
热门标签
热门文章
- 1Redis面试详解:_你项目中哪块用了redis,你是怎么处理的
- 2揭秘EasyRecovery2025数据恢复神器新版本新功能介绍
- 3大数据系列之:Doris Kafka Connector,实时消费Kafka Topic中的数据同步到Doris数据库
- 4flinkCDC使用_flink cdc所要使用的包
- 5Linux下载mysql(Centos7)_mysql linux 下载
- 6mysql 高并发重复写入_高并发场景下数据重复插入的问题
- 7android__9.png图片_ui素材下载 android .9文件
- 8一键AI绘画软件有哪些?一起来探索AI绘画的无限可能吧
- 9AI斗图神器:普通视频秒变meme,手绘动画轻松融入,了解一下?
- 10[译]CSV 注入:被人低估的巨大风险
当前位置: article > 正文
word2vec代码_Word2Vec 代码-详细注释
作者:运维做开发 | 2024-08-02 04:56:40
赞
踩
word2vec代码
前言
这是 Word2Vec 的 Skip-Gram 模型的代码 (Tensorflow 1.15.0),代码源自https://blog.csdn.net/just_sort/article/details/87886385,我加了注释。
数据集:http://mattmahoney.net/dc/text8.zip
导入包
- import collections
- import math
- import os
- import random
- import zipfile
- import numpy as np
- import urllib
- import tensorflow as tf
- import numpy as np
- import matplotlib.pyplot as plt
数据预处理
这部分主要是下载解压数据,构建字典,给每个单词编号。
- filename = "./text8.zip"
- # 解压文件,并使用tf.compat.as_str将数据转成单词的列表
- with zipfile.ZipFile(filename) as f:
- result = f.read(f.namelist()[0]) # <class 'bytes'> 读入二进制数据
- document = tf.compat.as_str(result) # 将二进制数据转成字符串
- # print(document[:50]) # anarchism originated as a term of abuse first use
- words = document.split() # 按空白字符切分单词
- # print(len(words)) # 17005207个单词
50000个单词,第一个是'UNK',其他是最高频的前(50000-1)个单词 'unknown' 代指最高频的前(50000-1)个单词之外的所有单词,统计其数量 给单词编号:'unknown'是0号,其他按频率排序,频率越高,编号越前面 把语料库从单词列表转到编号列表
- #创建vocabulary词汇表
- vocabulary_size = 50000
- # 统计单词列表中单词的频数
- fre = collections.Counter(words)
- # 使用most_common方法获取top 50000频数的单词作为vocabulary
- top = fre.most_common(vocabulary_size - 1)
- count = [['UNK', -1]] # 列表中每个元素为[单词,频率]
- count.extend(top)
-
- # 创建一个dict,将top 50000词汇的放入dictionary中
- dictionary = dict()
- i = 0
- for word, _ in count:
- dictionary[word] = i #给top单词编号
- i += 1
- # 单词索引是键,单词频率是值
- reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()) )
-
- # top 50000词汇之外的单词,我们认定其为Unknown(未知),将其编号为0,并统计这类词汇的数量。
- unk_count = 0
-
- data = list() # 所有单词的索引
- for word in words:
- if word in dictionary.keys():
- index = dictionary[word] # top单词的索引
- else:
- index = 0 # 非top单词的索引
- unk_count += 1 # 非top单词的数量
- data.append(index)
- count[0][1] = unk_count

删除原始单词列表,可以节约内存
- del words # 删除原始单词列表,可以节约内存
- # 查看前10个出现最频繁的单词
- for i, j in count[:10]:
- print("words:{}, count:{}".format(i,j))
效果
- words:UNK, count:418391
- words:the, count:1061396
- words:of, count:593677
- words:and, count:416629
- words:one, count:411764
- words:in, count:372201
- words:a, count:325873
- words:to, count:316376
- words:zero, count:264975
- words:nine, count:250430
样本和标签
从语料库的第skip_window个单词开始,每一个单词都可以作为目标单词,并为每个目标单词产生num_skips个样本;每个样本的特征是目标单词,标签是其skip_window范围内的语境单词。
- #生成Word2Vec的样本
- cur = 0 # 当前的单词指针
- # 生成训练用的batch数据
- def generate_batch(batch_size, num_skips, skip_window):
- '''
- 参数
- batch_size为batch的大小;必须是它的整数倍(确保每个batch包含了一个词汇对应的所有样本)
- skip_window指单词最远可以联系的距离;设为1代表只能跟紧邻的2个单词生成样本。
- num_skips为对每个单词生成多少个样本,它不能大于skip_windows的2倍
- '''
- # 定义单词指针cur为global变量
- # 因为会反复调用generate_batch,所以要确保cur可以在函数generate_batch中被修改
- global cur
- # batch_size必须是它的整数倍(确保每个batch包含了一个词汇对应的所有样本)
- assert batch_size % num_skips == 0
- # num_skips 不能大于skip_windows的2倍
- assert num_skips <= 2 * skip_window
- # span为对某个单词创建相关样本时会用到的单词数量,包括目标单词本身和它前后的单词
- # 因此span=2*skip_windows+1
- span = 2 * skip_window + 1
-
- batch = np.ndarray(shape=(batch_size), dtype=np.int32)
- labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
-
-
- # 创建一个最大容量为span的deque,即双向队列
- # 在对deque使用append方法添加变量时,只会保留最后插入的span个变量
- buffer = collections.deque(maxlen=span)
-
- # 从指针cur开始,把span个单词顺序读入buffer作为初始值。
- for _ in range(span):
- data_index = data[cur] # 逐个取出单词的索引
- buffer.append(data_index)
- cur = (cur + 1) % len(data)
-
- for i in range(batch_size // num_skips):
- # buffer中第skip_window个变量为目标单词
- target = skip_window
- # 非标签的单词列表targets_to_avoid,一开始包括第skip_window个单词(即目标单词)
- # 因为我们要预测的是语境单词,不包括目标单词本身
- target_to_avoid = [skip_window]
- ########## 为目标单词产生 num_skips 个样本
- for j in range(num_skips):
- # 产生一个语境单词的索引
- while target in target_to_avoid:
- # 在[0, span-1]中随机产生一个整数
- target = random.randint(0, span - 1)
- # 每个样本的特征就是目标单词
- batch[i * num_skips + j] = buffer[skip_window]
- # 每个样本的标签是语境单词
- labels[i * num_skips + j, 0] = buffer[target]
- # 已经使用过的语境单词不会再被使用
- target_to_avoid.append(target)
-
- # 我们再读入下一个单词(同时会抛掉buffer中第一个单词)
- buffer.append(data[cur])
- # 单词指针后移
- cur = (cur + 1) % len(data)
- # 两层循环完成后,我们已经获得了batch_size个样本
- return batch, labels
调用generate_batch函数简单测试一下功能
- #调用generate_batch函数简单测试一下功能
- batch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
- for i in range(8):
- print("目标单词编号:{:<10}, 目标单词:{:<10}".format(batch[i], reverse_dictionary[batch[i]]),
- "语境单词编号:{:<10}, 语境单词:{:<10}".format(labels[i, 0], reverse_dictionary[labels[i, 0]]))
效果
- 目标单词编号:3081 , 目标单词:originated 语境单词编号:5234 , 语境单词:anarchism
- 目标单词编号:3081 , 目标单词:originated 语境单词编号:12 , 语境单词:as
- 目标单词编号:12 , 目标单词:as 语境单词编号:6 , 语境单词:a
- 目标单词编号:12 , 目标单词:as 语境单词编号:3081 , 语境单词:originated
- 目标单词编号:6 , 目标单词:a 语境单词编号:12 , 语境单词:as
- 目标单词编号:6 , 目标单词:a 语境单词编号:195 , 语境单词:term
- 目标单词编号:195 , 目标单词:term 语境单词编号:2 , 语境单词:of
- 目标单词编号:195 , 目标单词:term 语境单词编号:6 , 语境单词:a
验证集
- # 用来抽取的验证单词数
- valid_size = 16
- # 指验证单词只从频数最高的100个单词中抽取
- valid_window = 100
- valid_examples = np.random.choice(valid_window, valid_size, replace=False)
模型和训练
模型中,最核心的函数是 tf.nn.nce_loss() 函数的计算,但这一部分被封装好了,要研究下源码才能更了解该算法。代码还取了16个验证单词,通过计算单词之间的相似性,找出它最相似的8个单词,可以验证模型的效果。 定义超参数
- # 定义最大的迭代次数为10万次
- num_steps = 100001
- # 最远可以联系的距离
- skip_window = 1
- # 对每个目标单词提取的样本数
- num_skips = 2
- # embedding_size即将单词转换为稠密向量的维度,一般是50-1000这个范围内的值
- embedding_size = 128
- # 每个批量的样本
- batch_size = 128
- # 训练时用来做负样本的噪声单词的数量
- num_sampled = 64
构建模型和训练
- '''
- 50000个单词中每个都有一个随机产生的128维向量
- '''
- graph = tf.Graph()
- with graph.as_default():
- train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
- train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
- valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
- with tf.device('/cpu:0'):
- # 50000个单词中每个对应一个随机产生的128维向量
- embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
- # 查找输入train_inputs对应的向量embed
- embed = tf.nn.embedding_lookup(embeddings, train_inputs)
- # 权重和偏置
- nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0/math.sqrt(embedding_size)))
- nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
- # 计算损失:这里是Word2vec的核心
- loss = tf.reduce_mean(
- tf.nn.nce_loss(weights=nce_weights,
- biases=nce_biases,
- inputs = embed,
- labels=train_labels,
- num_sampled=num_sampled,
- num_classes=vocabulary_size
- ))
- # 定义优化器为SGD,且学习速率为1.0
- optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
-
- # 计算词向量embeddings的L2范数norm
- norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
- # 将embeddings除以其L2范数得到标准化后的normalized_embeddings
- normalized_embeddings = embeddings / norm
- # 查询验证单词的嵌入向量
- valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
- # 计算验证单词与词汇表中所有单词的相似性
- similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
-
-
- ####################### 训练
- # 使用tf.global_variables_initializer初始化所有模型的参数
- init = tf.global_variables_initializer()
-
- with tf.Session(graph=graph) as session:
- init.run()
- print('Initialized')
- average_loss = 0
- for step in range(1,num_steps+1):
- batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
- feed_dict = {train_inputs:batch_inputs, train_labels:batch_labels}
-
- _, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
- average_loss += loss_val
-
- if (step%2000==0):
- average_loss /= 2000
- print("Average loss at step {} : {}".format(step, average_loss))
- average_loss = 0
- if (step%10000==0):
- # 计算一次验证单词与全部单词的相似度
- sim = similarity.eval()
- # 将与每个验证单词最终相似的8个单词展示出来。
- for i in range(valid_size):
- valid_word = reverse_dictionary[valid_examples[i]]
- top_k = 8
- nearest = (-sim[i,:]).argsort()[1:top_k+1]
- log_str = "Nearest to %s :" % valid_word
- for k in range(top_k):
- ID = nearest[k]
- close_word = reverse_dictionary[ID]
- log_str = "%s %s ," % (log_str, close_word)
- print(log_str)
- final_embeddings = normalized_embeddings.eval()
结果
- Initialized
- Average loss at step 2000 : 114.31209418106079
- Average loss at step 4000 : 52.73329355382919
- Average loss at step 6000 : 33.614175471544264
- Average loss at step 8000 : 23.143466392278672
- Average loss at step 10000 : 17.812667747735976
- Nearest to up : tourist , pertain , fragments , northeast , electricity , negro , agreed , akita ,
- Nearest to at : in , poison , and , impacts , arno , of , for , beloved ,
- Nearest to been : agents , arno , install , bp , winter , lerner , gesch , is ,
- Nearest to they : arno , bits , front , attractive , contributing , not , pardoned , conservatoire ,
- Nearest to were : thyestes , are , and , bei , arno , is , in , refugees ,
- Nearest to about : arno , hope , hexagonal , bei , people , whole , neglected , jethro ,
- Nearest to war : drivers , going , amalthea , originally , antares , music , acetylene , sexuality ,
- Nearest to but : bei , and , potency , continued , treated , bradley , lyric , mosque ,
- Nearest to with : and , from , in , for , bei , cajun , housman , refugees ,
- Nearest to this : amalthea , it , them , the , legislative , a , basilica , feminine ,
- Nearest to time : UNK , bits , unintended , interrupt , goddess , secretary , cider , desktop ,
- Nearest to many : processor , horse , akita , arno , workbench , efficacy , draught , trials ,
- Nearest to nine : zero , eight , cider , three , six , akita , abingdon , arno ,
- Nearest to during : truncated , cis , arno , who , rushton , of , latitude , minorities ,
- Nearest to six : nine , eight , three , tuned , arno , zero , schema , cider ,
- Nearest to other : akita , decay , one , wyoming , residential , arbitration , film , country ,
- ......
- Average loss at step 92000 : 4.7263513580560685
- Average loss at step 94000 : 4.664387725114822
- Average loss at step 96000 : 4.719061789274216
- Average loss at step 98000 : 4.678433487653733
- Average loss at step 100000 : 4.569495327591896
- Nearest to up : out , off , them , clout , stroustrup , trusted , yin , cubs ,
- Nearest to at : in , during , arno , under , michelob , on , netbios , thaler ,
- Nearest to been : be , become , was , had , were , by , geoff , attending ,
- Nearest to they : we , he , there , you , she , it , who , not ,
- Nearest to were : are , was , have , had , those , be , neutronic , refugees ,
- Nearest to about : unital , microcebus , dinar , thibetanus , hope , that , arno , browns ,
- Nearest to war : incarnation , measurement , scoping , consult , geralt , sissy , rquez , tamarin ,
- Nearest to but : however , and , vulpes , bei , netbios , although , neutronic , microcebus ,
- Nearest to with : between , widehat , while , prism , against , in , filings , vulpes ,
- Nearest to this : it , which , the , amalthea , michelob , vulpes , thibetanus , that ,
- Nearest to time : lemmy , vulpes , glamour , secretary , fv , gcl , approximating , dragoon ,
- Nearest to many : some , several , these , quagga , most , other , mico , all ,
- Nearest to nine : eight , seven , six , five , four , zero , three , michelob ,
- Nearest to during : after , in , at , when , under , ssbn , cebus , since ,
- Nearest to six : seven , eight , five , four , three , nine , zero , two ,
- Nearest to other : various , many , some , quagga , nuke , bangor , different , including ,
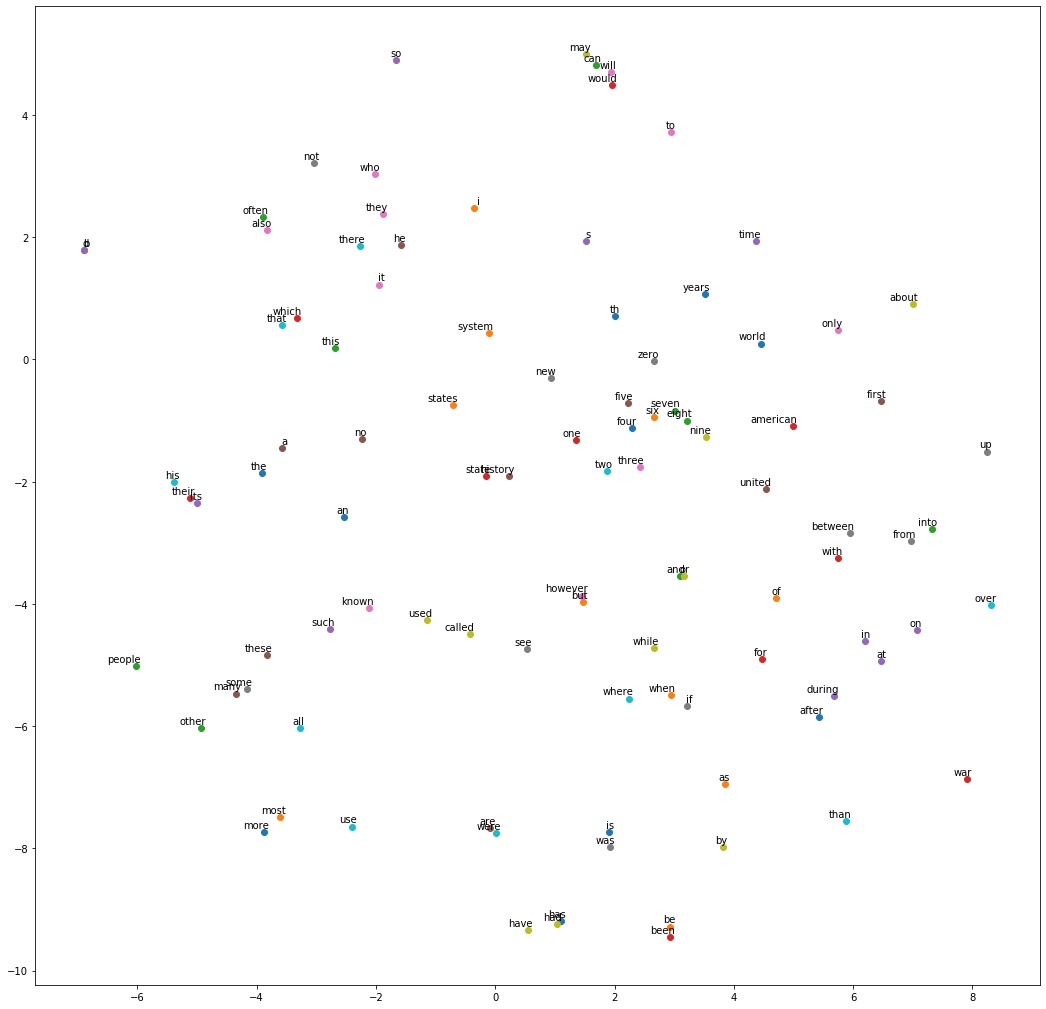
可视化
这里从生成的[50000, 128]的单词向量中,取100个高频词,用TSNE模块将其降低到2维,从而在坐标轴上可视化。
- def plot_embed(low_dim_embs, labels, filename='tsne.png'):
- '''
- low_dim_embs: 维度是n * 2,数据类型是二维数组
- labels: 维度是
- '''
- assert low_dim_embs.shape[0] >= len(labels), "More labels than embedding"
- plt.figure(figsize=(18,18))
- for i, label in enumerate(labels):
- x, y = low_dim_embs[i,:]
- plt.scatter(x, y)
- plt.annotate(label, xy=(x,y), xytext=(5,2),textcoords='offset points',
- ha='right', va='bottom')
- plt.savefig(filename)
绘图
- from sklearn.manifold import TSNE
- tsne = TSNE(perplexity=30, n_components=2, init='pca',n_iter=5000)
-
- # 只刻画100个单词
- plot_only = 100
- low_dim_embs = tsne.fit_transform(final_embeddings[1:plot_only+1, :])
- # 标签是单词
- labels = [reverse_dictionary[i] for i in range(1,plot_only+1)]
- plot_embed(low_dim_embs, labels)

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/917303
推荐阅读
相关标签

