
- 1人工智能专业术语的个人理解与总结(ML、DL、RL)_rl episode
- 2Python:实现tree sort树排序算法(附完整源码)_排序树python代码
- 3MySQL Binlog 解析工具 Maxwell 详解_binlog viewer
- 4超详细的github学生认证以及copilot使用
- 5资金账户系统的设计
- 6【SoC FPGA】XCZU1CG-2SBVA484E、XCZU1CG-2SFVC784E、XCZU1CG-1SFVC784I、XCZU1CG-1SFVC784E工业物联网应用_xczu1eg-2sfvc784i
- 7pyqt5基本使用操作_pyqt5怎么使用
- 8C++入门DP--动态规划_c++ dp入门
- 9【C算法】编程初学者入门训练140道(1~20)
- 10银河麒麟服务器版v10,桥接网络虚机可以ping通宿主机,但是ping不通网关和其他主机_麒麟v10 iptables
[论文泛读]REALM:RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Langu_rag相关论文
赞
踩
AI辅助
文章提到的prompt模版
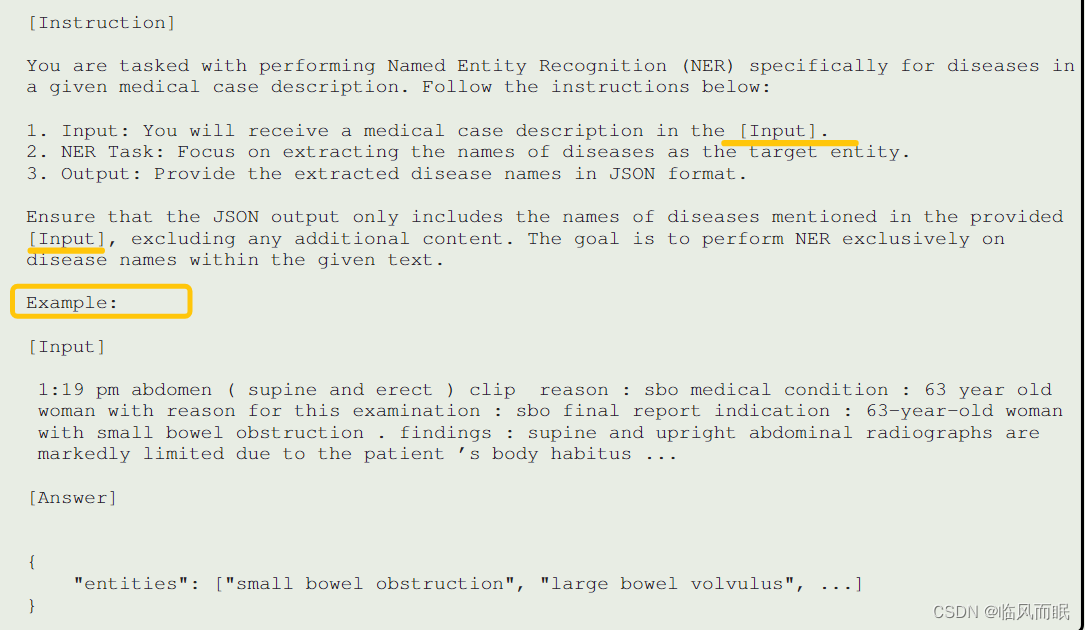
Prompt for entity extraction
Complete XRAG demonstration with retrieved results

每部分总结
当然,下面是对论文《REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models》每一部分的更详细总结:
摘要(Abstract)
- 论文提出了REALM框架,这是一个基于检索增强生成(RAG)的方法,用于增强多模态电子健康记录(EHR)的表示。
- REALM通过结合大型语言模型(LLM)和外部知识图谱(KG)来提高临床预测的准确性。
- 该框架首先使用LLM编码临床笔记,使用GRU模型编码时间序列EHR数据。
- 通过LLM提取与任务相关的医学实体,并与PrimeKG中的知识进行匹配,以确保一致性并消除幻觉。
- 提出了一个自适应多模态融合网络,用于整合提取的知识与多模态EHR数据。
- 在MIMIC-III数据集上的实验表明,REALM在死亡率和再入院任务上的性能优于现有方法。
1 引言(Introduction)
- 介绍了EHR在提高医疗保健系统效率方面的重要性。
- 指出了现有模型在处理EHR数据时缺乏医疗上下文的问题。
- 强调了将外部知识,特别是知识图谱,整合到EHR分析中的必要性。
- 介绍了REALM框架的动机,旨在通过RAG方法解决现有方法的局限性。
2 相关工作(Related Work)
- 回顾了多模态EHR学习的发展历程,包括M3Care、MIM等模型。
- 讨论了如何将外部知识整合到EHR中的方法,如GRAM、KAME等,并指出了它们的局限性。
- 强调了结合结构化和非结构化数据模态的重要性,以及现有方法在这方面的不足。
3 问题表述(Problem Formulation)
- 描述了EHR数据集的结构,包括多变量时间序列数据和临床笔记。
- 引入了外部知识图谱(KG)的概念,并说明了如何将其用于增强个体患者的个性化表示。
- 将预测任务定义为二元分类任务,包括预测住院期间的死亡率和再入院率。
4 方法论(Methodology)
- 详细介绍了REALM框架的三个主要模块:多模态EHR嵌入提取、RAG驱动增强管道和多模态融合网络。
- 描述了如何使用GRU和LLM来提取时间序列和文本记录的嵌入。
- 介绍了RAG驱动增强管道的工作流程,包括实体提取、实体精炼和与外部KG匹配。
- 讨论了如何使用自注意力和交叉注意力机制来融合不同模态的信息。
5 实验设置(Experimental Setups)
- 介绍了MIMIC-III数据集的来源和预处理方法。
- 详细说明了评估指标,包括AUROC、AUPRC、min(+P, Se)和F1分数。
- 描述了超参数的选择和基线模型的选择。
6 实验结果(Experimental Results)
- 展示了REALM在MIMIC-III数据集上的死亡率和再入院预测任务上的性能,并与多个基线模型进行了比较。
- 进行了消融研究,以展示RAG增强对每个模态的贡献。
- 比较了不同的文本嵌入模型和多模态融合方法的效果。
- 评估了模型对数据稀疏性的鲁棒性,并分析了检索实体的质量。
7 结论(Conclusions)
- 总结了REALM框架的主要贡献,包括提出了一个新的多模态EHR数据表示学习框架,以及在MIMIC-III数据集上取得的优异性能。
- 强调了REALM在实际临床环境中的潜在应用价值。
词汇积累


文中术语
-
Electronic Health Records (EHR): 电子健康记录,是一种数字化的个人健康信息管理系统,用于存储、管理和传输患者健康信息。
-
Multimodal Data: 多模态数据,指的是结合了多种类型的数据,如文本、图像、时间序列等,以提供更全面的分析视角。
-
Clinical Notes: 临床笔记,医生在诊疗过程中记录的患者病情、治疗计划和观察结果的文本。
-
Multivariate Time-Series Data: 多变量时间序列数据,指的是随时间变化的多个相关变量的数值记录。
-
Knowledge Graph (KG): 知识图谱,一种结构化的知识表示方式,以图的形式存储实体之间的关系和属性。
-
Retrieval-Augmented Generation (RAG): 检索增强生成,一种结合了检索和生成的技术,用于在生成任务中利用外部知识源。
-
Large Language Model (LLM): 大型语言模型,如GPT-3或GPT-4,是一种预训练的深度学习模型,能够理解和生成自然语言文本。
-
Named Entity Recognition (NER): 命名实体识别,一种自然语言处理任务,用于从文本中识别和分类具有特定意义的实体(如人名、地点、疾病等)。
-
Medical Context: 医学上下文,指的是与医疗实践、疾病诊断和治疗相关的背景知识和信息。
-
MIMIC-III: 一种公开的、去标识化的重症监护病房患者数据库,常用于临床决策支持系统的开发和评估。
-
AUROC (Area Under the Receiver Operating Characteristic Curve): 接收者操作特征曲线下的面积,是一种评估分类模型性能的指标,尤其在处理不平衡数据集时。
-
AUPRC (Area Under the Precision-Recall Curve): 精确率-召回率曲线下的面积,另一种评估分类模型性能的指标,特别适用于二元分类任务。
-
min(+P, Se): 精确率(Positive Predictive Value, +P)和敏感性(Sensitivity, Se)的最小值,用于衡量模型的平衡性能。
-
F1 Score: F1分数,是精确率和召回率的调和平均,用于衡量模型的整体性能。
-
Entity Extraction: 实体提取,从文本中识别出具有特定意义的信息片段,如疾病名称、药物名称等。
-
Hallucination: 在语言模型生成的文本中出现的不真实或错误的信息。
-
Self-Attention and Cross-Attention: 自注意力和交叉注意力,是深度学习模型中用于处理序列数据的机制,能够捕捉序列内部和不同序列之间的关系。

