
- 1代码面试最常用的10大算法_面试最熟悉的算法
- 2Xcode自带Git Source Control的使用_xcode source control
- 3网吧无盘系统
- 4从新手到专家:精通MacOS上的Homebrew安装_macos homebrew
- 5数据结构--平衡二叉树和红黑树_红黑树与平衡二叉树数据库
- 6华为OD机试C卷-- 快递员的烦恼(Java & JS & Python & C)_快递员的烦恼 华为od
- 7Selenium IDE使用指南六(指令列表)_drag and drop to object
- 8Fragment与ViewModel(MVVM架构)_homeviewmodel.gettext().observe(getviewlifecycleow
- 9【开源】一款PyQT+Pyserial开发的串口调试工具_pyqt 串口 编译
- 10java-数据结构与算法-02-数据结构-02-链表
Spark项目实训(一)_spark实训代码
赞
踩
目录
实验任务一:计算级数
请用脚本的方式编程计算并输出下列级数的前 n 项之和 Sn,直到 Sn 刚好大于或等于 q 为止,其中 q 为大于 0 的整数,其值通过键盘输 入。
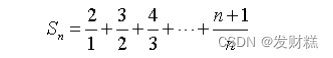
例如,若 q 的值为 50.0,则输出应为:Sn=50.416695。请将源文件 保存为 exercise2-1.scala,在 REPL 模式下测试运行,测试样例: q=1 时,Sn=2;q=30 时,Sn=30.891459;q=50 时,Sn=50.416695。
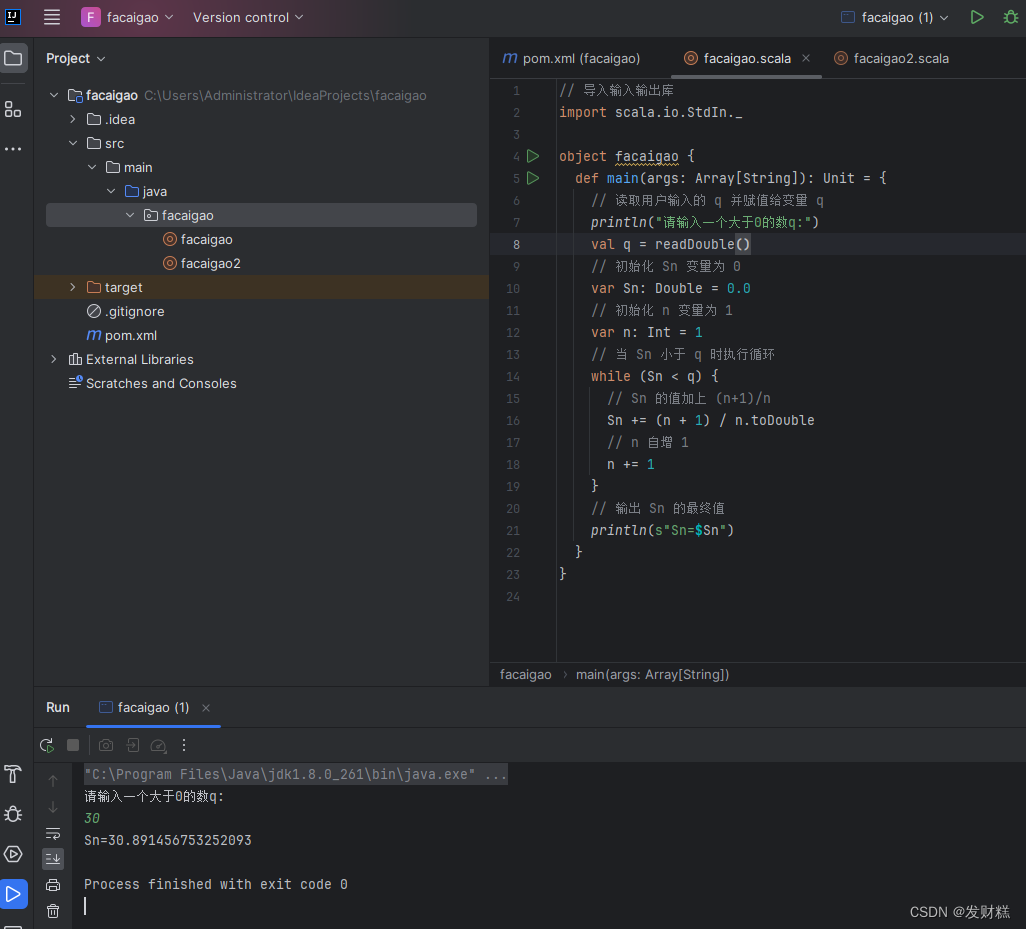
idea步骤分步:
// 导入输入输出库
import scala.io.StdIn._
- // 导入输入输出库
- import scala.io.StdIn._
// 初始化 Sn 变量为 0
- // 初始化 Sn 变量为 0
- var Sn: Double = 0.0
// 初始化 n 变量为 1
![]()
// 读取用户输入的 q 并赋值给变量 q
val q = StdIn.readInt()
- // 读取用户输入的 q 并赋值给变量 q
- println("请输入一个大于0的数q:")
- val q = readDouble()
// 当 Sn 小于 q 时执行循环
- // 当 Sn 小于 q 时执行循环
- while (Sn < q) {
-
- }
// Sn 的值加上(n+1)/n
- // Sn 的值加上 (n+1)/n
- Sn += (n + 1) / n.toDouble
// n 自增 1
- // n 自增 1
- n += 1
// 输出 Sn 的最终值
- // 输出 Sn 的最终值
- println(s"Sn=$Sn")
完整代码:
- // 导入输入输出库
- import scala.io.StdIn._
-
- object facaigao {
- def main(args: Array[String]): Unit = {
- // 读取用户输入的 q 并赋值给变量 q
- println("请输入一个大于0的数q:")
- val q = readDouble()
- // 初始化 Sn 变量为 0
- var Sn: Double = 0.0
- // 初始化 n 变量为 1
- var n: Int = 1
- // 当 Sn 小于 q 时执行循环
- while (Sn < q) {
- // Sn 的值加上 (n+1)/n
- Sn += (n + 1) / n.toDouble
- // n 自增 1
- n += 1
- }
- // 输出 Sn 的最终值
- println(s"Sn=$Sn")
- }
- }

linux步骤分布:
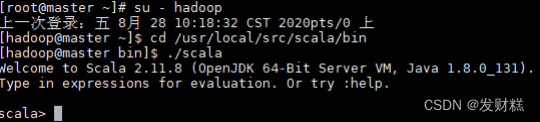
1、开启 scala 命令行:
- [root@master ~]# su - hadoop
- [hadoop@master ~]$ cd /usr/local/src/scala/bin
- [hadoop@master bin]$ ./scala
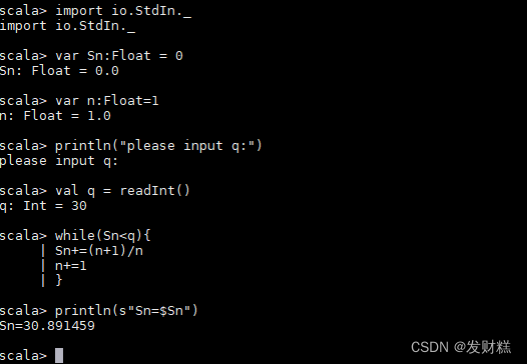
2、执行下面的代码:
- // 导入输入输出库
- scala> import io.StdIn._
- // 初始化 Sn 变量为 0
- scala> var Sn:Float = 0
- // 初始化 n 变量为 1
- scala> var n:Float=1
- // 输出提示信息让用户输入 q
- scala> println("please input q:")
- // 读取用户输入的 q 并赋值给变量 q
- scala> val q = readInt()
- // 当 Sn 小于 q 时执行循环
- scala> while(Sn<q){
- | Sn+=(n+1)/n // Sn 的值加上(n+1)/n
- | n+=1 // n 自增 1
- | }
- // 输出 Sn 的最终值
- scala> println(s"Sn=$Sn")
其中 val q = readInt()表示在 linux shell 终端输入 q 的 值,执行代码之后会一直监听窗口,等待键盘输入 q 的值,这里设 置了 q=30。
最后输入 :q 退出 scala shell
实验任务二:统计学生成绩
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为 学号、性别、课程名 1、课程名 2 等,后面每一行代表一个学生的 信息,各字段之间用空白符隔开, 给定任何一个如上格式的清单(不同清单里课程数量可能不一样), 要求尽可能采用函数式编程,统计出各门课程的平均成绩,最低成 绩,和最高成绩;另外还需按男女同学
- Id gender Math English Physics Science
- 301610 male 72 39 74 93
- 301611 male 75 85 93 26
- 301612 female 85 79 91 57
- 301613 female 63 89 61 62
- 301614 male 72 63 58 64
- 301615 male 99 82 70 31
- 301616 female 100 81 63 72
- 301617 male 74 100 81 59
- 301618 female 68 72 63 100
- 301619 male 63 39 59 87
- 301620 female 84 88 48 48
- 301621 male 71 88 92 46
- 301622 male 82 49 66 78
- 301623 male 63 80 83 88
- 301624 female 86 80 56 69
- 301625 male 76 69 86 49
- 301626 male 91 59 93 51
- 301627 female 92 76 79 100
- 301628 male 79 89 78 57
- 301629 male 85 74 78 80
分开,分别统计各门课程的 平均成绩,最低成绩,和最高成绩。
桌面创建数据文件名字为1.txt
- Id gender Math English Physics
- 301610 male 80 64 78
- 301611 female 65 87 58
- 301612 female 44 71 77
- 301613 female 66 71 91
- 301614 female 70 71 100
- 301615 male 72 77 72
- 301616 female 73 81 75
- 301617 female 69 77 75
- 301618 male 73 61 65
- 301619 male 74 69 68
- 301620 male 76 62 76
- 301621 male 73 69 91
- 301622 male 55 69 61
- 301623 male 50 58 75
- 301624 female 63 83 93
- 301625 male 72 54 100
- 301626 male 76 66 73
- 301627 male 82 87 79
- 301628 female 62 80 54
- 301629 male 89 77 72
桌面创建数据文件名字为2.txt
idea步骤分布:
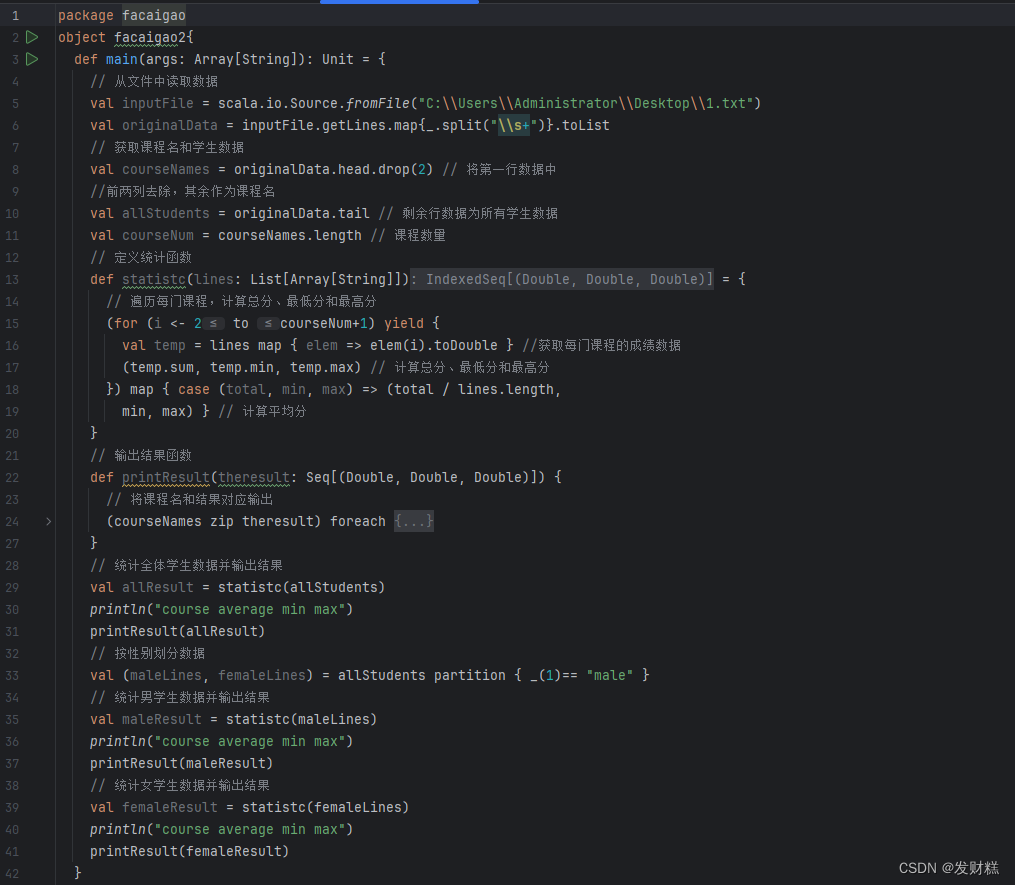
// 从文件中读取数据
- val inputFile = scala.io.Source.fromFile("C:\\Users\\Administrator\\Desktop\\1.txt")
- val originalData =inputFile.getLines.map{_.split("\\s+")}.toList
// 获取课程名和学生数据
val courseNames = originalData.head.drop(2) // 将第一行数据中//前两列去除,其余作为课程名
- val allStudents = originalData.tail // 剩余行数据为所有学生数据
- val courseNum = courseNames.length // 课程数量
// 定义统计函数
- def statistc(lines: List[Array[String]]) = {
- // 遍历每门课程,计算总分、最低分和最高分
- (for (i <- 2 to courseNum+1) yield {
- val temp = lines map { elem => elem(i).toDouble } //获取每门课程的成绩数据
- (temp.sum, temp.min, temp.max) // 计算总分、最低分和最高分
- }) map { case (total, min, max) => (total / lines.length,
- min, max) } // 计算平均分
- }
// 输出结果函数
- def printResult(theresult: Seq[(Double, Double, Double)]) {
- // 将课程名和结果对应输出
- (courseNames zip theresult) foreach {
- case (course, result) => println(f"${course + ":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")
- }
- }
// 统计全体学生数据并输出结果
- val allResult = statistc(allStudents)
- println("course average min max")
- printResult(allResult)
// 按性别划分数据
val (maleLines, femaleLines) = allStudents partition { _(1)== "male" }
// 统计男学生数据并输出结果
val maleResult = statistc(maleLines)// 统计女学生数据并输出结果
- val femaleResult = statistc(femaleLines)
- println("course average min max")
- printResult(femaleResult)
完整代码:
- package facaigao
-
- object facaigao2{
- def main(args: Array[String]): Unit = {
- // 从文件中读取数据
- val inputFile = scala.io.Source.fromFile("C:\\Users\\Administrator\\Desktop\\1.txt")
- val originalData = inputFile.getLines.map{_.split("\\s+")}.toList
- // 获取课程名和学生数据
- val courseNames = originalData.head.drop(2) // 将第一行数据中
- //前两列去除,其余作为课程名
- val allStudents = originalData.tail // 剩余行数据为所有学生数据
- val courseNum = courseNames.length // 课程数量
- // 定义统计函数
- def statistc(lines: List[Array[String]]) = {
- // 遍历每门课程,计算总分、最低分和最高分
- (for (i <- 2 to courseNum+1) yield {
- val temp = lines map { elem => elem(i).toDouble } //获取每门课程的成绩数据
- (temp.sum, temp.min, temp.max) // 计算总分、最低分和最高分
- }) map { case (total, min, max) => (total / lines.length,
- min, max) } // 计算平均分
- }
- // 输出结果函数
- def printResult(theresult: Seq[(Double, Double, Double)]) {
- // 将课程名和结果对应输出
- (courseNames zip theresult) foreach {
- case (course, result) => println(f"${course + ":"}%-10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")
- }
- }
- // 统计全体学生数据并输出结果
- val allResult = statistc(allStudents)
- println("course average min max")
- printResult(allResult)
- // 按性别划分数据
- val (maleLines, femaleLines) = allStudents partition { _(1)== "male" }
- // 统计男学生数据并输出结果
- val maleResult = statistc(maleLines)
- println("course average min max")
- printResult(maleResult)
- // 统计女学生数据并输出结果
- val femaleResult = statistc(femaleLines)
- println("course average min max")
- printResult(femaleResult)
- }
- }

样例1运行结果
样例2运行结果:

linux步骤分步:
创建代码文件夹
- [hadoop@master myscalacode]$ cd /
- [hadoop@master /]$ sudo mkdir myscalacode2
创建数据源文件
- [hadoop@master /]$ cd myscalacode2
- [hadoop@master myscalacode2]$ sudo vim test.txt
按 i 进入编辑模式,输入以下测试样例 1或者测试样例 2 的数据 (这里以测试样例 1 举例)
样例1
- Id gender Math English Physics
- 301610 male 80 64 78
- 301611 female 65 87 58
- 301612 female 44 71 77
- 301613 female 66 71 91
- 301614 female 70 71 100
- 301615 male 72 77 72
- 301616 female 73 81 75
- 301617 female 69 77 75
- 301618 male 73 61 65
- 301619 male 74 69 68
- 301620 male 76 62 76
- 301621 male 73 69 91
- 301622 male 55 69 61
- 301623 male 50 58 75
- 301624 female 63 83 93
- 301625 male 72 54 100
- 301626 male 76 66 73
- 301627 male 82 87 79
- 301628 female 62 80 54
- 301629 male 89 77 72
样例2
- Id gender Math English Physics Science
- 301610 male 72 39 74 93
- 301611 male 75 85 93 26
- 301612 female 85 79 91 57
- 301613 female 63 89 61 62
- 301614 male 72 63 58 64
- 301615 male 99 82 70 31
- 301616 female 100 81 63 72
- 301617 male 74 100 81 59
- 301618 female 68 72 63 100
- 301619 male 63 39 59 87
- 301620 female 84 88 48 48
- 301621 male 71 88 92 46
- 301622 male 82 49 66 78
- 301623 male 63 80 83 88
- 301624 female 86 80 56 69
- 301625 male 76 69 86 49
- 301626 male 91 59 93 51
- 301627 female 92 76 79 100
- 301628 male 79 89 78 57
- 301629 male 85 74 78 80
添加完毕之后按 Esc 键退出编辑模式,输入“:wq”保存退出
新建 scala 文件并编写代码
[hadoop@master myscalacode2]$ sudo vim scoreReport.scalai 进入编辑模式,编写以下代码
- object scoreReport {
- def main(args: Array[String]) {
- // 从文件中读取数据
- val inputFile = scala.io.Source.fromFile("test.txt")
- val originalData =
- inputFile.getLines.map{_.split("\\s+")}.toList
- // 获取课程名和学生数据
- val courseNames = originalData.head.drop(2) // 将第一行数据中
- 前两列去除,其余作为课程名
- val allStudents = originalData.tail // 剩余行数据为所有学生数
- 据
- val courseNum = courseNames.length // 课程数量
- // 定义统计函数
- def statistc(lines: List[Array[String]]) = {
- // 遍历每门课程,计算总分、最低分和最高分
- (for (i <- 2 to courseNum+1) yield {
- val temp = lines map { elem => elem(i).toDouble } //
- 获取每门课程的成绩数据
- (temp.sum, temp.min, temp.max) // 计算总分、最低分和
- 最高分
- }) map { case (total, min, max) => (total / lines.length,
- min, max) } // 计算平均分
- }
- // 输出结果函数
- def printResult(theresult: Seq[(Double, Double, Double)]) {
- // 将课程名和结果对应输出
- (courseNames zip theresult) foreach {
- case (course, result) => println(f"${course + ":"}%-
- 10s${result._1}%5.2f${result._2}%8.2f${result._3}%8.2f")
- }
- }
- // 统计全体学生数据并输出结果
- val allResult = statistc(allStudents)
- println("course average min max")
- printResult(allResult)
- // 按性别划分数据
- val (maleLines, femaleLines) = allStudents partition { _(1)
- == "male" }
- // 统计男学生数据并输出结果
- val maleResult = statistc(maleLines)
- println("course average min max")
- printResult(maleResult)
- // 统计女学生数据并输出结果
- val femaleResult = statistc(femaleLines)
- println("course average min max")
- printResult(femaleResult)
- }
- }
编译并运行程序
- [hadoop@master myscalacode2]$ sudo /usr/local/src/scala/bin/scalac
- scoreReport.scala
- [hadoop@master myscalacode2]$ ls
- [hadoop@master myscalacode2]$ sudo /usr/local/src/scala/bin/scala
- scoreReport
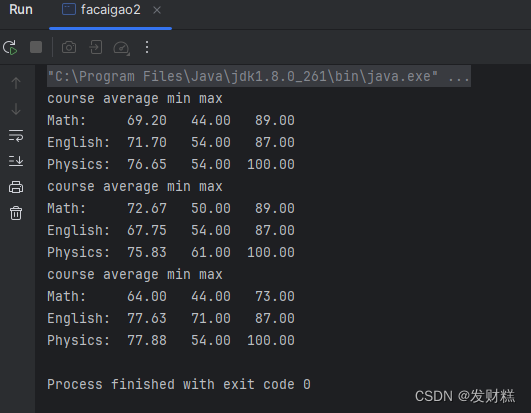
样例 1 的统计结果输出为:
- course average min max
- Math: 69.20 44.00 89.00
- English: 71.70 54.00 87.00
- Physics: 76.65 54.00 100.00
- course average min max (males)
- Math: 72.67 50.00 89.00
- English: 67.75 54.00 87.00
- Physics: 75.83 61.00 100.00
- course average min max (females)
- Math: 64.00 44.00 73.00
- English: 77.63 71.00 87.00
- Physics: 77.88 54.00 100.00
样例 2 的统计结果为:
- course average min max
- Math: 79.00 63.00 100.00
- English: 74.05 39.00 100.00
- Physics: 73.60 48.00 93.00
- Science: 65.85 26.00 100.00
- course average min max
- Math: 77.08 63.00 99.00
- English: 70.46 39.00 100.00
- Physics: 77.77 58.00 93.00
- Science: 62.23 26.00 93.00
- course average min max
- Math: 82.57 63.00 100.00
- English: 80.71 72.00 89.00
- Physics: 65.86 48.00 91.00
- Science: 72.57 48.00 100.00

