
热门标签
热门文章
- 1十大经典排序算法与算法复杂度_十大排序算法时间复杂度
- 2再也不用手写爬虫了!推荐5款自动爬取数据的神器!_自动爬取工具(1)_you-get python
- 3Ubuntu设置动态壁纸(background)_ubuntu设置 代码雨动态壁纸
- 4You may use special comments to disable some warnings. Use // eslint-disable-next-line to ignore the_eslint-disable-next-line to ignore the next line.
- 5golang生成c-shared so供c语言或者golang调用到例子_golang 打包so
- 6用博奥如何导入单项工程电子表_如何做好建筑工程预算?一步一步教会你!
- 7如何使用Spring Boot实现分页和排序?_如何使用 spring boot 实现分页和排序?
- 8十大编程算法助程序员走上高手之路
- 9Spring Cloud Alibaba 接入AI,3分钟搞定一个 AI 项目!_spring cloud alibaba ai
- 10考官面对面:我是如何面试程序员的?_程序员考核考官
当前位置: article > 正文
hive 分区表_Spark读取Hive分区表的问题
作者:酷酷是懒虫 | 2024-06-19 12:24:19
赞
踩
spark读取hive分区配置错误
最近在对公司集群的数据进行进一步的整理和归类,在进行数据整合的时候发现Spark读取hive分区表的时候出现了一点问题,会出现org.apache.hadoop.mapred.InvalidInputException: Input path does not exist
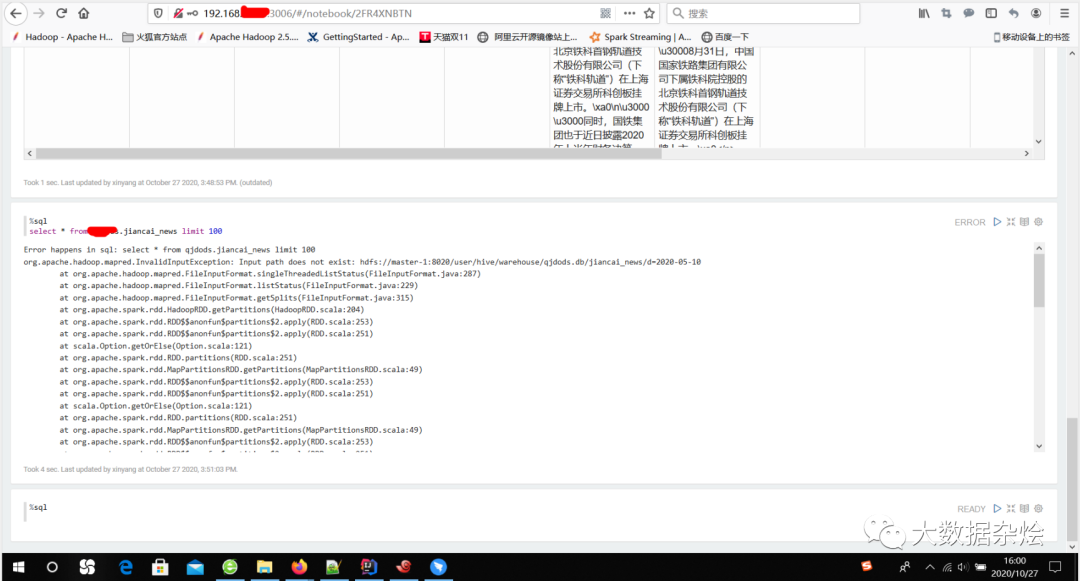
使用Hue查询hive数据
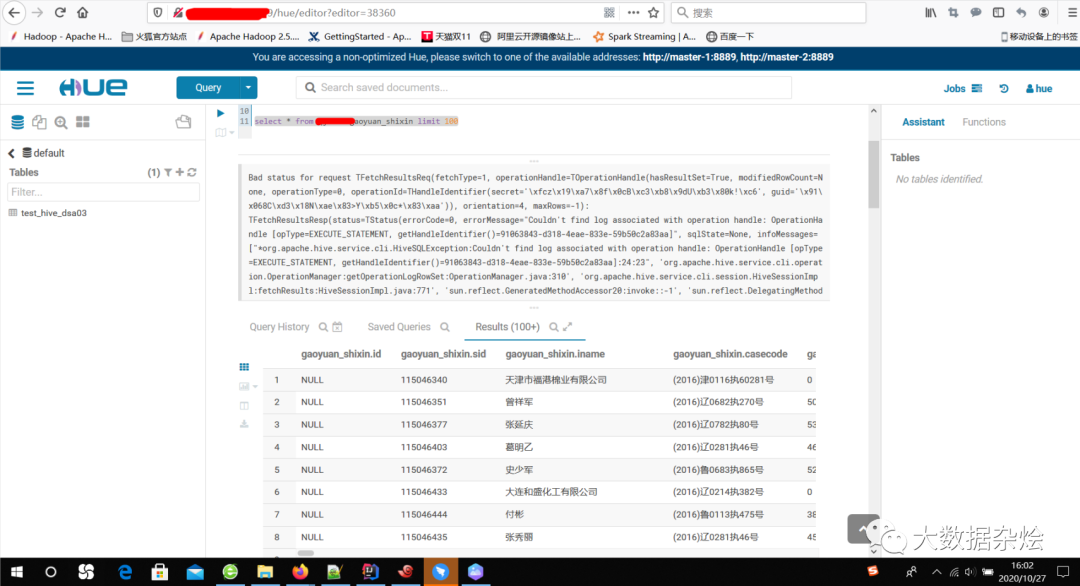
考虑难道Zeppelin上面读取hive分区是有问题的?难不成hive库谁动了?根据这个错误提示去找问题,既然这个数据不存在那就找找相对应库里面所有的分区表吧,那么既然不存在为何查看tables的时候却有233个分区,是因为数据丢失或删除的时候没有做 alter table table_name drop partition (d>='XXXX')
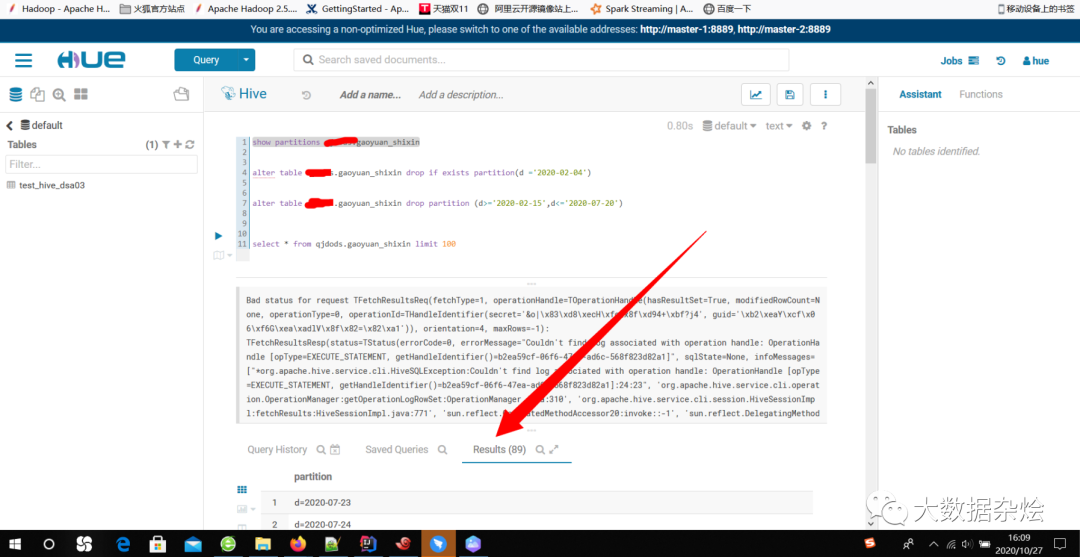
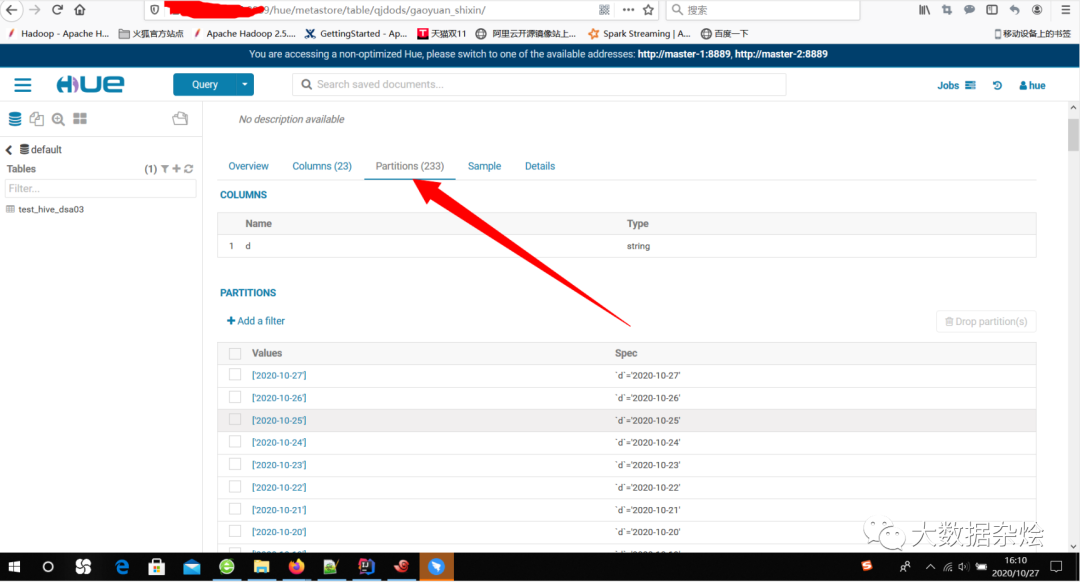
既然问题知道什么原因,那就动手吧,两个思路:第一,Spark读取Hive数据的时候添加分区条件进行读取的过滤,第二,那这个不存在的分区全部删除。由于分区时间是连续的我采用 alter table table_name drop partition (d>='2020-02-15',d<='2020-07-20')的方式删除不存在的分区。
再次使用Spark去读取hive数据
但是还是有个问题就是在Hue中查看Tables里面的分区的时候这些分区还在,更新元数据以后还是没有用,那剩下的只能手动删除了 !
!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/酷酷是懒虫/article/detail/736430
推荐阅读
相关标签

