
昇思MindSpore技术公开课——第一课:Transformer_mindspore中大语言模型有哪些
赞
踩
1、前言
本系列文章是针对《昇思MindSpore技术公开课》的学习心得和体会,文章产出用于参加【第五届MindCon极客周】。《昇思MindSpore技术公开课》包含了两期大模型专题,共包含十七课。课程结合华为自研机器学习框架昇思MindSpore,课程由浅入深,对想要学习机器学习特别是大模型技术的同学比较友好。建议对大模型的研究充满热情的同学可以观看学习一下。以下分享内容是按照本人对于学习进度的课程记录,仅为个人拙见,供参考。
2、学习总结
2.1LLM技术演变史

2.2语言模型
所有合法句的概率分布,总和为1。
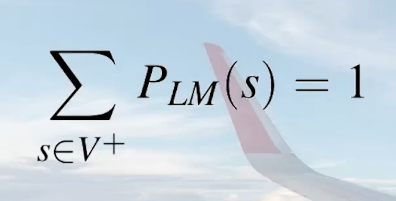
2.3SLM时代
自回归语言模型:Ngram语言模型,最大似然估计,该语言模型引入马尔科夫假设,简化计算方法,但空间仍然很大,实现复杂。。
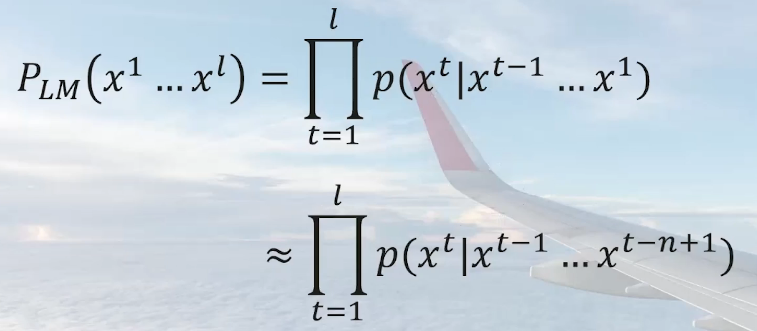
2.4NNLM时代
神经语言模型:词语嵌入向量、神经语言模型、递归神经网络语言模型(RNN)、长短时记忆网络语言模型
极大似然估计方法精度不高,需引入复杂模型, 引入神经网络,使用GPU进行大规模计算。
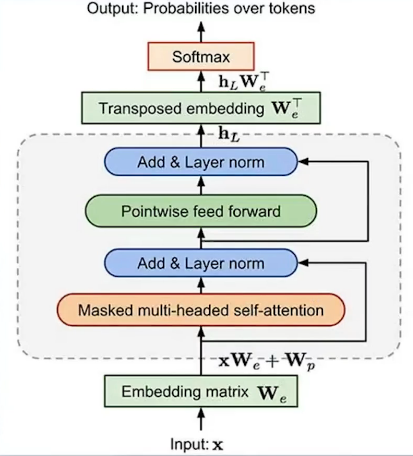
2.5PLM时代
Transformer语言模型

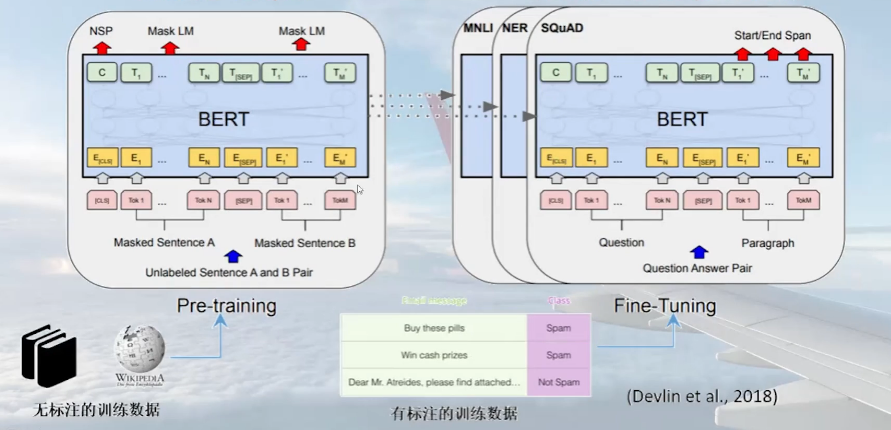
预训练模型模型:预训练+微调
预训练模型在自然语言处理中的应用。预训练模型可以利用大量的语料进行训练,经过微调后可以应用于各种自然语言处理问题,大大提高了性能和简化了流程。
2.6AGI时代
大型语言模型(LLM):随着参数量的提升,模型能够更加精细地捕捉人类语言的微妙之处,更加深入地理解人类语言的复杂性。同时,大语言模型在吸纳新知识、分解复杂任务以及图文对齐等多方面都有显著提升。
3、学习心得
通过深入了解大模型的发展历程,我得以一窥人工智能领域的飞速进步和变革。在这个过程中,我不仅对大模型的技术演进有了更全面的认识,也对未来的发展趋势有了更清晰的展望。
同时,我也意识到了学习大模型演进历史的重要性。通过对历史的回顾,我能够更好地理解当前大模型的局限性和挑战,并思考如何解决这些问题。此外,通过学习大模型的演进历史,我还能从中汲取灵感,为未来的研究和实践提供有益的参考。
回顾整个学习过程,我深感收获颇丰。通过学习大模型的演进历史,我不仅对人工智能领域有了更全面的认识,还培养了自己的研究兴趣和实践能力。我相信这些经验和知识将对我未来的学习和工作产生积极的影响。
4、经验分享
对于学习Transformer模型的经验分享:
- 理解Transformer的基本结构:首先要深入了解Transformer模型的结构和工作原理。了解自注意力机制、位置编码、多头注意力等核心组件的作用和实现方式,这将有助于更好地理解Transformer的工作原理。
- 动手实践:可以尝试使用PyTorch或TensorFlow等深度学习框架来构建和训练Transformer模型。通过实践,可以更好地理解模型的参数、层的数量、维度等如何影响模型的性能。
5、课程反馈
第一节大模型课程着眼基础,老师用通俗易懂的方式,大体介绍了大模型的发展历程,让我对这一领域有了更全面的了解。
课程从最早的统计语言模型说起,讲述了它们如何逐渐发展成为如今的大模型。老师向我们展示了不同时期的重要突破和里程碑,如反向传播算法、卷积神经网络、循环神经网络等。这些技术的发展为大模型的演进奠定了坚实的基础。总之,这次的大模型第一课非常易于理解!适合所有人,包括技术小白。老师用生动的语言和丰富的案例,让我们深刻理解了大模型的发展历程。我强烈推荐这门课程给所有对大模型感兴趣的同学,相信你们一定会受益匪浅!
6、未来展望
我将继续关注大模型领域的最新进展和趋势。我希望能够深入探索大模型在各个领域的应用潜力,为人工智能技术的发展做出自己的贡献。同时,我也将不断学习和实践,提升自己的专业素养和能力水平。相信在不久的将来,我会在大模型领域取得更多的成果和进步。

