
- 1【git】如何实现规范git commit -m的格式
- 2【蓝桥备赛】星期计算——日期类问题_蓝桥杯星期计算
- 3【AIGC半月报】AIGC大模型启元:2024.07(下)_prover-verifier-games
- 4【路由与交换】基于思科模拟器的路由与交换实训报告(单臂路由、三层交换机实现vlan通信、ospf、rip、dhcp、acl、nat技术总结)
- 5npm下载依赖时的问题_npm依赖下载失败
- 6《C++ Primer Plus》第16章:string类和标准模板库(1)_c++primer plus目录里面有标准库吗
- 7Centos7下安装MySQL详细步骤_centos7安装mysql
- 8动态 SQL ——之—— suffixOverrides & prefix & suffix
- 9探索创新的即时通讯解决方案:IM 项目
- 10每天都在问的“BingAI对话历史”来了_bing ai怎么看过去的查看历史
Transformers 安装与基本使用_transformer安装
赞
踩
Github
文档
- https://huggingface.co/docs/transformers/index
- https://github.com/huggingface/transformers/blob/main/i18n/README_zh-hans.md
推荐文章
简介
Transformers是一种基于注意力机制(Attention Mechanism)的神经网络模型,广泛应用于自然语言处理(Natural Language Processing)任务中,如机器翻译、文本生成和文本分类等。
传统的序列模型(如循环神经网络)在处理长距离依赖时可能遇到困难,而Transformers通过引入注意力机制来解决这个问题。注意力机制使得模型能够在序列中对不同位置的信息进行加权关注,从而捕捉到全局的上下文信息。
在Transformers中,输入序列首先被分别编码为查询(Query)、键(Key)和值(Value)向量。通过计算查询与键的相似度,得到注意力分数,再将注意力分数与值相乘并加权求和,即可得到最终的上下文表示。这种自注意力机制允许模型在编码器和解码器中自由交换信息,从而更好地处理长距离依赖关系。
Transformer模型的核心组件是多层的自注意力机制和前馈神经网络。它的架构被广泛应用于许多重要的NLP任务,其中最著名的是BERT(Bidirectional Encoder Representations from Transformers),它在多项NLP任务上取得了突破性的性能。
除了NLP领域,Transformers模型也被应用于计算机视觉和其他领域,用于处理序列建模和生成任务。它已经成为深度学习中非常重要和有影响力的模型架构之一。
安装
pip install transformers
# PyTorch(推荐)
pip install 'transformers[torch]'
# TensorFlow 2.0
pip install 'transformers[tf-cpu]'
- 1
- 2
- 3
- 4
- 5
- M1 / ARM 用户在安装 TensorFLow 2.0 之前,需要安装以下内容
brew install cmake
brew install pkg-config
- 1
- 2
- 验证是否安装成功
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
- 1
注意: 以上验证操作需要“连网”,否则因无法下载文件而出现报错。
官方示例
from transformers import pipeline
# 使用情绪分析流水线
classifier = pipeline('sentiment-analysis')
classifier('We are very happy to introduce pipeline to the transformers repository.')
- 1
- 2
- 3
- 4
- 5
- 输出结果
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
- 1
中文情感分析模型
中文的RoBERTa-wwm-ext-base在数个情感分析任务微调后的版本
git clone https://huggingface.co/IDEA-CCNL/Erlangshen-Roberta-110M-Sentiment
- 1
from transformers import BertForSequenceClassification, BertTokenizer
import torch
# 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('Erlangshen-Roberta-110M-Sentiment')
model = BertForSequenceClassification.from_pretrained('Erlangshen-Roberta-110M-Sentiment')
# 待分类的文本
text = '今天心情不好'
# 对文本进行编码并转换为张量,然后输入模型中
input_ids = torch.tensor([tokenizer.encode(text)])
output = model(input_ids)
# 对输出的logits进行softmax处理,得到分类概率
probabilities = torch.nn.functional.softmax(output.logits, dim=-1)
# 打印输出分类概率
print(probabilities)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 输出
tensor([[0.9551, 0.0449]], grad_fn=<SoftmaxBackward0>)
- 1
from transformers import pipeline
# 使用pipeline函数加载预训练的情感分析模型,并进行情感分析
classifier = pipeline("sentiment-analysis", model="Erlangshen-Roberta-110M-Sentiment")
# 对输入文本进行情感分析
result = classifier("今天心情很好")
# 打印输出结果
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 输出
[{'label': 'Positive', 'score': 0.9374911785125732}]
- 1
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
# 加载预训练模型和分词器
model_path = "Erlangshen-Roberta-110M-Sentiment"
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 创建情感分析的pipeline
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
# 对文本进行情感分析
result = classifier("今天心情很好")
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 输出
[{'label': 'Positive', 'score': 0.9374911785125732}]
- 1
分词器 Tokenizer
from transformers import AutoTokenizer
# 加载预训练模型的分词器
tokenizer = AutoTokenizer.from_pretrained("Erlangshen-Roberta-110M-Sentiment")
# 对文本进行编码
encoded_input = tokenizer("今天心情很好")
print(encoded_input)
# 解码已编码的输入,还原原始文本
decoded_input = tokenizer.decode(encoded_input["input_ids"])
print(decoded_input)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 输出
{'input_ids': [101, 791, 1921, 2552, 2658, 2523, 1962, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
[CLS] 今 天 心 情 很 好 [SEP]
- 1
- 2
- 3
- 4
填充 Padding
模型的输入需要具有统一的形状(shape)。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Erlangshen-Roberta-110M-Sentiment")
batch_sentences = ["今天天气真好", "今天天气真好,适合出游"]
encoded_inputs = tokenizer(batch_sentences, padding=True)
print(encoded_inputs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 输出
{'input_ids': [
[101, 791, 1921, 1921, 3698, 4696, 1962, 102, 0, 0, 0, 0, 0],
[101, 791, 1921, 1921, 3698, 4696, 1962, 8024, 6844, 1394, 1139, 3952, 102]],
'token_type_ids': [
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
],
'attention_mask': [
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
]}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
截断 Truncation
句子模型无法处理,可以将句子进行截断。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Erlangshen-Roberta-110M-Sentiment")
batch_sentences = ["今天天气真好", "今天天气真好,适合出游"]
# return_tensors pt(PyTorch模型) tf(TensorFlow模型)
encoded_inputs = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_inputs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 输出
{'input_ids': tensor([
[ 101, 791, 1921, 1921, 3698, 4696, 1962, 102, 0, 0, 0, 0, 0],
[ 101, 791, 1921, 1921, 3698, 4696, 1962, 8024, 6844, 1394, 1139, 3952, 102]
]),
'token_type_ids': tensor([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
])
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
google-t5/t5-small
Google的T5(Text-To-Text Transfer Transformer)是由Google Research开发的一种多功能的基于Transformer的模型。T5-small是T5模型的一个较小的变体,专为涉及自然语言理解和生成任务而设计。
-
Transformer架构:与其它模型类似,T5-small采用了Transformer架构,该架构在各种自然语言处理(NLP)任务中表现出色。
-
多功能性:T5-small的设计理念是将所有的NLP任务都看作文本到文本的转换问题,使得模型可以通过简单地调整输入和输出来适应不同的任务。
-
预训练和微调:T5-small通常通过大规模的无监督预训练来学习通用的语言表示,然后通过有监督的微调来适应特定任务,如问答、摘要生成等。
-
应用广泛:由于其灵活性和性能,在各种NLP应用中都有广泛的应用,包括机器翻译、文本生成、情感分析等。
- 下载 google-t5/t5-small 模型
# 模型大小 4.49G
git clone https://huggingface.co/google-t5/t5-small
- 1
- 2
- 安装依赖库
pip install 'transformers[torch]'
pip install sentencepiece
- 1
- 2
- 文本生成示例
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Step 1: 加载预训练的T5 tokenizer和模型
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
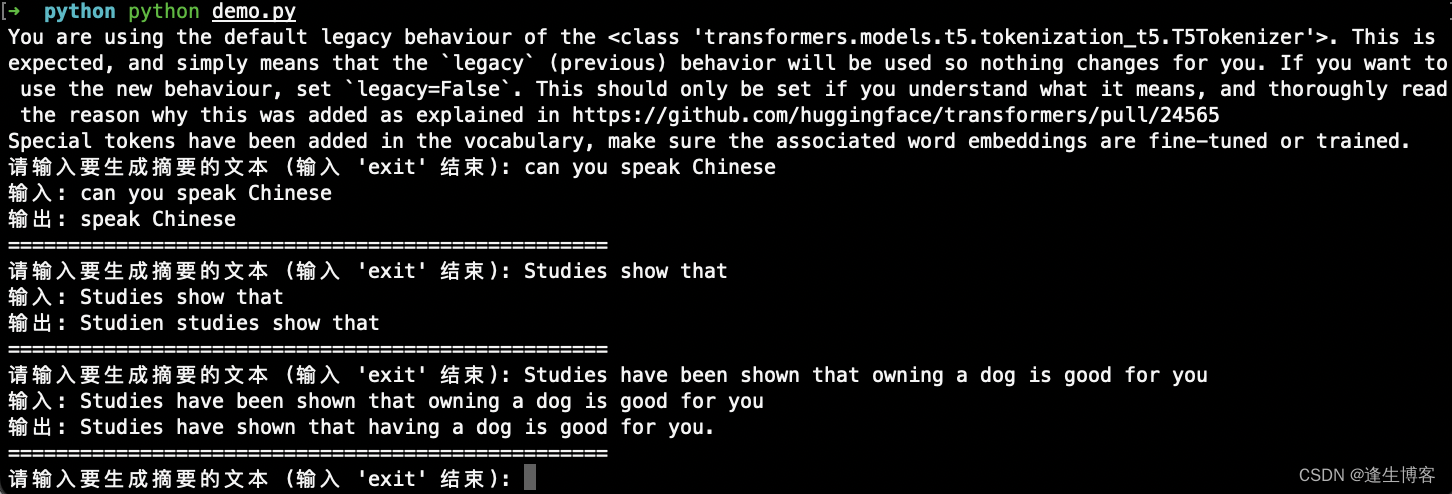
while True:
# Step 2: 接收用户输入
input_text = input("请输入要生成摘要的文本 (输入 'exit' 结束): ")
if input_text.lower() == 'exit':
print("程序结束。")
break
# 使用tokenizer对输入文本进行编码
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
# Step 3: 进行生成
# 使用model.generate来生成文本
output = model.generate(input_ids, max_length=50, num_beams=4, early_stopping=True)
# Step 4: 解码输出
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 打印输入和输出结果
print("输入:", input_text)
print("输出:", output_text)
print("=" * 50) # 分隔符,用来区分不同输入的输出结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
使用脚本进行训练
-
从源代码安装 Transformers
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
- 1
- 2
- 3
- 将当前的 Transformers 克隆切换到特定版本
# 本地分支
git branch
# 远程分支
git branch -a
# 切换分支 v4.41.2,因为当前安装的版本是 v4.41.2
git checkout tags/v4.41.2
- 1
- 2
- 3
- 4
- 5
- 6
- 安装依赖库
# 安装用于处理人类语言数据的工具集库
pip install nltk
# 安装用于计算ROUGE评估指标库
pip install rouge_score
- 1
- 2
- 3
- 4
Pytorch
示例脚本从
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/832054
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

