者:黑客灵魂 | 2024-08-22 09:27:05
赞
踩
lstm-cnn文本分类
主要内容
本文主要任务是基于文本信息进行用户评价分类,分为两类(即正面情绪和负面情绪)数据样例如下:

项目目录与地址
本文使用的数据有
停顿词(hit_stopwords.txt)来源:
停顿词项目目录预览 - stopwords - GitCode
data目录下的所有数据来源:
项目首页 - chinese_text_cnn - GitCode
所有项目代码地址:
text_classificationWithLSTM: 基于lstm与cnn的文本分类 (gitee.com)
一:数据预处理data_set.py
首先对所获取的数据进行停顿词处理,利用hit_stopwords.txt来进行清洗掉停顿词,对于一些去掉停顿词只剩空格或者符号无效内容的进行删掉,最后生成训练模型所需要的train.txt和test.txt
- import pandas as pd
- import jieba
-
-
- # 数据读取
- def load_tsv(file_path):
- data = pd.read_csv(file_path, sep='\t')
- data_x = data.iloc[:, -1]
- data_y = data.iloc[:, 1]
- return data_x, data_y
-
-
- with open('./hit_stopwords.txt', 'r', encoding='UTF8') as f:
- stop_words = [word.strip() for word in f.readlines()]
- print('Successfully')
-
-
- def drop_stopword(datas):
- for data in datas:
- for word in data:
- if word in stop_words:
- data.remove(word)
- return datas
-
-
- def save_data(datax, path):
- with open(path, 'w', encoding="UTF8") as f:
- for lines in datax:
- for i, line in enumerate(lines):
- f.write(str(line))
- # 如果不是最后一行,就添加一个逗号
- if i != len(lines) - 1:
- f.write(',')
- f.write('\n')
-
-
- if __name__ == '__main__':
- train_x, train_y = load_tsv("./data/train.tsv")
- test_x, test_y = load_tsv("./data/test.tsv")
- train_x = [list(jieba.cut(x)) for x in train_x]
- test_x = [list(jieba.cut(x)) for x in test_x]
- train_x = drop_stopword(train_x)
- test_x = drop_stopword(test_x)
- save_data(train_x, './train.txt')
- save_data(test_x, './test.txt')
- print('Successfully')

二:lstm模型训练
- import pandas as pd
- import torch
- from torch import nn
- import jieba
- from gensim.models import Word2Vec
- import numpy as np
- from data_set import load_tsv
- from torch.utils.data import DataLoader, TensorDataset
-
-
- # 数据读取
- def load_txt(path):
- with open(path, 'r', encoding='utf-8') as f:
- data = [[line.strip()] for line in f.readlines()]
- return data
-
- train_x = load_txt('train.txt')
- test_x = load_txt('test.txt')
- train = train_x + test_x
- X_all = [i for x in train for i in x]
-
- _, train_y = load_tsv("./data/train.tsv")
- _, test_y = load_tsv("./data/test.tsv")
- # 训练Word2Vec模型
- word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)
-
- # 将文本转换为Word2Vec向量表示
- def text_to_vector(text):
- vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv] # 将每个词转换为 Word2Vec 向量
- return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_size # 计算平均向量
-
- X_train_w2v = [[text_to_vector(text)] for line in train_x for text in line] # 训练集文本转换为 Word2Vec 向量
- X_test_w2v = [[text_to_vector(text)] for line in test_x for text in line]
-
- # 将词向量转换为PyTorch张量
- X_train_array = np.array(X_train_w2v, dtype=np.float32) # 将训练集词向量转换为 NumPy 数组
- X_train_tensor = torch.Tensor(X_train_array) # 将 NumPy 数组转换为 PyTorch 张量
- X_test_array = np.array(X_test_w2v, dtype=np.float32) # 将测试集词向量转换为 NumPy 数组
- X_test_tensor = torch.Tensor(X_test_array) # 将 NumPy 数组转换为 PyTorch 张量
-
- # 使用DataLoader打包文件
- train_dataset = TensorDataset(X_train_tensor, torch.LongTensor(train_y)) # 构建训练集数据集对象
- train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 构建训练集数据加载器
- test_dataset = TensorDataset(X_test_tensor, torch.LongTensor(test_y)) # 构建测试集数据集对象
- test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True) # 构建测试集数据加载器
-
-
- # 定义LSTM模型
- class LSTMModel(nn.Module):
- def __init__(self, input_size, hidden_size, output_size):
- super(LSTMModel, self).__init__()
- self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
- self.fc = nn.Linear(hidden_size, output_size)
-
- def forward(self, x):
- lstm_out, _ = self.lstm(x)
- output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出
- return output
-
-
- # 定义模型
- input_size = word2vec_model.vector_size
- hidden_size = 50 # 隐藏层大小
- output_size = 2 # 输出的大小,根据你的任务而定
-
- model = LSTMModel(input_size, hidden_size, output_size)
- # 定义损失函数和优化器
- criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
- optimizer = torch.optim.Adam(model.parameters(), lr=0.0002) # Adam 优化器
-
- if __name__ == "__main__":
- # 训练模型
- num_epochs = 100 # 迭代次数
- log_interval = 100 # 每隔100个批次输出一次日志
- loss_min = 100
- for epoch in range(num_epochs):
- model.train() # 设置模型为训练模式
- for batch_idx, (data, target) in enumerate(train_loader):
- outputs = model(data) # 模型前向传播
- loss = criterion(outputs, target) # 计算损失
-
- optimizer.zero_grad() # 梯度清零
- loss.backward() # 反向传播
- optimizer.step() # 更新参数
-
- if batch_idx % log_interval == 0:
- print('Epoch [{}/{}], Batch [{}/{}], Loss: {:.4f}'.format(
- epoch + 1, num_epochs, batch_idx, len(train_loader), loss.item()))
- # 保存最佳模型
- if loss.item() < loss_min:
- loss_min = loss.item()
- torch.save(model, 'lstm_model.pth')
-
- # 模型评估
- with torch.no_grad():
- model.eval()
- correct = 0
- total = 0
- for data, target in test_loader:
- outputs = model(data)
- _, predicted = torch.max(outputs.data, 1)
- total += target.size(0)
- correct += (predicted == target).sum().item()
-
- accuracy = correct / total
- print('Test Accuracy: {:.2%}'.format(accuracy))
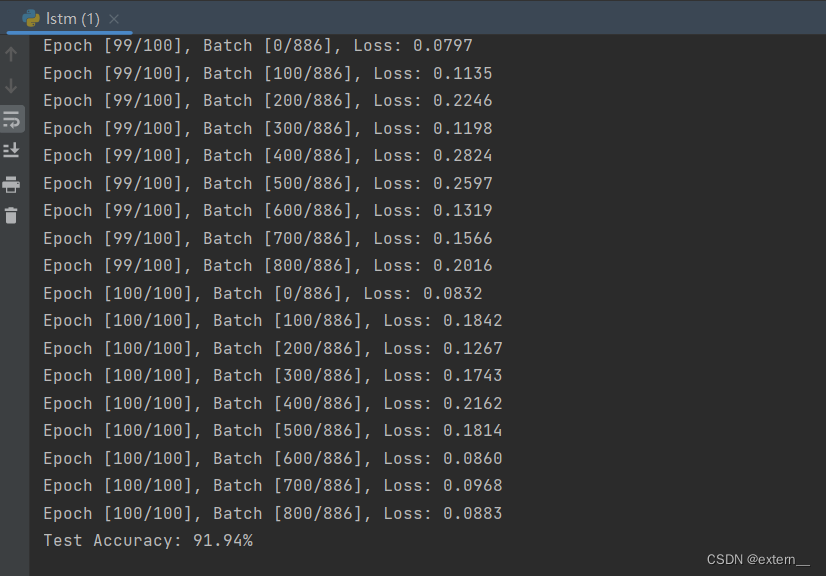
运行完截图
三:cnn模型训练
- import pandas as pd
- import torch
- from torch import nn
- import jieba
- from gensim.models import Word2Vec
- import numpy as np
- from data_set import load_tsv
- from torch.utils.data import DataLoader, TensorDataset
-
-
- # 数据读取
- def load_txt(path):
- with open(path, 'r', encoding='utf-8') as f:
- data = [[line.strip()] for line in f.readlines()]
- return data
-
- train_x = load_txt('train.txt')
- test_x = load_txt('test.txt')
- train = train_x + test_x
- X_all = [i for x in train for i in x]
-
- _, train_y = load_tsv("./data/train.tsv")
- _, test_y = load_tsv("./data/test.tsv")
- # 训练Word2Vec模型
- word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)
-
-
- # 将文本转换为Word2Vec向量表示
- def text_to_vector(text):
- vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
- return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_size
-
-
- X_train_w2v = [[text_to_vector(text)] for line in train_x for text in line]
- X_test_w2v = [[text_to_vector(text)] for line in test_x for text in line]
-
- # 将词向量转换为PyTorch张量
- X_train_array = np.array(X_train_w2v, dtype=np.float32)
- X_train_tensor = torch.Tensor(X_train_array)
- X_test_array = np.array(X_test_w2v, dtype=np.float32)
- X_test_tensor = torch.Tensor(X_test_array)
- # 使用DataLoader打包文件
- train_dataset = TensorDataset(X_train_tensor, torch.LongTensor(train_y))
- train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
- test_dataset = TensorDataset(X_test_tensor, torch.LongTensor(test_y))
- test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
-
-
- # 定义cnn模型
- class CNNModel(nn.Module):
- def __init__(self, input_size, output_size):
- super(CNNModel, self).__init__()
- self.conv1 = nn.Conv1d(input_size, 32, kernel_size=3, padding=1) # 第一个一维卷积层
- self.conv2 = nn.Conv1d(32, 64, kernel_size=3, padding=1) # 第二个一维卷积层
- self.fc = nn.Linear(64, output_size) # 全连接层
-
- def forward(self, x):
- x = x.permute(0, 2, 1) # # Conv1d期望输入格式为(batch_size, channels, sequence_length)
- x = torch.relu(self.conv1(x)) # 第一个卷积层的激活函数
- x = torch.relu(self.conv2(x)) # 第二个卷积层的激活函数
- x = torch.max_pool1d(x, kernel_size=x.size(2)) # 全局最大池化
- x = x.squeeze(2) # 移除最后一个维度
- x = self.fc(x) # 全连接层
- return x
-
-
- # 定义CNN模型、损失函数和优化器
- input_size = word2vec_model.vector_size # 输入大小为 Word2Vec 向量大小
- output_size = 2 # 输出大小
- cnn_model = CNNModel(input_size, output_size) # 创建 CNN 模型对象
- criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
- optimizer = torch.optim.Adam(cnn_model.parameters(), lr=0.0002) # Adam 优化器
-
- if __name__ == "__main__":
- # 训练和评估
- num_epochs = 100 # 迭代次数
- log_interval = 100 # 日志打印间隔
- loss_min = 100 # 最小损失值
- for epoch in range(num_epochs):
- cnn_model.train() # 设置模型为训练模式
- for batch_idx, (data, target) in enumerate(train_loader):
- outputs = cnn_model(data) # 模型前向传播
- loss = criterion(outputs, target) # 计算损失
-
- optimizer.zero_grad() # 梯度清零
- loss.backward() # 反向传播
- optimizer.step() # 更新参数
-
- if batch_idx % log_interval == 0:
- print('Epoch [{}/{}], Batch [{}/{}], Loss: {:.4f}'.format(
- epoch + 1, num_epochs, batch_idx, len(train_loader), loss.item()))
- if loss.item() < loss_min:
- loss_min = loss.item()
- torch.save(cnn_model, 'cnn_model.pth')
-
- # 评估
- with torch.no_grad():
- cnn_model.eval()
- correct = 0
- total = 0
- for data, target in test_loader:
- outputs = cnn_model(data)
- _, predicted = torch.max(outputs.data, 1)
- total += target.size(0)
- correct += (predicted == target).sum().item()
-
- accuracy = correct / total
- print('测试准确率(CNN模型):{:.2%}'.format(accuracy))
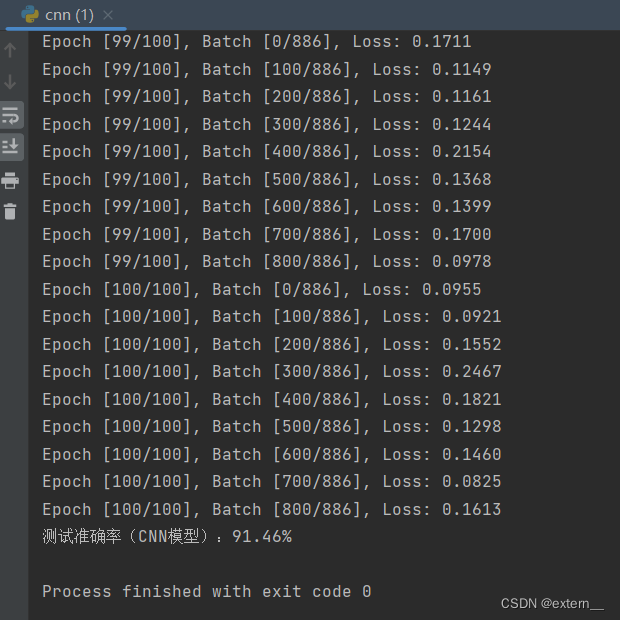
运行完截图:
四:测试模型
- import torch
- import jieba
- from gensim.models import Word2Vec
- import numpy as np
- from lstm import LSTMModel
- from cnn import CNNModel
-
-
-
- # 数据读取
- def load_txt(path):
- with open(path, 'r', encoding='utf-8') as f:
- data = [[line.strip()] for line in f.readlines()]
- return data
-
-
- # 去停用词
- def drop_stopword(datas):
- # 用于预处理文本数据
- with open('./hit_stopwords.txt', 'r', encoding='UTF8') as f:
- stop_words = [word.strip() for word in f.readlines()]
- datas = [x for x in datas if x not in stop_words]
- return datas
-
-
- def preprocess_text(text):
- text = list(jieba.cut(text))
- text = drop_stopword(text)
- return text
-
-
- # 将文本转换为Word2Vec向量表示
- def text_to_vector(text):
- train_x = load_txt('train.txt')
- test_x = load_txt('test.txt')
- train = train_x + test_x
- X_all = [i for x in train for i in x]
- # 训练Word2Vec模型
- word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)
- vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]
- return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_size
-
-
- if __name__ == '__main__':
- user_input = input("Select model:\n1.lstm_model.pth\n2.cnn_model.pth\n")
- if user_input=="1":
- modelName="lstm_model.pth"
- elif user_input=="2":
- modelName="cnn_model.pth"
- else:
- print("no model name is "+user_input)
- exit(0)
- # input_text = "这个车完全就是垃圾,又热又耗油"
- input_text = "回头率还可以,无框门,上档次"
- label = {1: "正面情绪", 0: "负面情绪"}
- model = torch.load(modelName)
- # 预处理输入数据
- input_data = preprocess_text(input_text)
- # 确保输入词向量与模型维度和数据类型相同
- input_data = [[text_to_vector(input_data)]]
- input_arry = np.array(input_data, dtype=np.float32)
- input_tensor = torch.Tensor(input_arry)
- # 将输入数据传入模型
- with torch.no_grad():
- output = model(input_tensor)
- predicted_class = label[torch.argmax(output).item()]
- print(f"predicted_text:{input_text}")
- print(f"模型预测的类别: {predicted_class}")
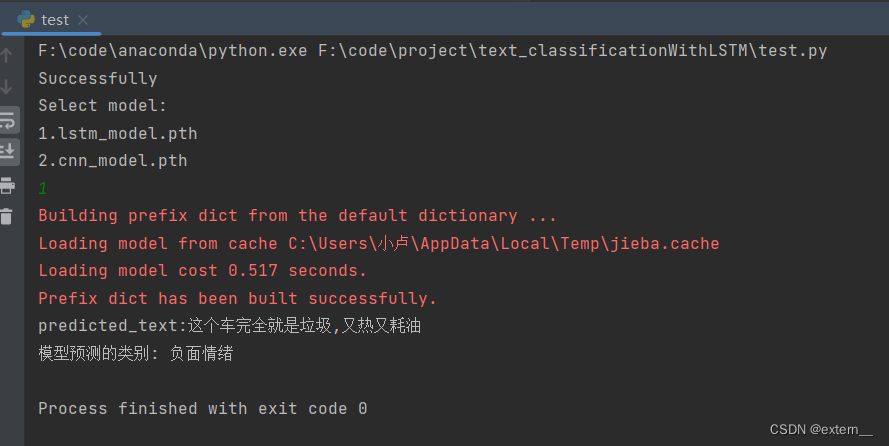
测试截图:

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/黑客灵魂/article/detail/1015687
推荐阅读
相关标签

