
- 1内存计算框架之spark--sparkcore_通用内存计算框架
- 2CSS技巧专栏:一日一例 18 -纯CSS实现背景浮光掠影的按钮特效
- 32022国赛官方评审C题要点_中心对数比变换
- 4分布式消息服务中间价——《RabbitMQ》_消息中间价,2024年最新字节跳动厂内部超高质量Flutter+Kotlin笔记_rabbtmq中间价
- 5Python数据分析入门--层次分析法学习笔记_python层次分析法
- 6万字长文讲解如何优化MySQL,建议收藏!_万字长文带你走进mysql优化(系统层面优化、软件层面优化、sql层面优化)
- 7【kafka2.4.1】kafka增加身份认证_kafka开启认证
- 8RAG开山之作:结合参数化与非参数化记忆的知识密集型NLP任务新解法
- 92024年第三届钉钉杯大学生大数据挑战赛初赛赛题浅析_集成学习:在上述分别对销量及销售金额预测模型的基础上,构建集成学习模型,实现 对
- 10MySQL比较运算符一览表(带解析)和MySQL位运算符_mysql 比较运算符
多视角聚类论文笔记(二)Multi-level Feature Learning for Contrastive Multi-view Clustering(MFLVC)
赞
踩
Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR-2022)
Xu, JieTang, HuayiRen, YazhouPeng, LiangZhu, Xiaofeng
一、解决问题
- 大多数MVC方法都试图通过融合所有视图的特征来发现潜在的聚类模式,然而,与共同语义相比,无意义的视图私有信息可能在特征融合过程中占主导地位,从而影响聚类的质量。
- 一些MVC方法利用潜在特征上的一致性目标来探索所有视图的公共语义。然而他们通常也需要在相同的潜在特征上执行重构目标以避免琐碎的解决方案,这就导致了一致性目标尽可能学习所有视图中具有共同语义的特征,而重构目标希望相同的特征维护单个视图的视图私有信息的冲突。
二、方法
设计一个无融合的MVC模型,以避免在所有视图之间融合不利的视图私有信息;
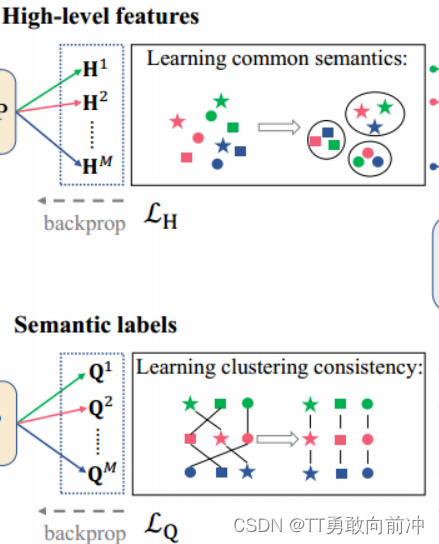
为每个视图中的样本生成不同级别的特征,包括低级特征、高级特征和语义标签/特征;
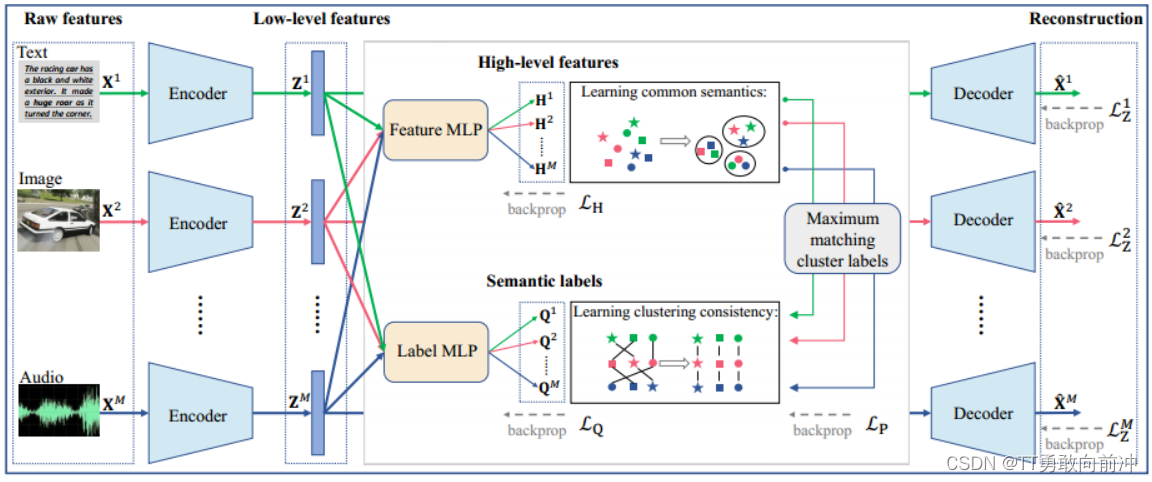
可将模型划分为二个子模块:
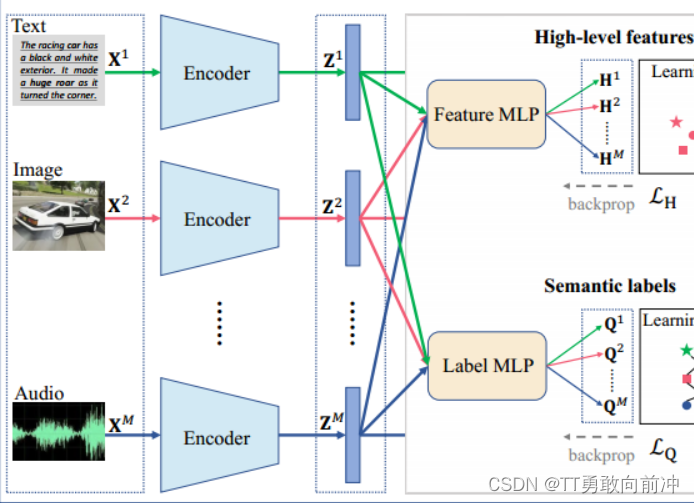
- 该模块的主要工作:
利用自编码器从原始特征中学习低级特征,然后让低级特征分别通过一个Feature MLP 和一个Label MLP,以获得高级特征H和语义标签Q;其中每个MLP由所有视图共享,有助于过滤出视图的私有信息;
两个MLP的设计如下:
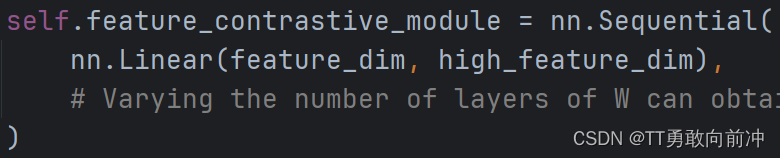
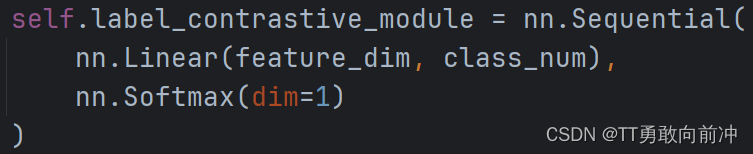
主要区别就是Label MLP在线性层后加了softmax
重构损失函数:
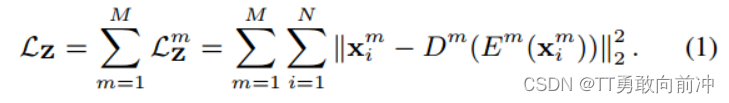
- 该模块的主要工作:
通过对比执行一致性目标通过对比学习来实现:
在高级特征H在进行级对比,以挖掘所有视角视角的共同语义信息。H包含了所有视角的h,不同视角的同一样本(行)视为正样本,其余为负样本,损失函数如下:
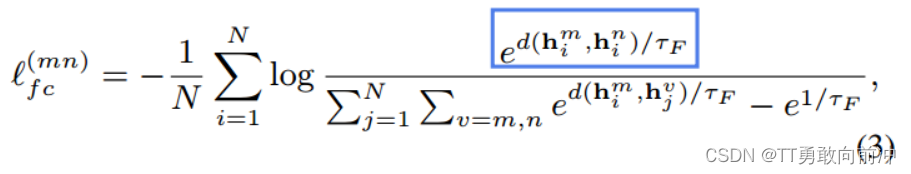
距离度量函数:
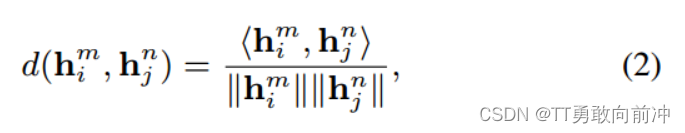
最后再给所有视图的对比损失累加起来:
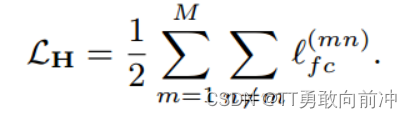
基于所有视图的相同聚类标签表示相同的语义聚类的理论(在视图间,Q的不同列(簇)的分布应该一致),在语义标签Q在进列级对比学习,以学习聚类一致性。Q包含了所有视角的q,不同视角的同一簇(列)视为正样本,其余为负样本,损失函数如下:
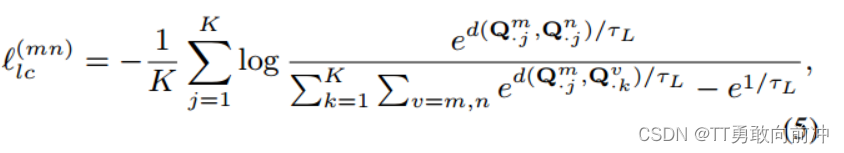
损失函数:
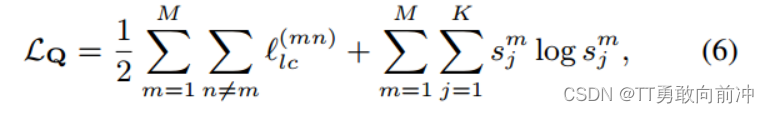
损失函数第一项旨在学习所有视图的聚类一致性,第二项是正则化项,用于避免将所有样本分配到单个聚类中,且:
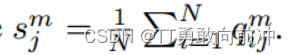
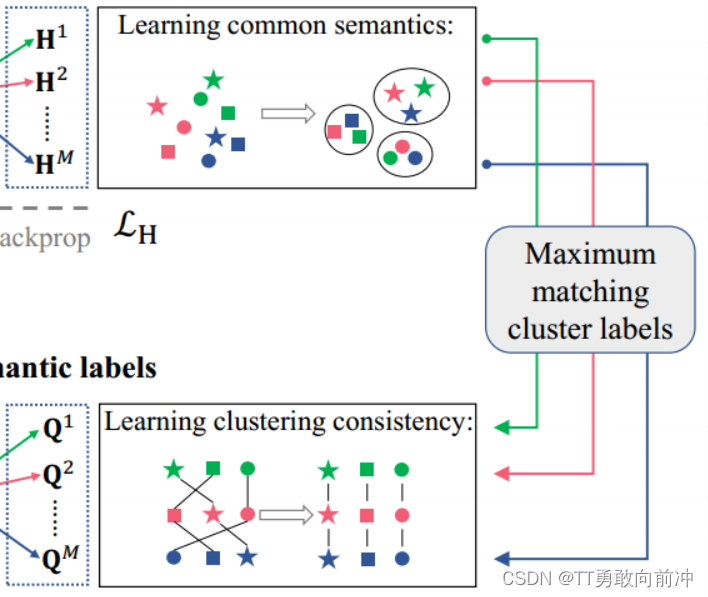
- 该模块的主要工作:
将每个视图的聚类分配Q作为锚点,与每个视图中的高级特征H的聚类进行最大化匹配,以利用高级特征中包含的聚类信息来提高语义标签的聚类效率。匹配操作应该类似于最大二分图匹配,这里我讲不清,就不讲了emmmm......
匹配结束后,就可以通过Q获得最终的聚类结果:
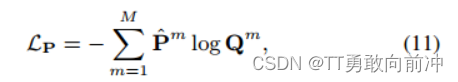
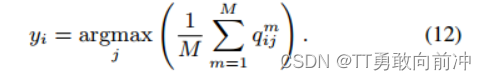
三、损失函数与训练过程

看了论文代码,训练分为三阶段:
- 编码器的预训练(200epochs):L_z
- 在H和Q上的对比学习训练(50epochs) :L_H+L_Q+L_z
- 微调阶段(50epochs):L_P
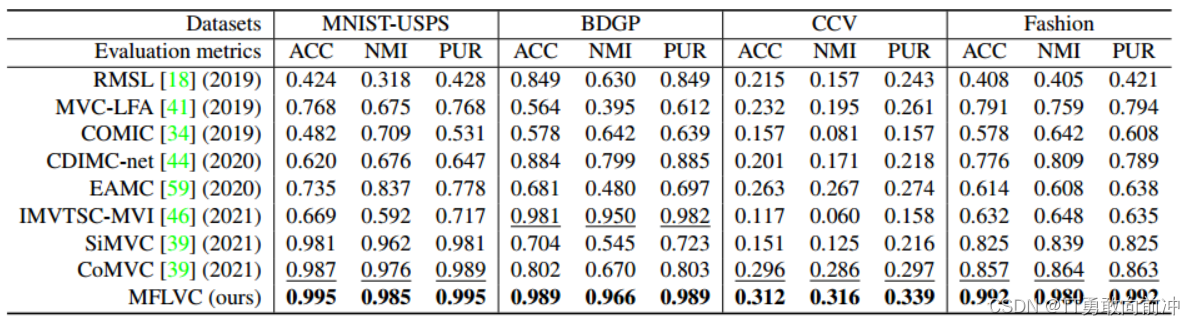
四、实验结果
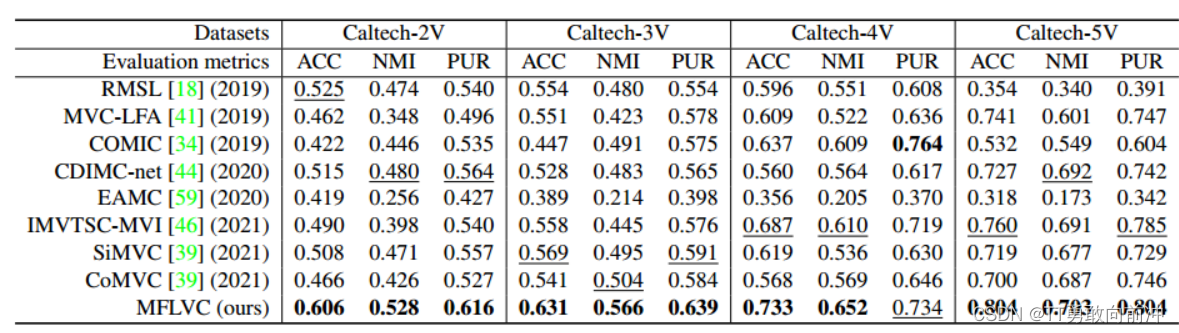
五、收获
- 通过对低维特征空间的分层次映射,可以实现无融合聚类;
- 避免在同一特征空间上进行重构和执行一致性目标;
- 对比学习方式:行级对比和列级对比

