
- 1Java项目:医院管理系统(java+Springboot+Maven+Mybatis+Vue+Mysql)_医院自动排班java
- 2kafka学习笔记(3)——命令行操作_kafka命令行操作
- 3pandas read_excel函数_遍历pandas库读取excel文件返回值
- 4字典序问题
- 5pytorch简单的优化问题实战_用pytorch做优化问题
- 6Numpy中ndim、shape、dtype、astype的用法_numpy as type
- 7风险评估:IIS的安全配置,IIS安全基线检查加固_iis中间件配置安全基线
- 8一个合格的中级前端工程师需要掌握的技能笔记(下)
- 9openwrt网关服务器性能,单一ipv6地址做网关的三种方法之openwrt篇
- 10fiddler抓包,Iphone 设置代理后,app和其他任何东西都不能上网的解决方案_fiddler设置代理后app
大数据大作业:(scrapy框架)使用uid爬取哔哩哔哩up主主页视频信息并进行数据可视化分析_爬取up主视频数据
赞
踩
所需条件:
python 3.12 (最好是python3)
PyCharm 2023
ChromeDriver (selenium)
题外话:
在python中,scrapy、pyechart等库需自行下载
1、获取项目
先说一下为什么使用scrapy框架:
选择scrapy框架的优势
①模块化组件:Scrapy的设计将爬虫的各功能模块如引擎、调度器、下载器等分离,使得框架结构清晰,便于开发者理解和扩展。
②中间件扩展:通过编写中间件,通过拦截请求可以对请求进行特定处理,可以方便地添加过滤器等处理机制,进一步定制数据提取过程。
③管道机制:通过管道的方式,Scrapy可以轻松地将抓取的数据存入数据库,支持多种存储形式。
④高效并发:Scrapy采用了异步处理请求机制,多线程爬取数据,使得爬取网页十分迅速。能够在等待响应时处理其他请求,避免了传统同步请求中的等待时间,对应还可以灵活调节并发量,使得爬虫在处理大量请求时效率更高。
在本次爬虫程序中,使用MySQL和JSON方式来存储数据,在单次请求后提交单个视频的item到pipelines中进行数据清洗和存储,使用scrapy更为便捷。
快速获取gitee仓库项目,在cmd中使用git命令:
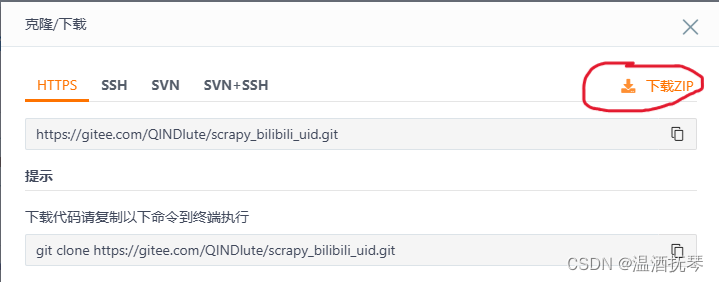
git clone https://gitee.com/QINDlute/scrapy_bilibili_uid.git若读者的电脑中未安装git,则访问该网址下载zip,自行解压后,用pycharm打开。
https://gitee.com/QINDlute/scrapy_bilibili_uid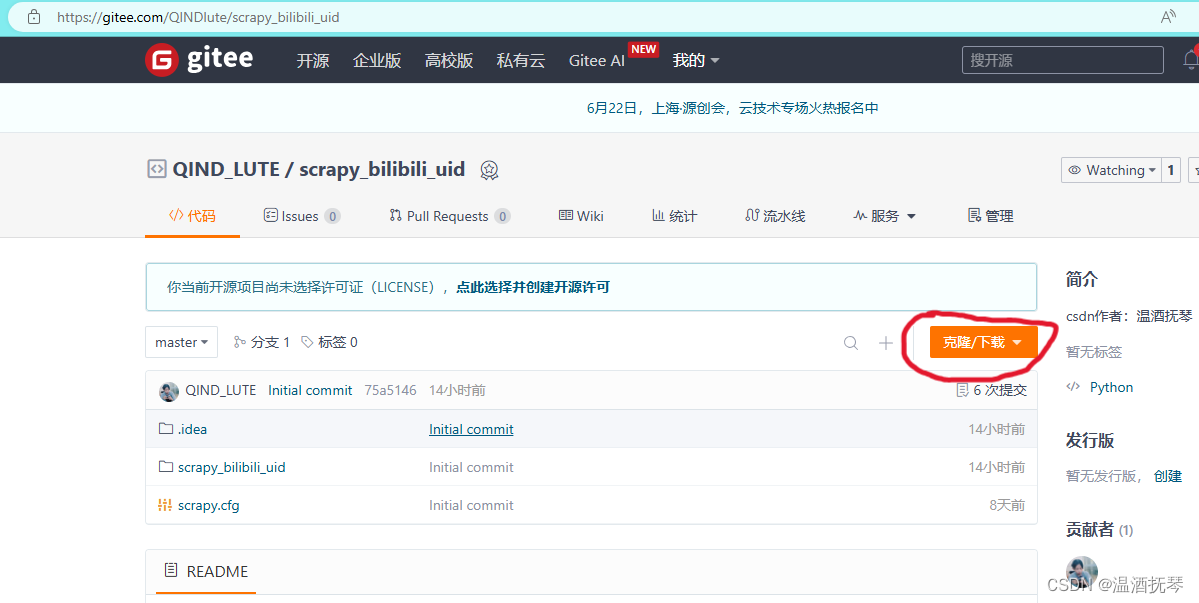
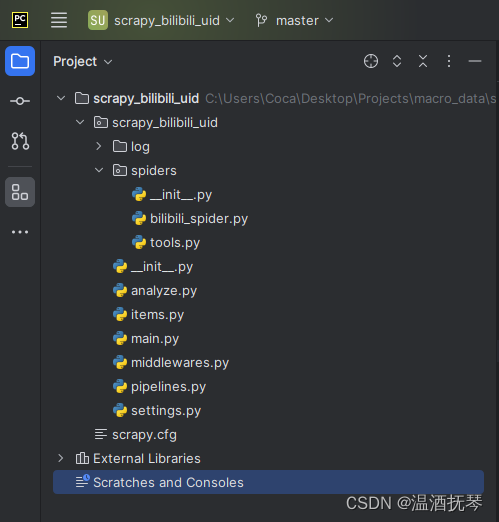
项目结构:
进入项目后设置python解释器:
添加已有python解释器:
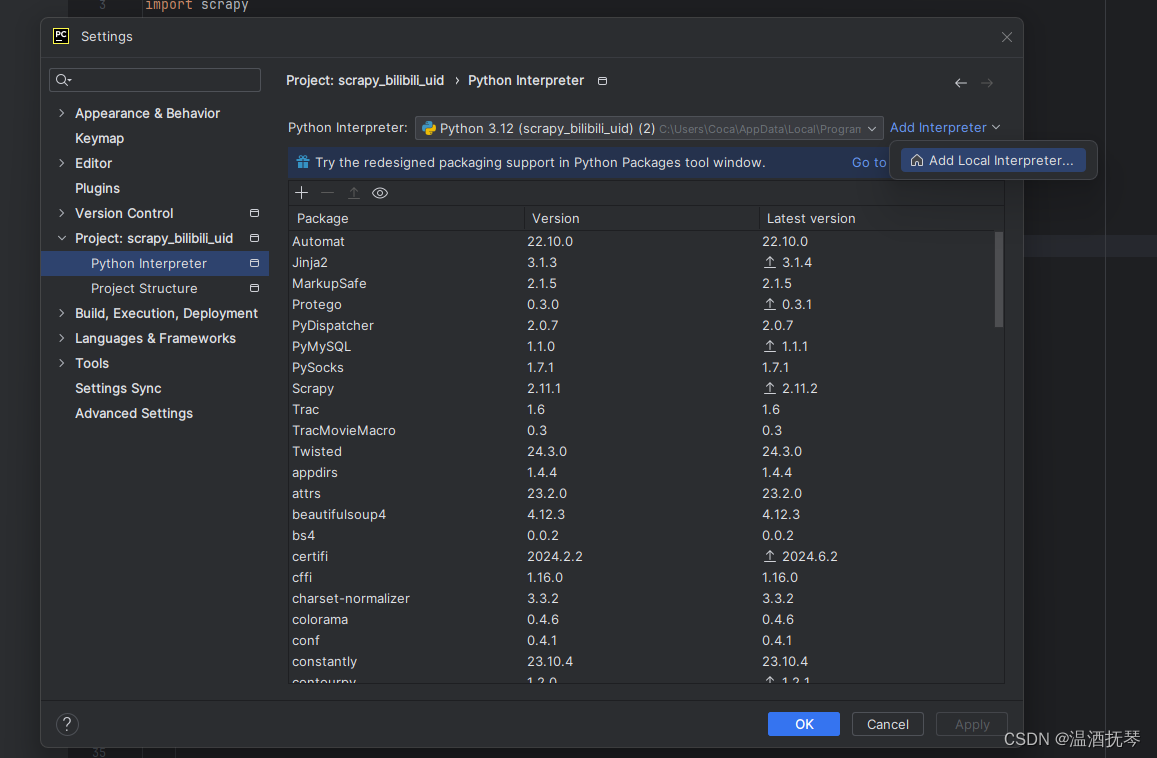
选择Existing选项
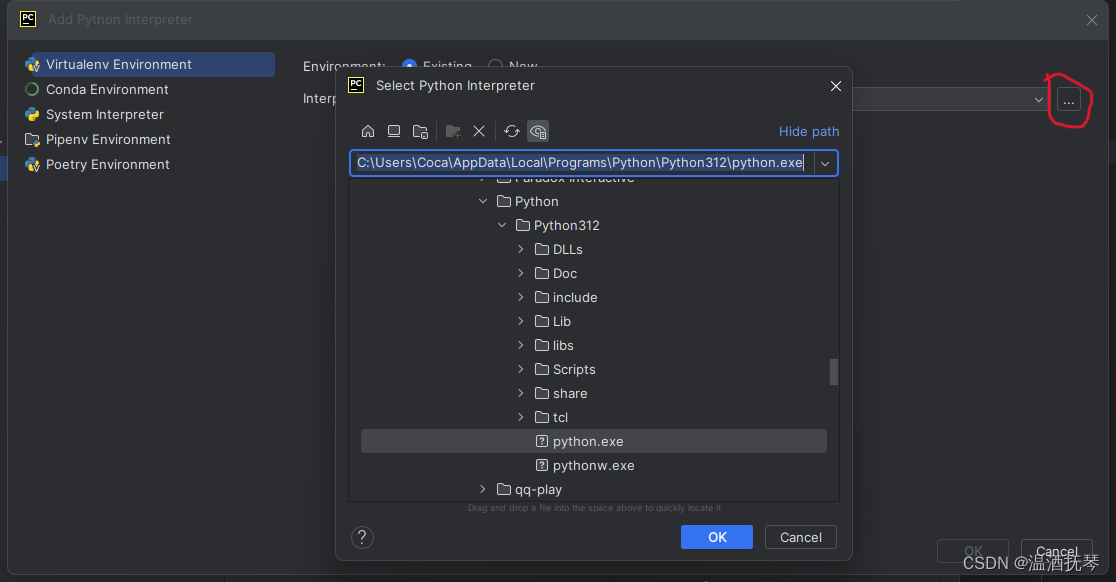
选择本地已下载python
2、selenium准备
由于b站网页优秀严密的反爬机制,使得requests配合BeautifulSoup这种常规解析网页源码的方式会被过滤拦截。
因此使用Selenium驱动ChromeDriver来抓取执行JavaScript时动态生成的页面,使浏览器自动化运行,能够模拟真实用户的浏览器行为。Selenium拥有很多有效的预防反爬机制,其中包括检测用户行为、IP地址的访问频率、请求头信息等。
使用selenium的好处:
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

