- 1ofbiz部署异常(一)
- 22023年数维杯C题思路——AI生成文本的智能识别与检测_ai生成文本的智能识别与检测数学模型
- 3毕业设计:基于区块链的物联网设备身份认证与敏感数据访问控制机制设计与实现_区块链数字身份认证论文
- 4一文了解预训练模型 Prompt 调优(比较详细)_prompt优化
- 5大语言模型-基础及拓展应用
- 6微信小程序文件下载及在线打开指定文档,解压Zip格式压缩包_微信小游戏加载的zip包
- 7Linux(CentOs)安装Redis教程_centos redis
- 8Python爬虫教你爬取视频信息_pycharm爬取视频源码
- 9基于YOLO的安全头盔佩戴识别与报警系统及PyQt界面设计(代码和警报仿真)_yolo pyqt
- 10http状态码大全304、201、203等等_203 状态码
Spark 与 Flink 的演进与区别(下)_spark和flink哪个出现时间早
赞
踩
01
批处理与流处理
批处理
所谓的批处理,从字面意思理解,就是把一整块数据切分成一小块一小块,每一个小块称为一批。把一个小块数据分配给一个计算节点进行运算,这种情况称为批处理。
所以说,批处理针对的数据是一个有限集合,也就是有界数据,这些数据在处理之前就已经存储在我们的源数据地址,当我们要进行处理的时候直接从这个数据集进行读取就可以了。
流处理
与批处理相对的,流处理的数据是无界的,数据就像一条河里的水源源不断地从上游流到计算框架中,我们不知道数据的总量是多少,也不知道什么时候结束。更发散来考虑,当雨雪天气,水流可能激增,而干旱时节水流可能枯竭,这就是流处理所应对的情况。
最开始讲过的 Hadoop MapReduce 就是一个批处理计算框架,而 Spark 和 Flink 是混合计算框架,既可以进行批处理计算,也可以进行流处理计算。带着这两个概念,我们来看一下什么是 Flink。
01
什么是 Flink
我们在 Flink 的官网可以看到对 Flink 的精准描述:
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
其实 Flink 的产生时间跟 Spark 差不多,最早出现在 2008 年由柏林理工大学发起的研究项目中,并在 2014 年把代码捐赠给了 Apache 基金会。
同时,Flink 的功能与 Spark 也基本一致,都属于大数据计算框架,那么我们来看一下 Flink 有什么特色。
Flink 的特色
1.数据皆流
在 Flink 的构建思想上,把所有的数据都看作是流式数据,所有的处理方式都是流处理。对于事实上的批数据,只不过当成一种特殊的数据流,我们称之为有界流,也就是说这个流数据有开始有结束,我们可以等着这个流获取完全后统一进行计算。
对于在我们公司中真正的流数据,我们将其称为无界流,这个数据只有开始,没有结束。只要我们的业务还在运转,用户还在浏览我们的 App,查看、下单、支付数据就会源源不断地传送过来。处理这种数据,不光是汇总起来就完事了,很多时候还需要注意数据的顺序,比如说正常情况下肯定是先点击,再下单,最后支付。如果数据的顺序搞错了,已经有了支付,但是没有点击和下单,那这数据计算起来就乱了套了。
我们说 Flink 就是为了流处理而生,自然而然,Flink 的创建者也为流处理做了很多优化。在数据接收方面,Flink 与 Kafka 有异曲同工之妙,都是基于事件驱动的,也就是数据随来随处理,而 Spark 实现的流处理实际上是微批处理,只是把数据块划分的更小。同时,Flink 还有精确的时间控制和状态以保障一致性。
2.多平台支持
同 Spark 一样,Flink 可以作为单独的服务进行部署运行,也可以与 Hadoop、Mesos、Kubernetes 集成部署。
3.高速
同样的,Flink 也使用了内存作为计算的中间缓存。在前面我们已经知道,批处理由于是已经累积下来的数据,所以需要大吞吐量,而流处理是来即处理,需要的是低延迟。在 Flink 中,使用了一种缓存块机制来保障两种计算的速度。当缓存块的超时时间设置为 0,那么只要有数据就立即处理,适合处理无界数据,而当缓存块超时时间设置为无限大,那么就要等着数据结束才处理,这样更适合有界数据。
当然,在具体的工作中,开发人员可以根据业务场景对超时时间进行配置,以获取最佳状态。而这些中间存储,首先是会存在内存中,如果内容不够用再开启磁盘存储。
Flink 的组件架构
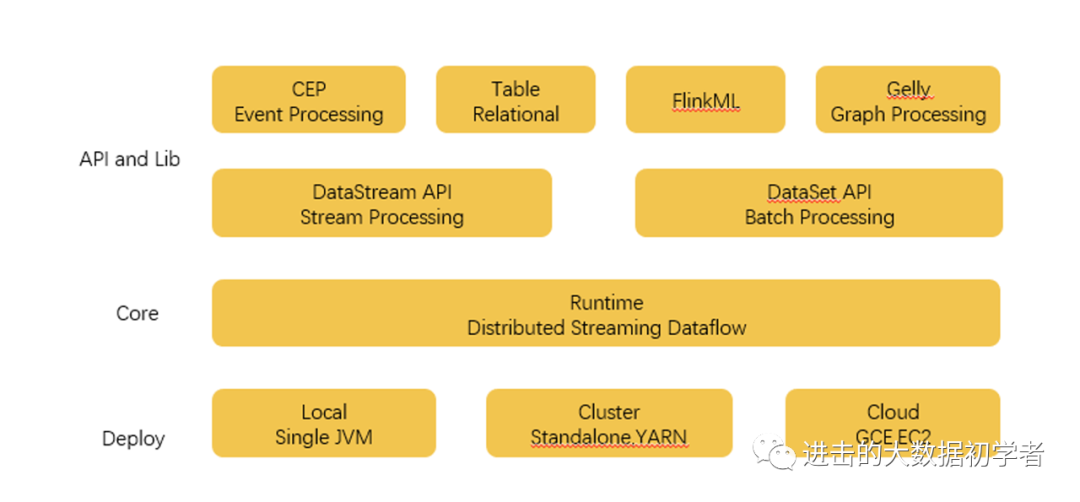
与 Spark 类似,Flink 也实现了用一整套组件来支持整个体系的运转,如上图所示。
最底层是部署相关的组件,包括了支持本地单机部署、集群部署,以及云上部署的组件。
Core 核心层,是 Flink 实现的最关键组件,包括支持分布式的流处理运算,各种分配和调度系统都在这一部分实现,为更上层的 API 提供基础服务,这也为用户的方便使用奠定了基础。
API 和 Lib 层,提供了流处理和批处理计算的各种 API,以及针对特定的计算支持库,比如 FlinkML 就是和 SparkMlib 类似的机器学习库,而 Gelly 是和 GraphX 类似的图处理计算库。
看起来,Flink 与 Spark 似乎是没有什么太大的区别,那么下面我们来总结对比下 Spark 和 Flink。
Spark VS Flink
1.核心实现
在核心实现方面:
Spark 主要使用 Scala 语言编写而成;
而 Flink 早期是使用 Java 进行编写的,但是后期的很多更新也使用了 Scala 语言。
Scala 语言对大数据处理更加友好,但是做程序员的同学都知道,使用什么样的语言来编写程序其实对整个体系架构的影响并不是很大。
2.编程接口
在编程接口方面,Spark 和 Flink 就更加相似了。二者都提供了对各种编程语言的支持,包括 Java、Python、Scala 等,都可以用来编写 Spark 或者 Flink 程序。
3.计算模型
计算模型,或者我们也可以叫作设计理念,这是引发两者前进方向的最大区别点。
前面我们已经介绍过了,Flink 是把所有数据都看作流来进行处理,所以它本身对流式数据有着非常优秀的计算性能,在流计算方面做了大量的优化。
而 Spark 虽然也是混合计算框架,但是 Spark 的设计理念是批处理,也就是所有数据都是批数据。在处理流数据的时候使用了模拟的办法,把数据分割成更小的批来进行处理,从而模拟流式处理,所以在 Spark 中的流处理,我们也可以称为微批处理。所以,Spark 的迭代和优化只能无限接近真流处理,而无法称为真流处理。但是对于 Flink 则没有这样的情况。
有一种说法很妙——“我们可以认为 Flink 选择了‘batch on streaming’的架构,不同于 Spark 选择的‘streaming on batch’架构”。
当然,早期的 Flink 由于针对流处理进行的优化,也使得它在批处理方面仍然没有 Spark 性能良好,这也就引出了我们下面要介绍的流批一体技术。
流批一体
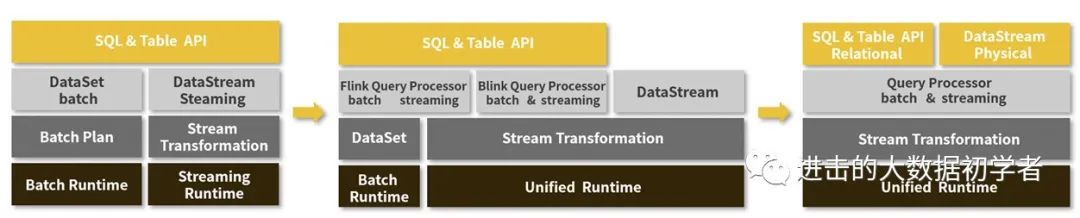
Flink 架构变化图
在 Flink 早期的时候,虽然说在思想上是把批处理当作流处理的一种特殊形式,但是实际上在处理的时候仍然是分开实现的,不管是 API 层还是 Core 层的 Runtime 都没能够实现完全统一。用户在进行流处理和批处理的时候要分别进行程序的编写,非常麻烦。
但是在 Flink 的 1.9 版本,Flink 开始完善流批一体,Flink SQL 率先实现了流批一体语义,使得用户只需学习、使用一套 SQL 就可以进行流批一体的开发,大幅节省开发成本。
但是只调整 SQL API 并不能解决用户的所有需求。一些定制化程度较高,比如需要精细化的操纵状态存储的作业还是需要继续使用 DataStream API。在常见的业务场景中,用户写了一份流计算作业后,一般还会再准备一个离线作业进行历史数据的批量回刷。但是 DataStream 虽然能很好地解决流计算场景的各种需求,但却缺乏对批处理的高效支持。
所以,在最近的两年内,Flink 主打流批一体的升级,从上面的架构图变化我们可以看出来,在最新的 1.11 版本,不管是 SQL 还是 DataStream API,都已经可以使用同一套编写规范,而只需要进行简单的选择就可以进行批处理或者流处理。
阿里巴巴在 2019 年初收购了 Flink 创始公司和团队 Ververica,开始投入更多资源在 Flink 生态和社区上。到了 2020 年,国内外主流科技公司几乎都已经选择了 Flink 作为其实时计算解决方案,我们看到 Flink 已经成为大数据业界实时计算的事实标准,在阿里巴巴公布的迭代计划中,Flink 会支持更加智能的流批融合,甚至是自动切换。
随着流批一体技术的实现,使用 Flink 的公司不再需要维护两套架构,部署两套代码,维护成本会进一步降低,我觉得 Flink 会变得更加普及,甚至是取代 Spark 成为新一代主流计算框架。
总结
在这一讲中,我们介绍了一个与 Spark 极为类似的计算框架 Flink,并将 Flink 与 Spark 进行了对比。你可以看到,Flink 与 Spark 出现时间差不多,所实现的功能也极为类似,但是,由于 Flink 与 Spark 的核心理念的差别,也就是对批处理与流处理的思考不同,使得 Flink 更加符合当前大型互联网公司的需求,尤其是随着流批一体技术的落地,未来谁将获得更多关注,让我们尽情期待吧。
希望大家可以关注下公众号,会定期分享自己从业经历、技术积累及踩坑经验,支持一下,鞠躬感谢~

关注公众号回复:“资料全集”