
- 1Docker切换镜像源_docker 切换镜像源
- 2WebGL2.0从入门到精通-1、前端项目搭建(html+typescript+vite)
- 3webgpu 入门_webgpu教程
- 4如何一键拷贝PPT中的所有文字?
- 5蓝易云:Nginx使用htpasswd配置访问密码教程
- 62024年最新关于分布式爬虫思考_python爬虫不适合分布式的原因,50道面试题
- 7This version of ChromeDriver only supports Chrome version 87
- 8企业微信接入芋道SpringBoot项目_芋道源码微信相关
- 9基于stm32 ONENET物联网接入教程_onenet与stm32
- 10计算机中mac ip地址查询,如何通过mac地址查ip,详细教您Mac怎么查看ip地址
Flinkcdc监测mysql数据库,自定义反序列化,利用flinkApi和flinkSql两种方式_flinkcdc监控mysql
赞
踩
Flink CDC (Flink Change Data Capture)(Flink中改变数据捕获) 是基于数据库的日志 CDC 技术,实现了全增量一体化读取的数据集成框架。搭配Flink计算框架,Flink CDC 可以高效实现海量数据的实时集成。
改变你们的一个误区,cdc只有检测功能,不能对数据库中的数据进行修改删除添加
第一种用FlinkSql实现
第一步:创建FlinkSql环境
- //创建流式环境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //创建流式表环境
- StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
第二步:配置mysql
去mysql中的my.cnf中更改配置,作者的my.cnf是在/etc目录下面的,如果去进行修改可能权限不够
命令:sudo vim /etc/my.cnf
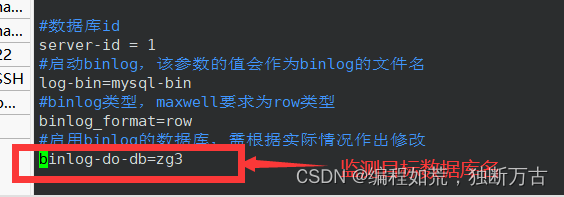
以上图片的四个配置缺一不可,框起来的一定要注意,binlog - do -db=目标数据库名
更改完之后要重启mysql,这一步很重要,否则还是之前的配置
重启命令:sudo systemctl restart mysqld
查看数据库命令:sudo systemctl status mysqld

有箭头指示就表示完成了
第三步:在目标数据库中创建需要检测的表
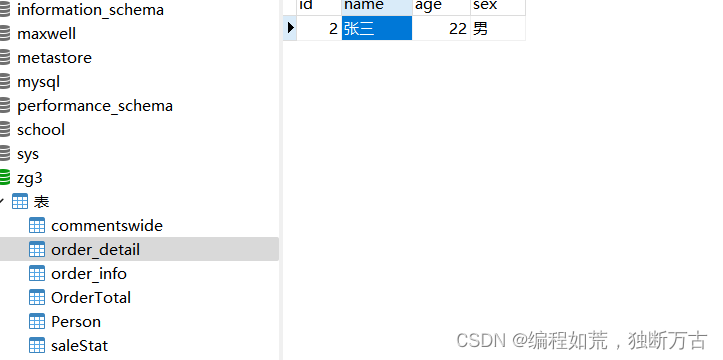
并在表中插入数据
第四步:去flink官网找到连接mysql-cdc的语法格式

上面是我从flink官网上截下来的,我们只需要将官网上的内容复制,自己去修改就可以了
- tEnv.executeSql("CREATE TABLE Person (\n" +
- " id INT,\n"+
- " name STRING,\n" +
- " age BIGINT,\n" +
- " sex String,\n" +
- " PRIMARY KEY (id) NOT ENFORCED\n"+ --一定要加上主键,否则就会报错
- ") WITH (\n" +
- " 'connector' = 'mysql-cdc',\n" + --必填
- " 'hostname'='hadoop102',\n" + --主机名,必填
- " 'port'='3306',\n" + --端口号,必填
- " 'username' = 'root',\n" + --用户名,必填
- " 'password'='123456',\n" + --密码,必填
- " 'database-name'='zg3',\n" + --目标数据库名,必填
- " 'table-name'='Person',\n" + --目标表名,必填
- " 'jdbc.properties.useSSL'='false'\n" + --官网上可以找到,必填
- ");");

以上 是检测mysql中信息改的设置
报错

Caused by: org.apache.flink.table.api.ValidationException: Multiple factories for identifier 'mysql-cdc' that implement 'org.apache.flink.table.factories.DynamicTableFactory' found in the classpath.
如果你报这种错,就要看一下你自己的pom文件
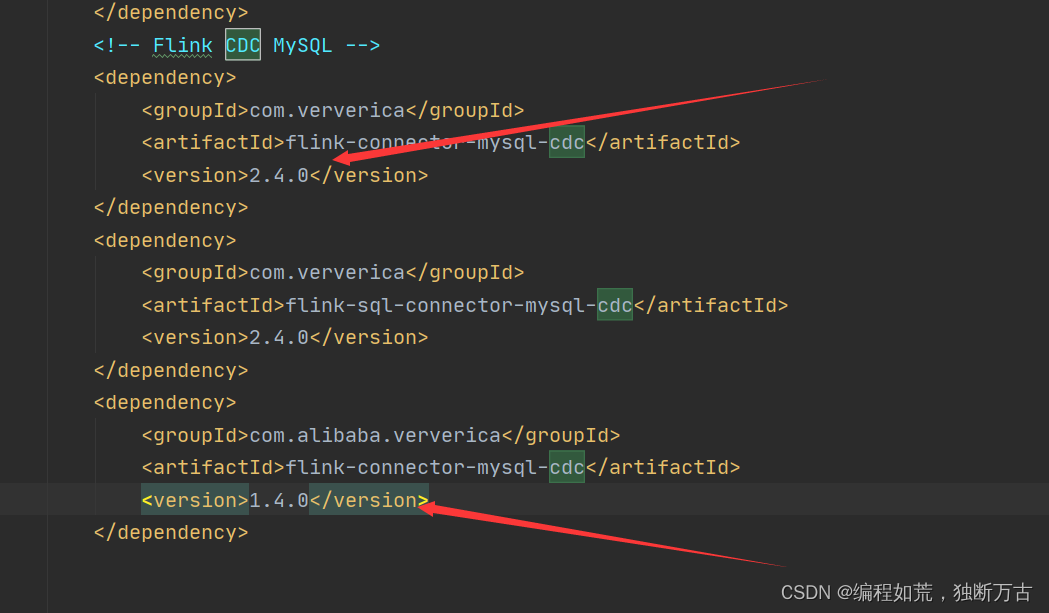
这两个依赖冲突了
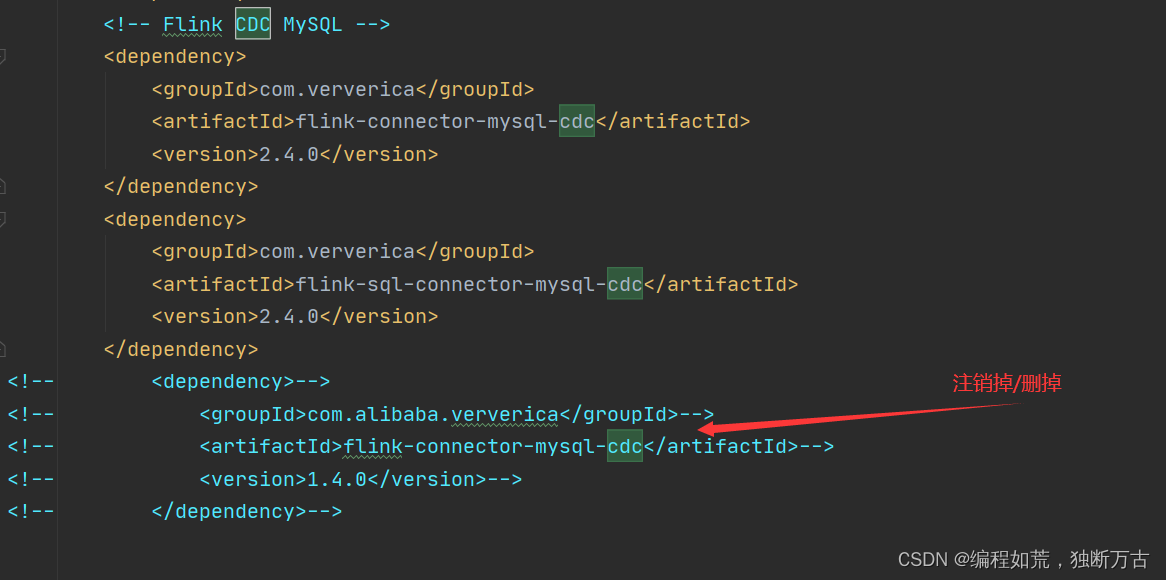
这样就可以解决报错了

对刚才数据进行修改名字
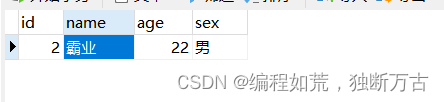

如果修改数据库,但是idea更新不出来值,这可能是好多人电脑的问题

这时候将并行度添加为1就可以了
第五步:将以上数据以json格式传送到kafka中
Debezium-json:是Debezium为变更日志提供的统一格式结构。它是一种特定格式的JSON,用于描述数据库中的变更事件,如插入、更新或删除操作。这些事件可以由Debezium从源数据库捕获,并转换为JSON格式的消息,然后发布到消息队列(如Kafka)或对象存储(如OSS)中

- tEnv.executeSql("CREATE TABLE kfk_cdc (\n" +
- " id INT,\n" +
- " name STRING,\n" +
- " age BIGINT,\n" +
- " sex String,\n" +
- " PRIMARY KEY (id) NOT ENFORCED\n"+
- ") WITH (\n" +
- " 'connector' = 'kafka',\n" +
- " 'topic' = 'mysql_cdc',\n" + --写到kafka的主题,必填
- " 'properties.bootstrap.servers' = 'hadoop102:9092',\n" + --kafka服务器名
- " 'properties.group.id' = 'testGroup',\n" +
- " 'scan.startup.mode' = 'earliest-offset',\n" +
- " 'format' = 'debezium-json'\n" + --日志json格式,必填
- ")");
tEnv.executeSql("insert into kfk_cdc select * from Person");最后将目标表中的数据写到kafka的表中,因为flinksql连接kafka底层会将kafka表中数据自动写到kafka中

可能这样你们看不清,我把json数据美化一下
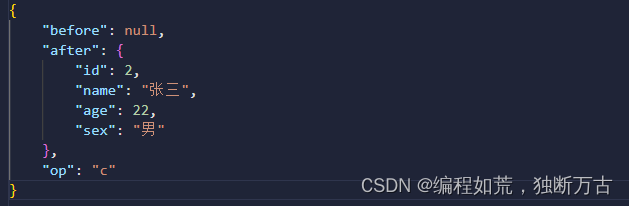
第二种用FlinkApi实现
第二步,第三步和FlinkSql一样
第四步从官网上复制: Overview | Apache Flink CDC

-
-
- //免密配置
- Properties properties = new Properties();
- properties.put("useSSL","false");
- MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
- .hostname("hadoop102") --必填 主机名
- .port(3306) --必填 端口号
- .databaseList("zg3") // set captured database --必填 数据库
- .tableList("zg3.Person")// set captured table --必填 数据表
- .username("root") --必填 用户名
- .password("123456") --必填 密码
- .deserializer(new JsonDebeziumDeserializationSchema()) --反序列化器
- .jdbcProperties(properties) --jdbc配置,用来写免密配置
- .build();
第五步:获取上一步源数据
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- // enable checkpoint
- env.enableCheckpointing(3000);
-
- env
- .fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
- // set 4 parallel source tasks
- .setParallelism(1)
- .print(); // use parallelism 1 for sink to keep message ordering
-
- env.execute("Print MySQL Snapshot + Binlog");

第六步:将数据转化为json格式
第一种:StringDebeziumDeserializationSchema()
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={transaction_id=null, ts_sec=1712331615, file=, pos=0}} ConnectRecord{topic='mysql_binlog_source.zg3.Person', kafkaPartition=null, key=Struct{id=2}, keySchema=Schema{mysql_binlog_source.zg3.Person.Key:STRUCT}, value=Struct{after=Struct{id=2,name=中国,age=22,sex=男},source=Struct{version=1.9.7.Final,connector=mysql,name=mysql_binlog_source,ts_ms=0,db=zg3,table=Person,server_id=0,file=,pos=0,row=0},op=r,ts_ms=1712331615095}, valueSchema=Schema{mysql_binlog_source.zg3.Person.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
- MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
- .hostname("hadoop102")
- .port(3306)
- .databaseList("zg3") // set captured database
- .tableList("zg3.Person")// set captured table
- .username("root")
- .password("123456")
- .deserializer(new StringDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
- .jdbcProperties(properties)
- .build();
第二种: JsonDebeziumDeserializationSchema()
{"before":null,"after":{"id":2,"name":"中国","age":22,"sex":"男"},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source",
"ts_ms":0,"snapshot":"false","db":"zg3","sequence":null,"table":"Person",
"server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},
"op":"r","ts_ms":1712331713335,"transaction":null}
- MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
- .hostname("hadoop102")
- .port(3306)
- .databaseList("zg3") // set captured database
- .tableList("zg3.Person")// set captured table
- .username("root")
- .password("123456")
- .deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
- .jdbcProperties(properties)
- .build();
第二种更加的符合我们日常的json格式
但我们不想其余东西,只想要after、before、database、table 、operation
这时候我们就需要自定义了
- public static class PersonDeserialization implements DebeziumDeserializationSchema <String>{
-
- @Override
- public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
-
- //获取database和table
- String topic = sourceRecord.topic();
- String[] split = topic.split("\\.");
- String database = split[1];
- String table = split[2];
-
- JSONObject data = new JSONObject();
-
- //获取value值
- //获取before值
- Struct value = (Struct) sourceRecord.value();
- Struct before = value.getStruct("before");
- JSONObject beforeData = new JSONObject();
- if(before!=null){
- for (Field field : before.schema().fields()) {
- Object o = before.get(field);
- beforeData.put(field.name(),o);
- }
- }else{
- before=null;
- }
-
- //获取after值
- Struct after = value.getStruct("after");
- JSONObject afterData = new JSONObject();
- for (Field field : after.schema().fields()) {
- Object o = after.get(field);
- afterData.put(field.name(),o);
- }
-
- data.put("before",beforeData);
- data.put("after",afterData);
-
- //获取操作类型
- Envelope.Operation operation = Envelope.operationFor(sourceRecord);
-
- //装配数据
- JSONObject object = new JSONObject();
- object.put("database",database);
- object.put("table",table);
- object.put("before",beforeData);
- object.put("after",afterData);
-
-
- collector.collect(object.toString());
- }
-
- @Override
- public TypeInformation getProducedType() {
- return BasicTypeInfo.STRING_TYPE_INFO;//这里一般就是写String类型了
- }
- }
public static class PersonDeserialization implements DebeziumDeserializationSchema <String>{
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
//获取database和table
String topic = sourceRecord.topic();
String[] split = topic.split("\\.");
String database = split[1];
String table = split[2];
JSONObject data = new JSONObject();
//获取value值
Struct value = (Struct) sourceRecord.value();
Struct before = value.getStruct("before");
JSONObject beforeData = new JSONObject();
if(before!=null){
for (Field field : before.schema().fields()) {
Object o = before.get(field);
beforeData.put(field.name(),o);
}
}else{
before=null;
}
Struct after = value.getStruct("after");
JSONObject afterData = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
afterData.put(field.name(),o);
}
data.put("before",beforeData);
data.put("after",afterData);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//装配数据
JSONObject object = new JSONObject();
object.put("database",database);
object.put("table",table);
object.put("before",beforeData);
object.put("after",afterData);
collector.collect(object.toString());
}
@Override
public TypeInformation getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
上面可以写成工具类,直接使用

是不是就能满足我们想要的数据了


